MySQL의 트랜잭션 메커니즘에 대해 깊이 있게 탐구해 보세요. 여기서는 트랜잭션 처리의 전반적인 탐구를 통해 효율적이고 안전한 데이터 관리를 이끄는 기본 원칙을 알아봅니다.
![]()
MySQL의 강력한 트랜잭션 지원을 탐구하면서, 동시성 안전성 이슈에 대해 복잡하게 살펴보게 됩니다. 동시에 동일한 데이터를 수정하려는 동시 트랜잭션들이 가져다주는 도전에 대처하기 위한 해결책을 MySQL가 선도적인 디자인을 통해 제공합니다.
MySQL는 데이터 불일치를 방지하고 무결성을 유지하기 위한 솔루션을 제공하여 데이터 일관성을 유지하는 논리적인 방법을 보장합니다.
MySQL은 Multi-Version Concurrency Control(MVCC) 시스템, 트랜잭션 격리 메커니즘 및 잠금 메커니즘을 통해 트랜잭션 동시성을 효과적으로 처리하는 등의 과제에 대응합니다.
그 말인즉, 데이터베이스에서 동시 트랜잭션이 통제되지 않고 관리되지 않는다면 잠재적인 결과를 고려해 보신 적이 있나요?
Dirty data.
Dirty data에 관련된 구체적인 개념은 dirty write, dirty read, non-repeatable read, phantom read로, 이들 개념의 의미에 대해 자세히 살펴봅시다.
1. Dirty write.
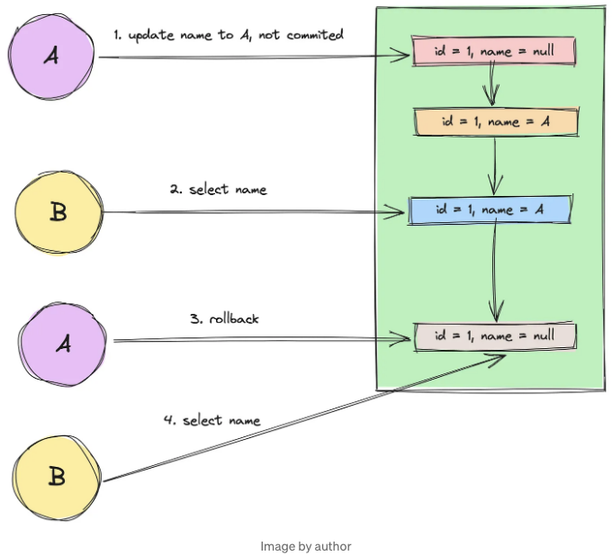
Dirty write은 이미 커밋된 데이터를 수정하는 한 트랜잭션이 있고, 그 수정 사항이 후속 트랜잭션이 롤백하는 상황을 가리킵니다.
먼저 개념을 확인해봅시다: 두 트랜잭션 A와 B가 있다고 가정해보겠습니다. 트랜잭션 A가 먼저 시작되고 id가 1인 레코드를 수정하여 이름을 A로 변경합니다(원래 null이었다고 가정). 하지만 이 시점에서 트랜잭션 A는 아직 커밋되지 않은 상태입니다.
이제 트랜잭션 B가 시작됩니다.
Transaction B는 레코드 ID 1의 이름을 B로 변경하고 해당 트랜잭션을 커밋했습니다. 그러나 이 시점에서 트랜잭션 A는 수정을 진행하지 않기로 결정하고 롤백하여 자체 변경 사항을 되돌립니다.
결과적으로, 레코드 ID 1은 이름에 대한 null 값을 유지하게 됩니다.
이후 트랜잭션 B가 이 레코드를 조회하여 이름 값이 null임을 발견하면, 이는 트랜잭션 B가 수행한 수정 사항이 트랜잭션 A에 의해 롤백되는 경우로, 더러운 쓰기로 간주됩니다.
![]()
MySQL은 락(lock)을 사용하여 dirty writes 문제에 대처합니다. MySQL에서 트랜잭션이 시작되면 특정 레코드에 바인딩됩니다.
이 메커니즘은 Java Virtual Machine (JVM)에서의 락과 다소 유사합니다. 이 맥락에서, 트랜잭션 A가 시작되고 특정 레코드와 연관시킨다면, 트랜잭션 B가 동일한 레코드에 작업을 시도하면 대기해야 합니다.
