자주 사용되는 백엔드 최적화 기술을 담은 핸드북
저는 백엔드 엔지니어로서 다양한 성능 최적화 문제를 경험해왔습니다. 각 문제는 그에 맞는 해결책과 기술을 가지고 있죠. 이 기사에서는 이러한 내용을 다루겠습니다.
성능에 대해 이야기할 때, 다양한 의미가 있을 수 있습니다:
- 높은 응답 시간
- 낮은 응용프로그램 반응성
- 높은 메모리 또는 CPU 사용량
- 네트워크 자원의 낭비
- 유후한 컴퓨팅 자원
- 그 밖에도...
위에서 언급한 모든 것들은 성능 문제로 간주될 수 있지만, 본 문서에서는 첫 번째 범주에 초점을 맞출 것입니다. 따라서 성능 문제, 병목 현상 또는 문제라고 언급할 때, 고객과 서버 간의 상호 작용이 느린 이유로 발생하는 높은 응답 시간을 의미합니다. 이 토론의 목적을 위해 HTTP가 이 상호 작용의 프로토콜로 선택되었다고 가정하겠습니다.
다양한 수준에서 최적화하기
제 경험을 토대로, 영향을 받는 범위에 따라 웹 애플리케이션을 최적화할 수 있는 세 가지 주요 수준(또는 레이어)을 식별했습니다:
- 애플리케이션 레이어
- 데이터베이스 레이어
- 인프라스트럭처 레이어
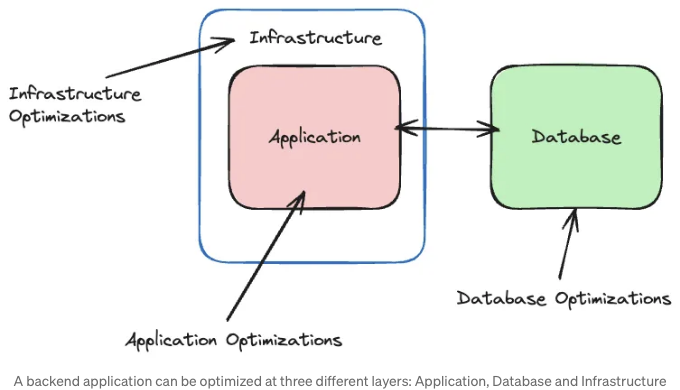
비록이 분류는 엄격한 기준을 갖고 있지 않고 결코 절대적이지 않을 수 있지만, 독자들이 자신의 생각을 더 잘 조직화할 수 있도록 도와줄 충분히 명확한 기법 그룹화를 제공하길 바랍니다.
어플리케이션 레이어 최적화
이 레이어는 우리 어플리케이션의 코드를 변경하는 조정을 포함합니다. 우리는 데이터베이스와 인프라 레이어를 건드리지 않은 채 애플리케이션의 일부를 더 나은 방법으로 다시 작성할 수 있습니다.
우리 코드를 신중하게 측정한 후에는 더 빠른 대안을 찾거나 더 나은 데이터 구조를 사용하여 사용 중인 알고리즘을 최적화하고 싶을 수 있습니다. 효율적인 처리, 탐색 및 계산 알고리즘과 목적에 맞는 데이터 구조는 성능을 크게 향상시킬 수 있습니다. 게다가 레이턴시에 민감한 코드를 낮은 수준의 프로그래밍 언어로 다시 작성하면 이점을 얻을 수도 있습니다.
비동기 패턴을 구현하면 상당한 성능 향상을 이끌어 낼 수 있습니다. 긴 수행 시간이 필요한 작업을 별도의 작업자 프로세스에서 처리함으로써 애플리케이션은 이러한 작업이 완료될 때까지 응답을 기다릴 필요가 없습니다. 비긴요한 작업을 비동기 작업자로 오프로드하여 사용자 경험에 미치는 영향을 평가하고 비즈니스 요구에 맞다면 이 패턴을 수용하세요.
프로그래밍 환경에서 NodeJS와 Go와 같은 것들은 응용 수준에서 동시성을 지원합니다. 이 기술을 사용하면 여러 작업이 순차적으로 실행되는 대신 동시에 실행되도록 허용되며, 모든 작업이 완료된 후에 작업을 계속할 수 있습니다. 동시 응용 프로그램은 종종보다 복잡한 코드베이스로 이어질 수 있지만, CPU 유휴 간격을 더 효과적으로 활용할 수 있습니다. 이 기법이 작업 실행 시간을 감소시키는 것은 아니지만 CPU 리소스를 더 효율적으로 이용하려는 목표를 가지고 있습니다.
