
여러분은 오랜 시간 동안 Firebase 도구를 사용하여 푸시 알림부터 인증, Firestore 데이터베이스까지 더 빨리 앱을 구축할 수 있었습니다. 올해의 Google I/O에서 Firestore가 이제 데이터 연결을 통해 SQL을 지원한다는 발표가 있었습니다. 이제 개발자들은 NoSQL과 SQL 중에서 선택할 수 있습니다.
SQL에서는 테이블을 만들기 위한 구조가 정의되어 있습니다. 열과 행을 가진 엑셀 스프레드시트와 유사합니다. 사용자가 새 속성(열)을 추가할 때마다 모든 요소(행)에 해당 속성을 포함해야 합니다. 데이터를 검색하기 위해 SQL 언어를 사용하여 테이블에서 데이터를 가져오거나 다중 열에서 데이터를 결합하거나 데이터베이스를 편집, 삭제, 업데이트할 수 있습니다.
반면에 NoSQL은 JSON 형식으로 모든 유형의 데이터를 추가할 수 있습니다. Firestore에서는 문서와 컬렉션이 있습니다. 문서는 데이터베이스의 개별 객체로 SQL의 행과 해당되며, 컬렉션은 다른 문서를 그룹화하여 SQL의 테이블과 유사합니다. 그러나 컬렉션 내에서는 다른 매개변수가 있는 문서를 가질 수 있습니다. 특정 문서에 hungerMeter를 추가하고 다른 문서에 favoriteDrink를 추가하려면 이렇게 할 수 있습니다.
NoSQL은 데이터를 관리하는 방법에 대해 다르게 생각하도록 격려합니다. 중요한 문제 중 하나는 서로 다른 컬렉션의 문서가 관계를 가지고 있을 때, 우리는 어떻게 그를 관리해야 하는지에 대한 문제입니다. 예를 들어, 프로그래머를 위한 컬렉션이 있고 언어를 위한 컬렉션이 있는 경우에는 어떻게 프로그래머를 favoriteLanguage 필드와 함께 모델링해야 할까요? 우리는 SQL에서와 같이 언어의 ID를 참조해야 할까요, 아니면 언어 컬렉션에서 값을 복사해야 할까요?
이것은 Firestore NoSQL 데이터베이스에서 데이터의 정규화와 비정규화 주변의 주요 논의입니다. 바로 살펴보겠습니다.
Firebase에서 정규화를 사용하는 데 어려움이 있는 이유
장난감 공장의 관리를 용이하게 하는 앱을 만들어야 합니다. 첫 번째 작업은 다음과 같은 디자인을 가진 장난감 제조 목록을 표시하는 간단한 대시보드를 만드는 것입니다.

각 장난감에는 소재를 포함한 여러 속성이 있을 것입니다. 이 속성은 카드 위젯에 표시됩니다. SQL과 유사한 방식으로, 우리는 두 개의 컬렉션을 만듭니다: toys와 materials. 이 컬렉션들의 속성은 다음 다이어그램에 표시되어 있습니다.
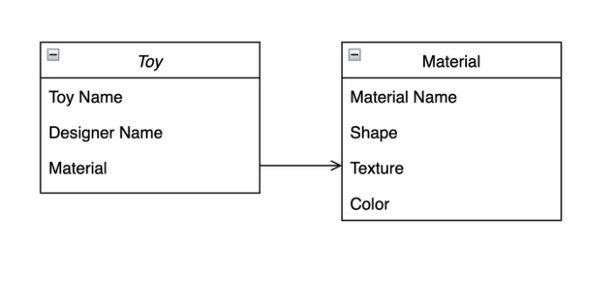
SQL에서는 외래 키를 사용하여 테이블 간의 관계를 생성합니다. 그러나 Firestore에는 외래 키가 없습니다. 대신 DocumentReference를 사용할 수 있습니다. DocumentReference는 다른 문서를 참조하는 데 사용할 수 있는 값 타입입니다.
이젠 모든 장난감을 나열하고 싶으면 어떻게 될까요?