트랜잭션 A가 실행을 완료하면, 대기 중인 트랜잭션들에게 알리고, 대기 중인 다음 트랜잭션이 작업을 계속할 수 있도록 허용합니다.
이러한 작업들이 직렬화된 실행을 유발하여 데이터베이스가 느리게 처리될 것이 걱정될 수 있습니다. 그러나 실제로는 이러한 작업들이 메모리 내에서, 구체적으로는 버퍼 풀(Buffer Pool) 내에서 처리됩니다. 결과적으로, 이러한 작업의 속도는 매우 빠릅니다.
2. Dirty read.
Dirty read(더티 리드)는 한 트랜잭션이 다른 트랜잭션이 수정했지만 아직 커밋하지 않은 레코드를 읽는 상황을 가리킵니다.
두 개의 트랜잭션, A와 B를 전제로 계속해 보겠습니다. 먼저 트랜잭션 A가 시작되어 id가 1인 레코드의 이름을 A로 변경했지만 아직 커밋하지 않은 상태입니다.
이 시점에서 트랜잭션 B가 시작됩니다. 트랜잭션 B는 쿼리를 실행하고 이름의 현재 값을 A로 찾습니다. 이후에는 해당 값을 A로 가정하고 로직을 진행합니다. 그러나 트랜잭션 A가 롤백되고 나서 트랜잭션 B가 다시 쿼리하면 레코드의 값이 A가 아닌 것을 발견합니다. 이 시나리오는 더티 리드를 잘 보여주는 예시입니다.
3. Non-repeatable read.
Non-repeatable read refers to a situation where reading the same record at different points in time yields different results.
Consider three transactions, T1, T2, and T3.
T1 트랜잭션이 시작되지만 어떠한 작업도 수행하지 않습니다. T2 트랜잭션이 시작되고 id가 1인 레코드의 이름을 B로 변경한 뒤 트랜잭션을 커밋합니다.
이 시점에서 T1 트랜잭션이 활성화되어 레코드를 쿼리하여 이름 값이 B로 확인되지만 어떠한 작업도 실행하지 않습니다.
이후 T3 트랜잭션이 시작됩니다.
T3은 id가 1인 레코드의 이름을 C로 수정하고 트랜잭션을 커밋합니다. 이후 T1 트랜잭션이 실행을 재개하면서 다시 레코드를 쿼리하면 이름 값이 이제 C로 나타납니다. 이는 반복되지 않는 읽기를 보여줍니다.
아래는 이미지를 표시하는 링크입니다.
4. Phantom read.
팬텀 리드는 반복 불가능한 리드와 어느 정도 유사하지만, 반복 불가능한 리드는 데이터 값의 차이를 강조하는 것과 달리, 팬텀 리드는 데이터 레코드의 숫자의 변화에 중점을 두어 추가나 삭제와 같은 변화를 강조합니다. 데이터 집합에서 환상이나 "유령"을 보는 것과 유사합니다.
두 개의 트랜잭션, T1과 T2를 고려해봅시다. 트랜잭션 T1이 시작되고 SQL 쿼리를 실행합니다: select * from user, 현재 결과가 5개의 행이라고 가정합니다. 이 시점에서 트랜잭션 T2가 시작되어 사용자 테이블에 레코드를 삽입하고 트랜잭션을 커밋합니다.
그 후에 트랜잭션 T1이 다른 select * from user 쿼리를 실행하여 실행을 계속하면 결과가 이제 6개의 행으로 구성되어 있는 것을 발견합니다. 이는 그림 속에 있는 것과 같이 '유령 읽기'라고 알려진 것을 보여줍니다.
아래는 현대 데이터베이스에서 일반적으로 발생하는 네 가지 문제이며, 이러한 문제는 서로 다른 트랜잭션 격리 수준에서 발생할 수 있습니다. 그래서 다음에 분석할 주제는 트랜잭션의 격리 수준입니다.
![]()
다중 버전 동시성 제어(MVCC) 메커니즘.
트랜잭션 격리 수준은 다음 네 가지 유형으로 분류됩니다:
- 읽지 않은 커밋.
- 커밋된 읽기.
- 반복 가능한 읽기.
- 직렬화된 읽기.
MVCC는 데이터베이스 관리 시스템에서 일반적으로 구현된 동시성 제어 방법입니다. 이는 데이터베이스에 대한 동시 액세스를 용이하게 하고 명시적 트랜잭션 격리의 중요한 측면으로 기능합니다.