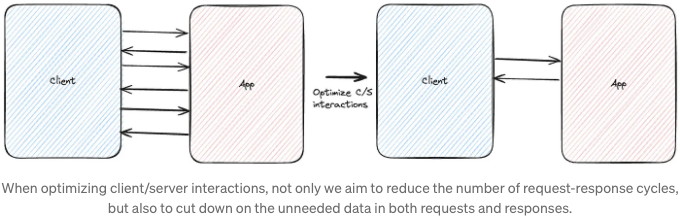
위의 기술들은 성능을 향상시킬 수 있지만, 종종 클라이언트/서버 상호작용을 최적화함으로써 상당한 성과를 얻을 수 있습니다. 사용자 경험을 분석하고 클라이언트/서버 통신을 더 효율적으로 만들 수 있는 방법을 식별해보세요. 캐싱 메커니즘을 사용하면 왕복 횟수를 줄일 수 있습니다. 페이징은 콘텐츠를 과다하게 가져오는 것을 피하는 일반적인 기술입니다. 사용자 인터페이스에 필요한 데이터만 가져오는 BFF(Backend for Frontend)를 구축하면 더 적은 서버 요청으로 결과를 얻을 수 있습니다. 이제 여러 개체를 단일(총계) API 호출을 통해 가져올 수 있습니다.
데이터베이스 레이어 최적화
데이터베이스는 종종 백엔드 응용 프로그램에서 병목 현상이 발생합니다. 잘못된 스키마 설계는 비효율적인 작업과 느린 쿼리를 야기할 수 있습니다. 다음 기술들은 이 레이어에서의 성능 문제를 해결하는 데 도움이 될 수 있습니다.
현대 데이터베이스는 읽기 속도를 높일 수 있는 색인 기능을 제공합니다. 색인은 하나 이상의 필드를 기반으로 데이터에 대한 참조를 저장하는 보조 데이터 구조입니다. 애플리케이션에서 일반적인 읽기 패턴을 평가한 후 색인 전략을 신중하게 고려해보세요. 아직 색인을 사용하고 있지 않다면 시작할 때입니다.
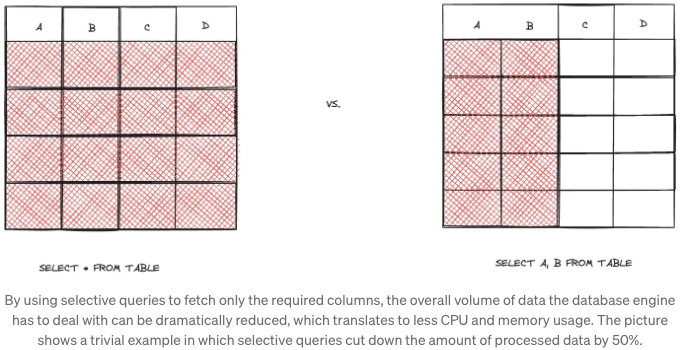
데이터베이스 쿼리를 실행할 때는 행과 열의 수에 따라 처리해야 하는 데이터 양이 많아집니다. 많은 개발자들이 읽기 작업의 영향 표면을 줄이면 성능이 어떻게 향상될 수 있는지를 과소평가합니다. 선택적 쿼리를 사용하여 필요한 열만 검색하거나 (예: SQL에서 SELECT *를 피하거나 MongoDB에서 프로젝션 사용) 사용 사례에 따라 페이지 쿼리를 사용하여 필요한 행만 가져올 수 있습니다.
대부분의 데이터베이스 제공업체는 확장 기능을 제공합니다. 수직 확장은 양질의 하드웨어를 확보하여 성능을 향상시키는 반면, 수평 확장은 더 많은 처리 노드(예: 서버)를 추가하여 용량을 늘리는 방식입니다. 신중한 평가 후 데이터베이스의 확장을 고려해보세요. 수직 확장은 주로 SQL 데이터베이스에 적용되고, 수평 확장은 NoSQL 데이터베이스에서 더 일반적입니다.
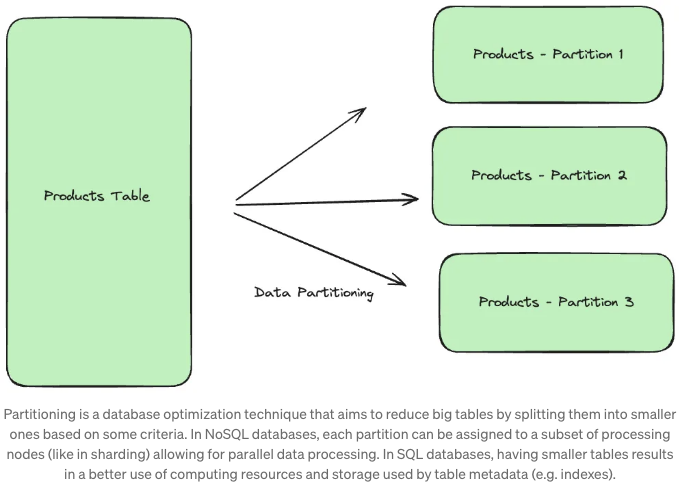
모든 데이터베이스 작업은 하나 이상의 데이터베이스 노드에서 처리되는 워크로드를 생성합니다. 이 워크로드를 더 잘 관리하기 위해 데이터 파티셔닝 기술을 고려해보세요. 데이터 파티셔닝은 데이터를 청크로 나누어 각 처리 노드의 작업량을 줄이는 방법입니다. 수직 분할은 열에 따라 데이터를 나누고, 수평 분할은 행에 따라 데이터를 나눕니다. 적시에 파티셔닝은 오래된 데이터나 자주 액세스되지 않는 행을 별도의 테이블로 이동하거나 아카이브하여 데이터베이스 부담을 줄입니다. 샤딩은 NoSQL 데이터베이스에서 흔히 볼 수 있는데, 테이블 청크를 여러 노드에 분산시켜 작업을 병렬로 진행합니다.
