
크레딧: Nguyễn Thành Minh (안드로이드 개발자)
Part 1은 여기에서 확인하세요: Quantifiers
Part 2은 여기에서 확인하세요: Flavors, Flags, and Assertions
아래의 테이블 태그를 마크다운 형식으로 변경해주세요.
룩어헤드 어설션은 특정 문자로 뒤따라오거나 선행하는 경우에만 일치하는 비캡처 그룹입니다.
룩어헤드 어설션은 입력 문자열이나 텍스트의 문자를 소비하지 않습니다. 다른 어설션 메타 문자인 입력 경계 어설션 (^와 $) 및 단어 경계 어설션 (\b와 \B)과 달리.
룩어헤드 어설션에는 두 가지 유형이 있습니다: 앞봐기(lookahead)와 뒷봐기(lookbehind). 두 유형은 양수와 음수 형태로 나뉘며, 양수 앞봐기, 음수 앞봐기, 양수 뒷봐기 및 음수 뒷봐기 어설션이 있습니다.
- 양수 앞봐기(?=chars)
프렌들리한 톤으로 번역해드리겠습니다. 😀
긍정형 선행 단언은 문자열에서 현재 위치 이후에 특정 패턴이 일치하는지를 확인하며 해당 문자열에서 문자를 소비하지 않습니다. 간단히 말하면, 특정 표현식이 현재 위치 오른쪽에 위치하는지를 확인합니다. 이는 다음과 같은 구문을 사용하여 나타냅니다:
(?=chars)
예를 들어, 패턴 x(?=y)는 y가 뒤따라오는 경우에만 x와 일치합니다.
[이미지:RegexforDummiesPart5LookaroundAssertionsLookaheadsandLookbehinds_1.png]
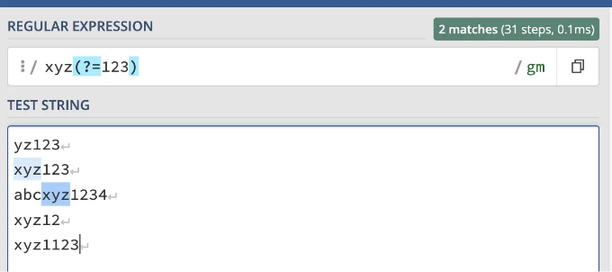
다른 예시로, xyz(?=123)는 xyz와 일치하는 것이 123로 뒤 따르는 경우에만 일치합니다.
또 다른 예시로, apple (?=pie)
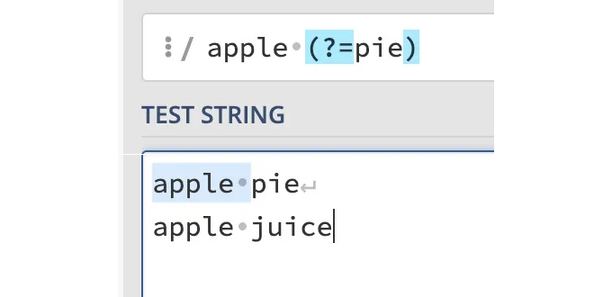
위 예제에서, 'apple'과 일치하는 부분은 있지만 'apple pie' 전체까지는 일치하지 않습니다. 왜냐하면 lookaround 어서션은 입력 문자열의 문자들을 소비하지 않기 때문입니다.
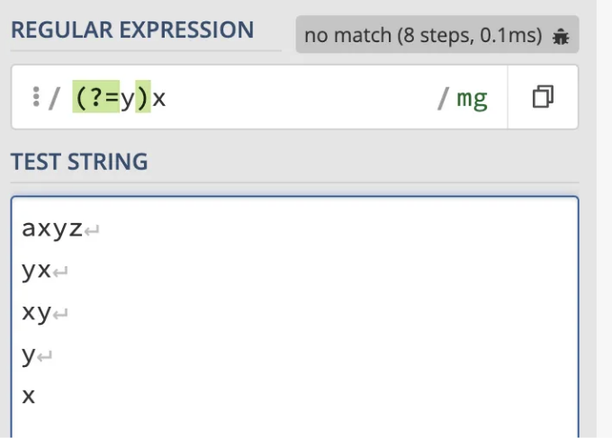
만약 x(?=y)를 (?=y)x로 바꾼다면 어떻게 될까요? 패턴 (?=y)x를 이해하기 위해서는 먼저 패턴 (?=y)와 (?=y)y를 이해해야 합니다.