이 시점에서 새로운 개념을 소개합니다: 데이터가 디스크에 저장될 때, 각 레코드는 트랜잭션 ID와 롤백 포인터와 함께 저장됩니다.
![]()
- 트랜잭션 ID: 각 트랜잭션에 대한 고유 식별자입니다.
- 롤백 포인터: 현재 트랜잭션 이전 버전의 레코드에 대한 참조(포인터)로, 현재 타임스탬프에 상대적으로 이전 데이터를 가리키는 용어입니다.
특정 레코드에서 작업을 수행해야 한다고 가정해 봅시다. 먼저 해당 레코드가 버퍼 풀에 로드되어 있어야 하며, 그 레코드에 연관된 되돌리기 로그 레코드가 있어야 합니다.
아래는 Markdown 형식으로 변경한 내용입니다.
![]()
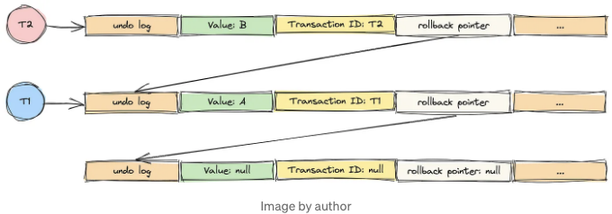
거래 T1이 시작되었고 값을 A로 수정했다고 가정해 봅시다.
![]()
거래 T1이 아직 진행 중인 동안 거래 T2가 시작되어 값을 B로 수정합니다.
이 시점에서 트랜잭션 T1 및 T2는 아직 진행 중입니다. 트랜잭션 T3가 시작되어 값을 C로 수정합니다.
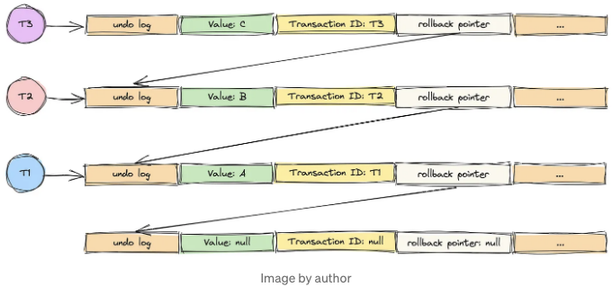
위 다이어그램은 MVCC 버전 제어 체인이라는 특정 용어를 소개합니다. 또한 ReadView라는 새 용어가 포함됩니다.
각 트랜잭션은 시작될 때마다 ReadView가 생성됩니다.
이제 ReadView에 대해 자세한 설명과 분석을 진행하겠습니다.
ReadView.
각 트랜잭션이 시작될 때마다 ReadView가 생성됩니다. 그 목적은 각 트랜잭션 내의 작업과 관련된 특정 Undo Log 항목을 기록하는 것입니다.
여러 필드가 관련됩니다: m_ids, min_trx_id, max_trx_id 및 creator_trx_id입니다. 이들의 구체적인 의미는 다음과 같습니다:
- m_ids: 활성 트랜잭션의 ID를 기록하는데 사용됩니다.
- min_trx_id: 현재 활성 트랜잭션 중 가장 작은 트랜잭션 ID입니다.
- max_trx_id: 생성될 다음 트랜잭션 ID입니다. 현재 m_ids에 없는 ID여야 합니다. (트랜잭션 ID는 오름차순으로 생성됩니다.)
- creator_trx_id: 현재 활성 트랜잭션의 ID입니다.
현재 저장된 레코드가 다음과 같이 있습니다:
![]()
지금쯤에는 이미 명확히 이 레코드가 이전 트랜잭션에서의 수정 결과임을 알고 계실 것입니다.
이제 우리는 T4, T5 및 T6이 순차적으로 열렸다고 가정해 봅시다.
우리는 트랜잭션 T4부터 시작해 봅시다. 이 시점에서 m_ids는 [T4, T5, T6]이고, min_trx_id는 T4, max_trx_id는 T7, 그리고 creator_trx_id는 T4입니다.
![]()
T4 트랜잭션이 쿼리 작업을 시작합니다. 아래는 실행 방법입니다:
첫째로, MVCC 버전 제어 체인을 따라 내려가면서 이 레코드의 이전 작업에 대한 트랜잭션 ID를 검색합니다.