장난감 컬렉션에서 모든 문서를 가져오면, 소재에 대한 정보가 없을 것이고 DocumentReference 목록만 있을 겁니다. 해당 정보를 검색하려면 각 레퍼런스별로 get을 사용하고 그 정보를 사용하여 Card UI를 만들기 위해 장난감 객체를 생성해야 합니다.
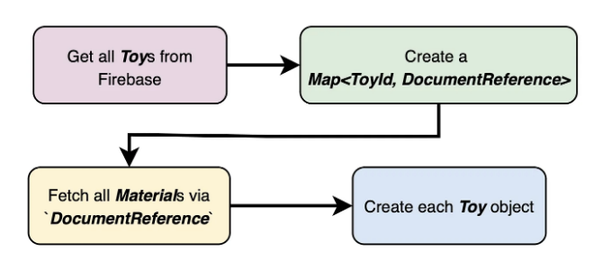
만약 공장에 1,000종류의 장난감이 있다면, Firebase에서 1,001번의 읽기가 필요할 수 있습니다: 장난감 컬렉션에서 모든 문서를 검색하고, 각 DocumentReference를 읽기 위해 한 번씩이요.
또한, 모든 쿼리 로직 및 데이터 병합이 클라이언트 앱에서 이루어지기 때문에, 다음 코드 스니펫에서 보여지는 것처럼 더 복잡한 클라이언트 측 코드를 가질 수 있습니다:
Future<List<Toy>> fetchToysAndMaterials() async {
final firestore = FirebaseFirestore.instance;
// 단계 1: 모든 장난감 가져오기
final toySnapshot = await firestore.collection('toys').get();
final toyDocs = toySnapshot.docs;
// 단계 2: 장난감 ID와 재료 문서 레퍼런스 맵 생성
final toyToMaterialReference = <String, DocumentReference>{};
final toyToMaterial = <String, Material>{};
for (final doc in toyDocs) {
toyToMaterialReference[doc.id] = doc["material"] as DocumentReference;
}
// 단계 3: 재료를 위한 일괄 읽기
for (final key in toyToMaterialReference.keys) {
final materialSnapshot = await toyToMaterialReference[key]!.get();
toyToMaterial[key] = Material.fromFirebase(materialSnapshot);
}
// 단계 4: 재료 정보를 포함한 Toy 객체 생성
final toys = toyDocs.map((doc) {
Material material = toyToMaterial[doc.id];
return Toy.fromFirebase(doc, material);
}).toList();
return toys;
}
여러 장난감이 동일한 재료를 가질 수 있는지 확인하기 위해 코드를 개선할 수 있습니다. 이를 위해 MapToy, Material을 MapMaterial, ListToy`로 변경할 수 있습니다. 또한 문서를 수정하여 특정 ID를 노출시킨 후 whereIn 조건으로 where 연산자를 사용하는 쿼리를 만들 수 있습니다. 그러나 whereIn은 검색할 수 있는 문서 수에 제한이 있습니다. Firebase 레퍼런스 문서에 명시되어 있듯이, 이는 페이지네이션을 다뤄야 함을 의미합니다.
그러므로, 쿼리를 최적화할 간편한 옵션을 찾을 수 없지만, Firebase에서 재미있는 무료 티어를 제공하기 때문에 우리 솔루션이 요구하는 읽기 작업 수에 대해 어느 정도 타협할 수 있습니다.
그러나 어느 날 우리 매니저가 들어와서, 그녀가 우리에게 Card 위젯에서 Toy의 Color도 출력하라는 작업을 부여합니다.
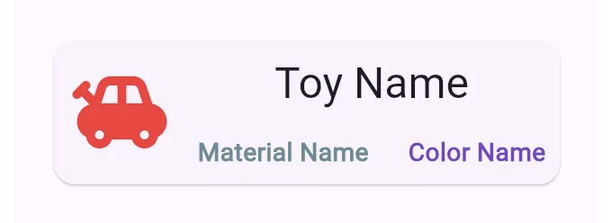
같은 방식을 따라, 우리는 colors라는 새로운 컬렉션을 만들어 이제 다음과 같은 데이터베이스 다이어그램을 가지게 되었습니다:

Toy 객체를 만들어 이 카드 위젯을 구축하기 위해 자료 및 색상 컬렉션으로부터 DocumentReference를 모두 검색하고 적절한 맵을 만들어 그들 간의 관계를 캐시해야 합니다.