패턴 (?=y)는 'y'가 뒤따라오는 문자열과 일치하지만, 그 앞에는 다른 문자열이 없는 경우를 의미합니다. 따라서 아래 이미지에서 볼 수 있듯이 "빈 문자열"과 일치하게 됩니다. 이 경우 빈 문자열 중에서 'y'가 뒤따라오는 것에만 일치하며, 모든 빈 문자열과는 일치하지 않음에 유의해 주세요.
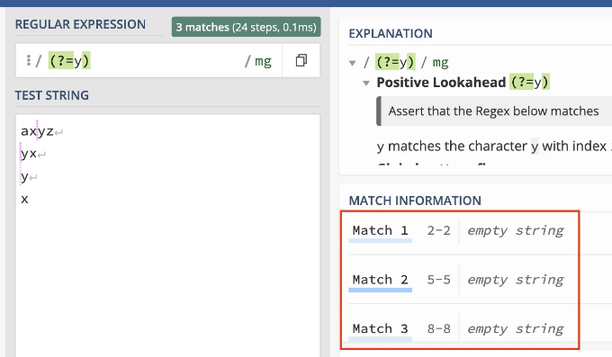
The pattern (?=y)은 ‘y’ 바로 앞에 오는 빈 문자열과 일치합니다. 그래서, 패턴 (?=y)y는 ‘y’ 앞의 빈 문자열과 바로 ‘y’ 문자 뒤에 옵니다. 보다 쉬운 용어로 표현하자면, 이는 단순히 문자 ‘y’에 해당합니다.
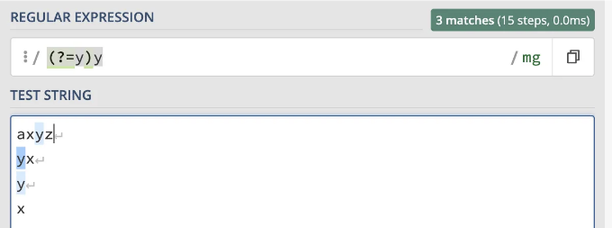
비슷하게, 패턴 (?=y)x는 ‘y’ 앞에 오는 빈 문자열과 바로 ‘x’ 문자 뒤에 오는 것을 나타냅니다. 다시 말해, 이는 'x' 문자 하나로만 구성되어야 하지만 'y'로 시작해야 하는 문자열과 일치합니다. 이러한 시나리오는 불가능하기 때문에, 이 패턴은 어떤 문자열과도 일치하지 않습니다.
만약 우리가 (?=y)x와 같은 패턴에 .*을 삽입한다면 어떻게 될까요? (?=.*y)x가 되는데, 이 경우 'x'가 'xy', 'x123y', 'x1y2z3'와 같이 'y'가 뒤에 오는 경우에 일치합니다.
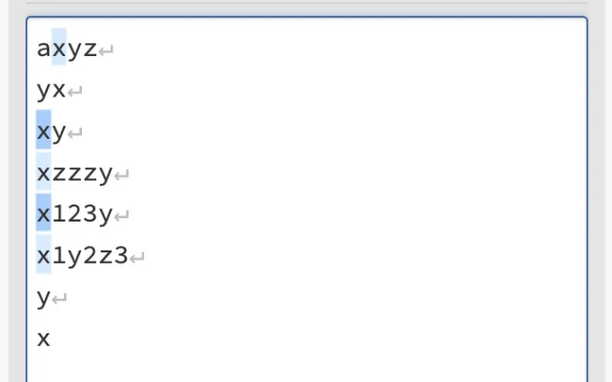
먼저, 이 패턴이 단 한 문자 'x'만 일치한다는 점은 확실합니다. 왜냐하면 (?=.*y)는 단언이기 때문에 문자를 소비하지 않기 때문입니다.
그런 다음, 패턴 (?=.*y)가 어떻게 작동하는지 이해해야 합니다.
- .*: 새 줄 제외한 모든 문자 시퀀스와 일치합니다.
- y: 문자
y와 일치합니다. - 따라서, .*y는 적어도 하나의 문자
y를 포함하는 모든 문자열과 일치합니다.