해당 언도로그 항목과 연관된 트랜잭션 ID가 T3임을 발견합니다. 이 ID는 T4의 자체 트랜잭션 ID보다 작은 것으로 나타납니다.
따라서 이 레코드가 T4 트랜잭션에 의해 수정되지 않았음이 확인됩니다.
또한 m_ids의 거래 ID가 T4, T5, T6이며 T3가 모든 것보다 작기 때문에, 현재 거래가 시작되기 전에 발견된 레코드가 있었다는 것을 유추할 수 있습니다.
따라서 거래 T4는 값 C를 검색합니다.
이 시점에서 거래 T5도이 레코드를 쿼리하기 시작합니다. 거래 T5는 데이터를 쿼리하는 동일한 절차를 따를 것이며, 결과는 C입니다. 위에서 거래 T4의 분석을 고려하면 간단해 보입니다.
거래 T5가 값을 B로 변경하면 무엇이 발생합니까?
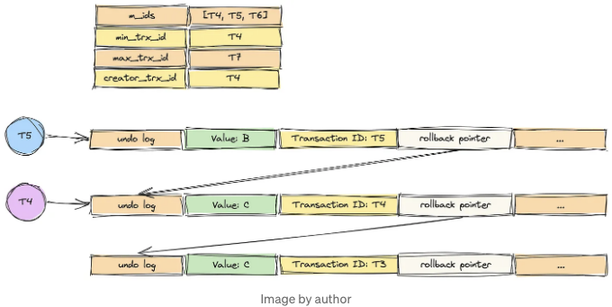
이 시점에서 트랜잭션 T4가 다시 활성화되어 다른 쿼리 작업을 실행합니다. 결과는 무엇이어아아할까요?
먼저, 트랜잭션 T4는 이 레코드의 MVCC 버전 제어 체인을 아래로 따라가다가 ID가 T5인 트랜잭션을 만납니다.
M_ids의 최소 트랜잭션 ID보다 T5의 트랜잭션 ID가 더 크기 때문에 T5 트랜잭션이 현재 활성 상태임을 확인할 수 있습니다.
그래서 트랜잭션 T4는 T5와 관련된 undo 로그에서 값을 검색하지 않습니다.
이어서 검색을 계속하면, 트랜잭션 ID가 T3인 undo 로그 레코드를 찾습니다. 비교해보니, T3가 m_ids에 없으며 m_ids의 최소 트랜잭션 ID보다 작은 것을 확인합니다.
마지막으로, 초기 쿼리 결정 프로세스를 반복합니다.
이 순간에 트랜잭션 T4가이 레코드의 값을 A로 변경한다고 가정해봅시다. 그런 다음, 트랜잭션 T4가이 레코드를 다시 쿼리합니다.
결과는 무엇이 될까요?
![]()
트랜잭션 T4가 쿼리를 시작하고 이 시점에서 롤백 로그의 첫 번째 항목의 트랜잭션 ID가 T4임을 발견합니다. 비교해보니 자신의 트랜잭션 ID라는 것을 깨달았습니다. 따라서 쿼리 결과는 A입니다.
이 시점에서 트랜잭션 T5가 쿼리를 한다면 어떻게 될까요?
먼저, T5는 최신 트랜잭션 ID가 m_ids에 있는 T4임을 알아차립니다. 이것은 현재 진행 중인 트랜잭션으로서 자신의 트랜잭션 ID와 다르다는 것을 추론할 수 있습니다.
그러므로 T5는 이 값을 가져오지 않을 것입니다.
그런 다음, T5는 undo 로그 체인을 따라 거슬러 올라가 T5 트랜잭션 ID가 있는 레코드를 찾아 자신의 트랜잭션이라는 것을 깨달습니다.
따라서, T5에 대한 쿼리 결과는 B입니다.
실제로, 거래의 기본 메커니즘은 ReadView 개념을 기반으로 설계되었습니다. 거래의 기본 원칙에 대해 알아볼 때 Read Commit (RC)와 Repeatable Read (RR)를 사용하여 분석해 보겠습니다.
Read Commit.
Read Commit은 거래 격리 수준 중 하나로, 커밋된 레코드를 읽는 것을 의미합니다. 예를 들어, 거래 A와 거래 B가 모두 활동 중인 경우, 거래 B에 의해 커밋된 레코드를 거래 A가 읽을 수 있습니다.