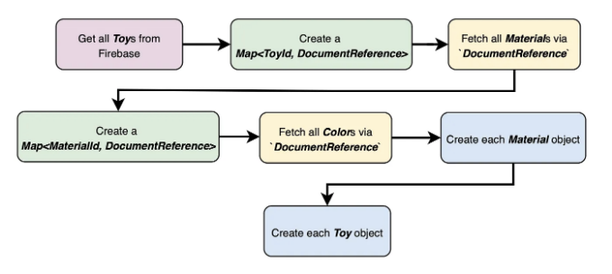
1,000개의 Toy 목록에 대한 읽기 작업에 대해, 최악의 경우, 모든 Toy 문서를 검색하기 위해 1번 읽기, 자료 문서를 1,000번 읽기, 색상 문서를 1,000번 읽기 해야 하며, 이로 인해 목록 하나를 만들기 위해 2,001번 읽기를 수행해야 합니다. 현재 기록된 시간에 따르면 하루에 무료로 50,000회 읽기가 가능한데, 이 목록이 하루에 25회 검색되면 이 한도가 달성되어 나머지 시간에는 각 새로고침마다 비용을 지불해야 합니다.
우리는 "사용자에게 1,000개의 항목을 절대로 표시하지 않을 것이며, 항상 무한한 페이지로 나눠진 목록을 사용할 것이다." 라고 이를 정당화할 수 있을지 모르지만, 여전히 남아있는 문제점이 있습니다: 필터링.
특정 색상을 가진 모든 장난감을 검색하려면 객체를 검색할 때 정반대 과정을 수행해야 합니다. 쿼리와 일치하는 모든 색상을 찾은 다음 해당 색상을 포함하는 모든 재료를 찾고, 마지막으로 해당 재료를 가진 모든 장난감을 찾아야 합니다.
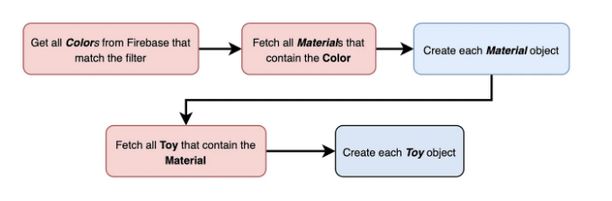
게다가, 특정 색상 및 재료 속성으로 필터링하려면 각 사용 사례에 맞게 필터링 방법을 변경해야 합니다.
마지막으로, 가장 중요한 것은 응용 프로그램에 다양한 유형의 사용자가 있다면 재료와 색상의 특정 속성에 액세스할 수 없도록하려는 경우가 있을 수 있지만, 이름과 유형에는 액세스 권한을 허용하려는 경우입니다. Firestore에서 문서의 일부만 검색하는 것은 불가능합니다. 항상 문서의 모든 정보를 검색해야 합니다.
요약하자면, NoSQL Firestore에 SQL과 유사한 접근 방식을 적용하면 세 가지 문제가 발생합니다:
- 조금 더 많은 읽기 작업이 발생할 수 있음;
- 복잡한 필터링;
- 문서 내 모든 정보 노출, 포함하여 민감한 정보까지.
그 대신에 우리가 할 수 있는 것은 무엇인가요?
Firestore 데이터의 정규화 해제
우리의 원래 문제에서는 사용자에게 재료 이름과 색상 이름이 나와있는 카드를 보여주고 싶었습니다. 이 쿼리는 자주 수행할 것으로 예상되므로 데이터를 결합하는 것이 어떨까요? 이것이 바로 비정규화의 개념입니다 - 데이터를 모델링하기 위해 서로 다른 테이블/컬렉션에서 필드를 복사하여 하나의 객체로 만들어 정보를 검색하고 필터링하기 쉽게 하는 전략입니다.