그러므로, (?=.*y)는 'y'가 뒤따르는 빈 문자열과 일치합니다.
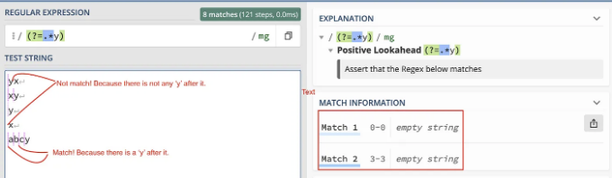
마지막으로, 패턴 (?=.*y)x는 'y'가 뒤따르는 문자열(예: xy,, x123y,, x1y2 등)에서 단일 문자 x와 일치합니다.
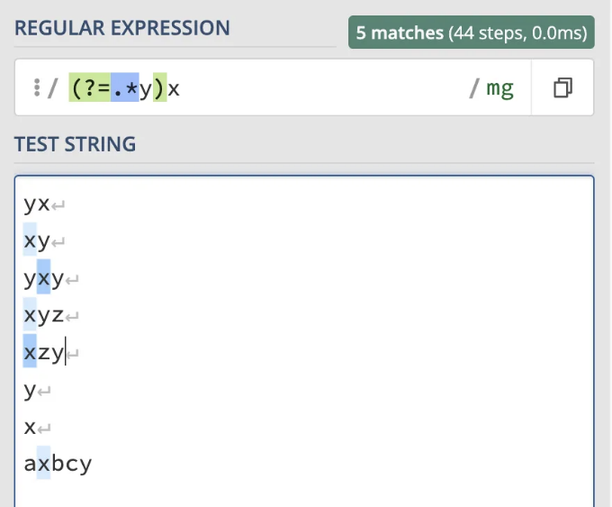
이 경우에는 .*가 ‘x’와 일치하기 때문에 .*y 전체가 ‘xy’와 일치하지만 ‘yx’와는 일치하지 않습니다. 그래서 (?=.y)x는 ‘yx’와 일치하지 않습니다. 이를 그룹화하여 확인할 수 있습니다: (?=(.)y)x
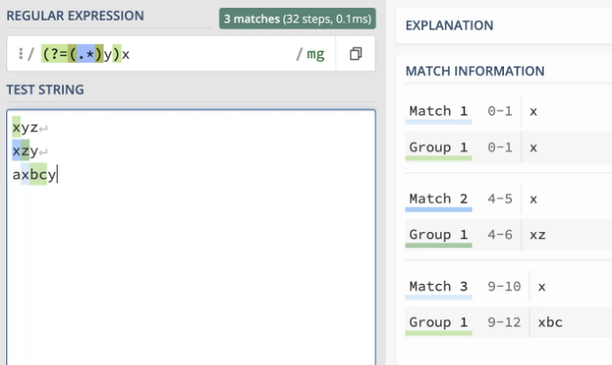
그룹 (.*)는 ‘x’, ‘xz’, ‘xbc’와 일치하는 것을 볼 수 있습니다.
간단히 말해서, (?=.*y)는 문자열에 적어도 하나의 'y' 문자가 있는지 확인하는 데 일반적으로 사용됩니다. 비슷하게, 다음과 같은 유용한 패턴들이 있습니다:
- (?=.*[a-z]).+는 적어도 하나의 소문자가 있는 문자열과 일치합니다.
- (?=.*[A-Z]).+는 적어도 하나의 대문자가 있는 문자열과 일치합니다.
- (?=.*\d).+는 적어도 하나의 숫자가 있는 문자열과 일치합니다.
- (?=.*[^A-Za-z0–9\s]).+는 공백을 제외한 특수 문자가 적어도 하나 있는 문자열과 일치합니다.
긍정적인 선행 단언은 비밀번호 유효성을 확인하는 데 유용할 수 있습니다. 예를 들어, 적어도 하나의 대문자, 소문자, 숫자, 및 (공백을 제외한) 하나의 특수 문자를 포함하는 8자 이상의 비밀번호를 확인하려면 다음과 같이 할 수 있습니다:
^(?=.*[A-Z])(?=.*[a-z])(?=.*\d)(?=.*[^A-Za-z0-9\s]).{8,}$
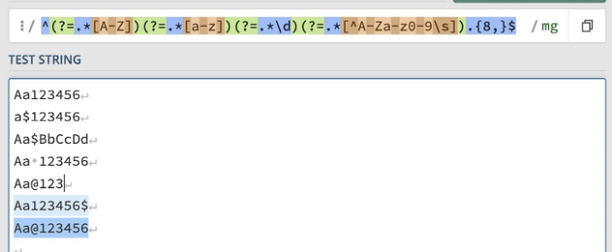
여기서:
- ^: 패턴을 문자열의 시작으로 고정시킵니다.