차근차근 분석해 봅시다. 먼저, Read Commit 격리 수준 아래에서 각 쿼리 작업은 새로운 ReadView를 생성한다는 점을 이해하는 것이 중요합니다. 이것이 Read Commit의 핵심 아이디어입니다.
거래 ID가 각각 T1과 T2인 거래 T1과 T2가 있다고 가정해봅시다.
거래 T1은 아직 활성화되지 않았지만, 거래 T2는 커밋하기 전에 특정 레코드의 값을 B로 변경합니다 (원래 값은 X로 가정).
지금은 다음 다이어그램으로 시나리오를 시각화할 수 있습니다:
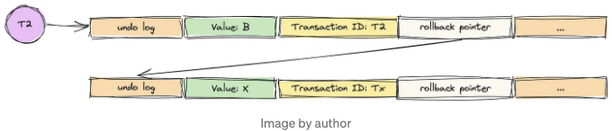
이 시점에서 트랜잭션 T1이 활성화되어 쿼리 작업을 시작합니다.
위의 분석을 따라 데이터베이스는 다음 속성 값으로 새로운 ReadView를 생성합니다:
- m_ids: [T1, T2].
- min_trx_id: T1.
- max_trx_id: T3.
- creator_trx_id: T1.
다음으로, 이 프로세스는 이전에 논의된 것과 유사합니다.
우선 T1은 가장 최근의 트랜잭션 ID인 T2를 조회합니다.
T2가 m_ids에 있는데 자체 트랜잭션 ID와 일치하지 않음을 발견합니다.
그래서 undo 로그 체인을 따라 계속 검색합니다.
그런 다음 트랜잭션 ID Tx를 가진 레코드를 발견하고, Tx가 m_ids에 없으며, 최소 트랜잭션 ID(T1)보다 작음을 알아차립니다.
따라서, 거래 ID Tx를 가진 레코드가 원래 있었음을 결론 지을 수 있으며, 쿼리 결과는 X입니다.
그다음, 거래 T2가 다시 활성화되어 거래를 커밋하고, 그런 다음 거래 T1이 다른 쿼리 작업을 시작합니다.
이제 이 시점에서 Read Commit (RC)의 핵심이 분명해집니다: 데이터베이스는 거래 T1을 위해 새로운 ReadView를 생성하며, 그 네 가지 속성에 대한 다음 값이 있습니다.
- m_ids: [T1].
- min_trx_id: T1.
- max_trx_id: T3.
- creator_trx_id: T1.
위에 있는 표 태그를 Markdown 형식으로 변경해주세요.
Repeatable Read (RR)의 핵심 아이디어는 ReadView가 생성된 후 트랜잭션이 커밋될 때까지 다시 생성되지 않는다는 것입니다.
우선, 트랜잭션 ID가 각각 T1과 T2인 T1과 T2 트랜잭션을 고려해 보겠습니다. 트랜잭션 T2는 값이 B로 수정되고(원래 값은 X였다고 가정), 그 후에 트랜잭션 T1은 쿼리 작업을 시작합니다:
![]()
쿼리 프로세스는 이전과 정확히 동일합니다. 여기서 다시 자세히 설명하지는 않겠습니다.
다음으로, 트랜잭션 T2가 다시 활성화되어 트랜잭션을 커밋하고, 그 후에 트랜잭션 T1이 또 다른 쿼리를 시작합니다.
이제 기적이 일어나는데, 방금 언급한 대로 ReadView는 트랜잭션이 커밋될 때까지 다시 생성되지 않습니다.
트랜잭션 T1이 ReadView를 생성할 때 m_ids로 T1과 T2를 가지고 있었기 때문에 이제도 같은 값을 가지고 있습니다.
쿼리는 다음과 같이 진행됩니다: 트랜잭션 T1은 초기에 T2의 트랜잭션 ID를 가진 레코드를 만납니다.
T2가 m_ids에 있기 때문에 해당 값을 가져오지 않고 검색을 계속할 것입니다.
거래 ID Tx를 가진 레코드를 찾았을 때 Tx가 m_ids에 없다고 판단하면 쿼리 결과는 X가 됩니다.
이제 왜 이 독립성 수준 아래의 거래가 서로 간섭하지 않는지 이해하셨죠? 이것이 그 원리입니다.
그런 이야기를 좋아한다면 저를 지원하고 싶으시면 박수를 부탁드립니다.
여러분의 지원은 저에게 매우 중요합니다. 감사합니다.