그 질문은 - 장난감에 Material 및 Color에서 어떤 데이터를 추가해야 할까요? 답은 우리가 보여주고 싶은 것이나 수행하려는 작업에 따라 다릅니다. 따라서 UI를 검토해봅시다.
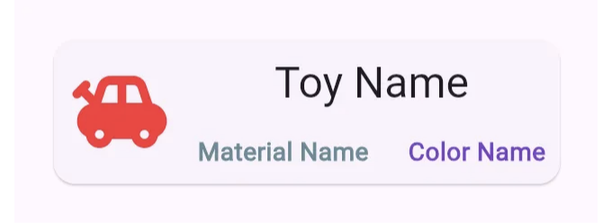
이 시점에서는 사용자에게 자세한 내용이 없이 다른 카드를 보여주기만 하면 되므로, Color와 Material 이름만을 보여줍니다. 그래서 우리는 Toy 문서에 두 속성을 모두 추가할 수 있습니다. 여전히 DocumentReference를 유지하거나, 원한다면 ID를 사용하여 신속하게 이름을 식별할 수 있습니다.
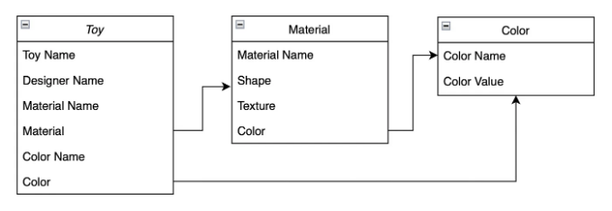
이제 1,000개 요소로 구성된 목록을 표시하려면, 이 카드를 구성하는 데 필요한 모든 데이터를 가져오기 위해 Firestore에서 하나의 읽기만 필요합니다. 이는 Flutter에서 클라이언트 측 코드를 간단하게 만들어줍니다:
Future<List<Toy>> fetchToysAndMaterials() async {
final firestore = FirebaseFirestore.instance;
// 1단계: 모든 장난감 가져오기
final toySnapshot = await firestore.collection('toys').get();
final toyDocs = toySnapshot.docs;
// 2단계: [Toy] 클래스로 매핑
return toyDocs.map((doc) => Toy.fromFirebase(doc)).toList();
}
Color 및 Material에서 추가해야 할 다른 속성이 있습니까? 이는 두 가지 질문에 달려 있습니다:
- 만약 Toy에 대한 상세보기를 보여주면, 모든 공통 속성을 추가하고 싶을 수 있습니다.
- 소재 모양이나 색상 값과 같은 특정 속성을 필터링하는 경우, Toy 문서에 추가하는 것을 고려할 수 있습니다.
우리는 이제 애플리케이션의 요구사항을 고려하여 적절한 문서 구조를 작성하여 앱이 이 데이터를 쉽게 소비할 수 있도록 하려고 합니다.
이로 인해 중요한 문제가 발생합니다: 만약 어느 날 소재 이름이 변경된다면 어떻게 될까요? Toy에서 해당 속성을 어떻게 업데이트할까요? 이것은 비정규화된 데이터베이스를 사용하는 것의 단점 중 하나입니다. 그러나 우리에게 해결책이 있습니다.
Firebase Functions을 사용하여 데이터 업데이트하기
한 가지 해결책은 클라이언트 애플리케이션을 사용하여 모든 데이터베이스 업데이트를 관리하는 것입니다. 사용자가 Material 객체를 변경하면 모든 Toys도 업데이트됩니다. 그러나 이로 인해 문제가 발생합니다:
- Material을 관리하는 사용자가 Toy 컬렉션에 대한 충분한 권한을 갖고 있지 않을 수 있기 때문에 해당에 대한 사용자 지정 규칙을 만들어야 합니다.