- (?=.*[A-Z]): 적어도 하나의 대문자가 존재하는 것을 보증합니다.
- (?=.*[a-z]): 적어도 하나의 소문자가 존재하는 것을 보증합니다.
- (?=.*\d): 적어도 하나의 숫자가 존재하는 것을 보증합니다.
- (?=.*[^A-Za-z0-9\s]): 적어도 하나의 특수문자(공백 제외)가 존재하는 것을 보증합니다.
- .'8,': 적어도 8자의 문자열과 일치합니다.
- $: 패턴을 문자열의 끝으로 고정시킵니다.
- 부정형 순방향탐색 (?!chars)
부정적 룩어헤드 구문에서는 등호를 느낌표로 바꿉니다:
(?!chars)
예를 들어, x(?!y) 패턴은 'y'에 뒤이어 나오지 않는 경우에만 'x'와 일치합니다.
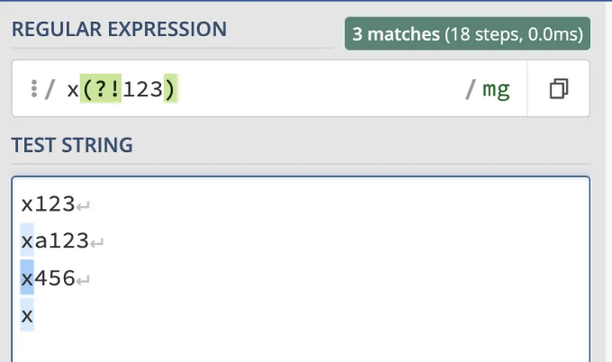
다른 예로는 x(?!123) 패턴으로, '123'에 뒤이어 나오지 않는 경우에만 'x'와 일치합니다.
부정적 전방탐색 어설션은 특정 단어로 시작하지 않는 문자열을 유효성 검사하는 데 유용할 수 있습니다. 예를 들어, 'http' 또는 'https'로 시작하지 않는 URL을 유효성 검사하는 것입니다.
^(?!http|https).+$
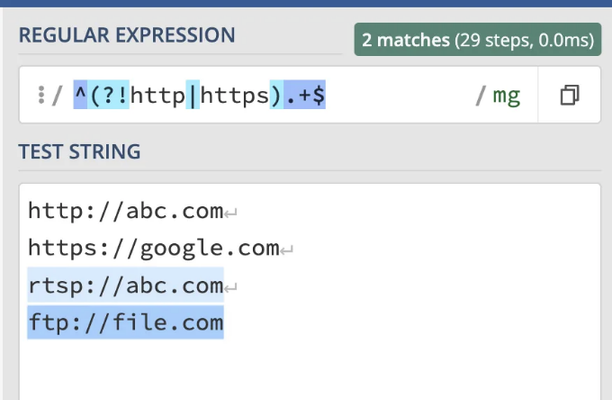
위의 패턴에서, ^는 현재 위치가 문자열의 시작임을 나타내며, 부정 후조형 (?!http|https)는 현재 위치 뒤의 문자열이 "http" 또는 "https"가 아님을 나타냅니다. 이는 "http" 또는 "https"로 시작하지 않는 문자열과 일치합니다.
- 긍정 후조형 (?`=chars)
후조형 단언은 후조 단언과 유사합니다. 하지만 일치하려는 항목 뒤에 무엇이 따라오는지 확인하는 대신, 일치하려는 항목 앞에 어떤 문자(들)가 있는지 확인합니다.
후조 단언과 마찬가지로, 긍정과 부정 후조 단언도 있습니다. 긍정 후조는 패턴에서 지정한 다른 문자에 의해 선행된 문자만 일치시킵니다. 반면에 부정 후조는 일치시키려는 문자가 다른 문자에 의해 선행되지 않을 때만 일치시킵니다.