이 문제에 대한 해결책으로는 Firebase Cloud Functions을 사용하는 것입니다. 클라이언트 앱이 민감한 정보에 액세스하지 못하도록 막고 싶을 때 Firebase Cloud Functions을 사용하여 이러한 작업을 클라우드에서 실행할 수 있습니다. Firebase Functions은 클라이언트 애플리케이션에서 호출할 수 있는 API 형식의 엔드포인트를 제공하며 컬렉션 내의 문서 변경과 같은 변경에 반응할 수 있는 기능을 제공합니다.
Toy 애플리케이션의 경우 materialscollection 내의 문서 변경에 반응하고 해당 Material을 사용하는 모든 Toy를 찾아 필요한 속성을 업데이트하는 새로운 Firebase Function을 작성해야 합니다.
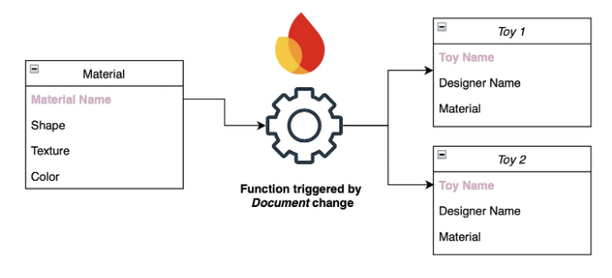
이 글에서는 Firebase Functions 프로젝트를 생성하는 방법에 대해 다루지 않겠습니다. 시작 안내서에 문서화된 내용입니다. 바로 Python 코드로 넘어가겠습니다.
먼저, on_document_updated 주석이 달린 새 함수를 만듭니다. 이를 통해 변경 사항을 감시하는 컬렉션을 명시할 수 있습니다. 이 함수는 이전 및 현재 문서 상태를 볼 수 있도록 Event[Change[DocumentSnapshot]]를 받습니다.
from firebase_functions.firestore_fn import (
on_document_updated,
Event,
Change,
DocumentSnapshot,
)
from firebase_admin import initialize_app, credentials, firestore
cred = credentials.Certificate("credentials/service_account.json")
app = initialize_app(cred)
db = firestore.client()
@on_document_updated(document="/materials/{materialId}")
def on_toy_material_update(event: Event[Change[DocumentSnapshot]]) -> None:
# 할 일: 구현하기
다음으로, 변경 내용을 찾아보겠습니다. 예를 들어, 이름과 같은 필드로:
@on_document_updated(document="/materials/{materialId}")
def on_toy_material_update(event: Event[Change[DocumentSnapshot]]) -> None:
# 새 문서 스냅샷에서 업데이트된 데이터를 추출합니다.
new_data = event.data.after.to_dict()
old_data = event.data.before.to_dict()
# 업데이트를 보관할 딕셔너리를 만듭니다 (변경 사항이 있는 경우에만)
updates = {}
if new_data.get("name") != old_data.get("name"):
updates["materialName"] = new_data.get("name")
이제 재료 ID를 사용하여 장난감 컬렉션을 살펴보고,이 재료를 사용하는 모든 장난감을 찾기 위해 쿼리하고 업데이트 함수를 사용하여 업데이트합니다.
@on_document_updated(document="/materials/{materialId}")
def on_toy_material_update(event: Event[Change[DocumentSnapshot]]) -> None:
"""
특정 재료를 사용하는 장난감을 업데이트하는 함수.
Args:
event (Event[Change[DocumentSnapshot]]): 재료 업데이트로 트리거되는 이벤트.
Returns:
None
"""
# 새 문서 스냅샷에서 업데이트된 데이터를 추출합니다.
new_data = event.data.after.to_dict()
old_data = event.data.before.to_dict()
# 업데이트를 보관할 딕셔너리를 만듭니다 (변경 사항이 있는 경우에만)
updates = {}
if new_data.get("name") != old_data.get("name"):
updates["materialName"] = new_data.get("name")
material_id = event.data.after.id
# 업데이트해야 할 필드가 있는지 확인합니다
if updates:
# 장난감 컬렉션에서이 재료를 사용하는 모든 장난감을 쿼리합니다
toys_ref = db.collection("toy").where("materialId", "==", material_id)
toys = toys_ref.get()
# 필요한 경우 각 장난감 문서를 업데이트합니다
for toy in toys:
toy_ref = db.collection("toy").document(toy.id)
toy_ref.update(updates)
print(f"새 재료 데이터로 장난감이 업데이트되었습니다: {updates}")
else:
print("재료 속성이 변경되지 않았습니다. 업데이트가 수행되지 않았습니다.")
업데이트 변수에 딕셔너리를 사용하면 더 많은 필드를 업데이트하고 싶을 때 추가 속성 변경을 더 확인할 수 있어요.
이제 Firebase를 통해 함수를 업로드할 수 있어요:
firebase deploy --only functions
업로드하고 나면 Firebase 콘솔에서 확인할 수 있어요.
You can test it by directly editing the Firestore values in the console:
To debug, go to Log Explorer in the Google Cloud Console. Here, you can find all logs for our app, including the print statements added in our Function.
결론
프로젝트가 성장함에 따라 사이드 이펙트를 관리하기 위해 추가적인 Firebase 함수를 생성해야 할 것입니다. 색상 컬렉션을 변경하면 해당 변경 사항을 소재 및 장난감에 전파해야 할 필요가 있습니다. 주문 컬렉션에서 주문을 처리할 때 소재와 장난감의 재고를 확인하고 주문을 처리하기 전에 필요한 항목을 재고에서 빼야 할 수도 있습니다.
이러한 사이드 이펙트는 비정규화된 데이터베이스를 사용함으로 인한 결과입니다. 앱의 기능을 중심으로 데이터를 모델링한다면 SQL과 유사한 구조 대신 데이터베이스를 동기화하는 방법이 필요합니다. Firebase Functions를 활용함으로써 데이터베이스를 클라이언트 애플리케이션으로부터 격리시키고 민감한 데이터를 안전하게 보호하며 무단 수정을 방지할 수 있습니다.
이 문서를 통해 Firestore 데이터베이스에서 데이터 정규화 및 비정규화를 탐구해보았습니다:
- 정규화된 데이터는 데이터 무결성을 보장하지만 더 많은 읽기와 복잡한 쿼리로 이어질 수 있습니다.
- 비정규화된 데이터는 데이터베이스를 앱의 요구에 따라 모델링하여 클라이언트 앱의 필터링 및 가져오기 작업을 간소화하지만 데이터 무결성을 유지하기 위해 Firebase Functions를 통한 추가적인 코드가 필요합니다.
어떤 경우에 이름 변경과 같은 절대 변경 사항이 전파되지 않을 수 있지만, 제품의 재고와 같이 값의 증가 또는 감소와 같은 경우가 있습니다. 이 경우 트랜잭션을 사용하여 한 문서의 값을 읽고 다른 문서에서 변경 사항을 처리할 수 있습니다. Firebase가 읽은 문서에서 변경 사항을 감지하면 트랜잭션을 다시 시도하여 가장 최신 데이터를 사용할 수 있도록 보장합니다.
추가로 Firebase Function에서 데이터 유효성 검사를 하도록 노력해야 합니다. 이를 통해 사용자가 예를 들어 문자열에서 불리언으로 값을 변경하거나 특정 규칙을 따르도록 강제할 수 없게 됩니다. Firebase Function이 오류를 감지하면 변경 사항을 전파 중지하고 재료 문서를 원래 상태로 수정할 수 있습니다.
마지막으로, 무단 액세스나 정보 수정을 방지하기 위해 적절한 Firestore 규칙이 설정되어 있는지 확인해야 합니다. 이를 통해 Firebase 함수만이 이를 수행할 수 있도록 합니다.
Firebase 앱에 원활하게 더 많은 기능을 추가하고 싶다면 Firebase Extensions를 사용해보는 것은 어떨까요? Firebase Extensions를 활용하여 AI 요약 기능을 쉽게 추가할 수 있는 방법을 확인하려면 이 문서를 참고해보세요.