이것은 긍정형 lookbehind의 구문입니다:
(?<=chars)
예를 들어, 패턴 (?`=x)y는 y를 일치시키려면 그 앞에 x가 있어야 한다는 것을 나타냅니다. 이 경우 xx 또는 yx는 일치하지 않지만 xy는 일치합니다.
긍정형 lookbehind 어설션은 특정 통화 기호로만 선행된 숫자와 일치하는 경우에 유용할 수 있습니다. 예를 들어, 달러 기호로 선행된 숫자와 일치하는 경우입니다.
아래의 정규 표현식 패턴은 달러 기호가 앞에 오는 숫자만 일치시키는 양수형 룩비하인드를 갖고 있어요:
(?<=\$)\d+
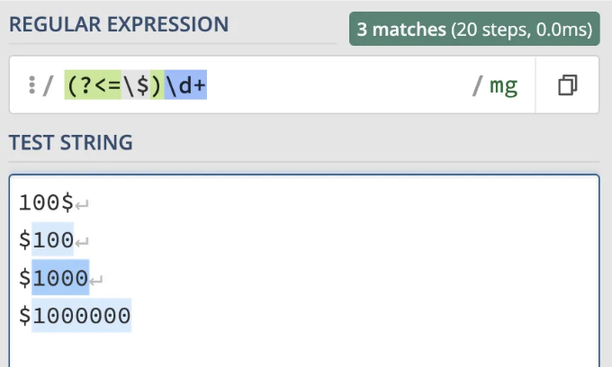
위 패턴에서 양수형 룩비하인드인 (?`=$) 는 달러 기호인 '$' 가 \d+에 의해 표현되는 하나 이상의 숫자 앞에 있는지를 확인합니다.
- Negative lookbehind (?`!chars)
부정적인 lookbehind에서는 등호 대신 느낌표를 사용합니다:
(?<!chars)
예를 들어, 패턴 (?`!x)y는 y 앞에 x가 있는 경우 y와 일치하지 않습니다. 이 경우 vy는 일치하고, ny는 일치하지만 xy는 결코 일치하지 않습니다.
부정적인 전방탐색 단언은 특정 확장자로 끝나지 않는 파일을 유효성 검사할 때 유용할 수 있습니다. 예를 들어, "js", "css", 또는 "html"로 끝나지 않는 파일 경로를 유효성 검사하려면 아래와 같이 사용할 수 있습니다.
^.+(?<!js|css|html)$
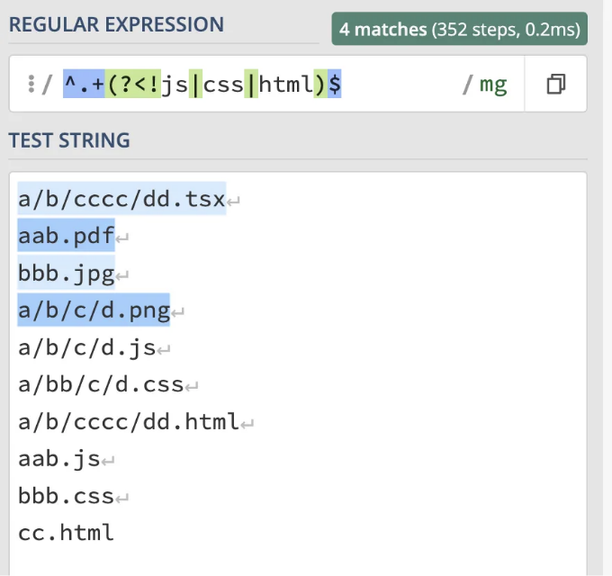
위 패턴에서 $는 현재 위치가 문자열 끝을 나타내고, 부정적인 전방탐색 (?`!js|css|html)는 현재 위치(끝 위치) 앞에 있는 문자열이 "js", "css", 또는 "html"이 아님을 나타냅니다. 즉, "js", "css", "html"로 끝나지 않는 문자열과 일치합니다.
결론
정규 표현식에서 이 개념이 제일 어려웠어요. 이번 레슨 이후에는 대부분의 문제를 해결하는 데 정규 표현식을 사용할 수 있을 것으로 믿어요. 다음 파트에서는 프로그래밍에 적용해볼 거에요.