데이터베이스 성능을 개선하는 가장 강력한 기술 중 하나는 데이터베이스 솔루션을 재설계하는 것입니다. 이 도전적인 접근 방식은 전체 응용 프로그램 재작성을 포함할 수 있지만, 일반적으로 상당한 이득을 가져옵니다. 응용 프로그램이 데이터와 상호작용하는 방식에 대해 철저히 이해한 후 스키마, 테이블 및 인덱싱 전략을 재설계하는 것이 유익할 수 있습니다. 읽기 및 쓰기 패턴이 크게 다른 경우 CQRS를 채택하거나, 응용 프로그램 요구 사항에 부합하지 않는 데이터베이스 간에 SQL 및 NoSQL을 전환하는 것을 고려해보세요.
인프라스트럭처 레이어 최적화
인프라스트럭처 레이어 최적화는 통신 메커니즘, 네트워크 아키텍처 및 기저 하위 수준 자원에 대한 변경을 포함합니다. 주로 다른 레이어에서 상당한 성능 향상이 일어나지만, 이 수준에서 조정을 통해 레이턴시 및 실행 시간 면에서 상당한 이점을 얻을 수도 있습니다.
콘텐츠 전달 네트워크(CDNs)는 지리적으로 분산된 네트워크를 통해 서버를 사용자 근처에 배치함으로써 사용자 친화적 콘텐츠(HTML 페이지, JavaScript, CSS)의 대기 시간과 응답 시간을 줄입니다. 사용자 친화적 자산의 일부 또는 전부를 전달하기 위해 CDNs를 고려해 보세요. 많은 CDN 공급업체가 콘텐츠 캐싱 및 HTTP/2 지원과 같은 고급 성능 기능을 제공합니다.
응용 프로그램에서 불필요한 지연이 발생하고 인프라 문제가 의심될 경우 현재 네트워크 아키텍처를 평가해 보세요. 원치 않는 레이턴시를 추가하는 불필요한 호핑, 중간 장치, 프로토콜 또는 잘못 구성된 프록시의 수에 놀라실 수도 있습니다.
서버의 HTTP 버전 업그레이드는 과거에는 복잡했지만 지금은 훨씬 쉬워졌습니다. 서버와 클라이언트 모두에 널리 사용되는 HTTP/2 또는 HTTP/3로 업그레이드를 고려해 보세요. 이러한 새로운 버전은 연결 최적화, 데이터 압축 및 심지어 전송 계층으로 UDP 사용과 같은 방식으로 성능 병목 현상을 해소합니다.
HTTP/1에 갇혀 있다면, 여전히 기본 TCP 프로토콜에 대한 저수준 최적화를 활성화할 수 있어요. 서버 운영 체제를 정기적으로 업그레이드하면 최신 TCP 향상 기능이 적용돼요. 게다가 초기 혼잡 윈도우 크기(CWND)를 증가시켜 Slow-Start 알고리즘을 가속화하는 등 구성을 직접 활성화할 수도 있어요. 또한 순서가 바뀐 데이터 패킷을 확인하기 위해 선택적 수신(Acknowledge)을 활성화하거나, 유휴 상태 후에 TCP Slow-Start를 비활성화하여 유휴 연결의 업로드 트로틀링을 방지하고, TCP Fast Open을 활성화하여 TCP 핸드쉐이크에 필요한 작업을 줄일 수도 있어요.
전송 중 데이터 압축은 현대 웹 애플리케이션에서 거의 필수적이에요. 특히 HTML 자산(.html, .js, .css 파일)에 의존하는 애플리케이션에서 압축 알고리즘인 deflate, gzip, 또는 Brotli를 사용하면 트래픽 양을 줄일 수 있어요. 이를 통해 사용 가능한 대역폭을 더 효과적으로 활용할 수 있어요.
HTTP는 가장 인기 있는 웹 API 기술이며, HTTP를 사용하는 대부분의 API는 REST 원칙을 따라 RESTful API가 되어요. 하지만 GraphQL과 gRPC와 같은 대안들은 시스템 간 통신에 대한 새로운 기회를 제공하거나요. GraphQL은 여전히 HTTP를 기반으로 하면서 필요한 데이터만 효율적으로 전송하여 과다 및 부족한 데이터를 피할 수 있어요. gRPC는 HTTP/2와 프로토콜 버퍼를 사용하여 대역폭을 더 효율적으로 활용할 수 있어요. REST가 더 이상 요구사항을 충족하지 못할 때 API 기술을 변경하는 것도 고려해보세요.
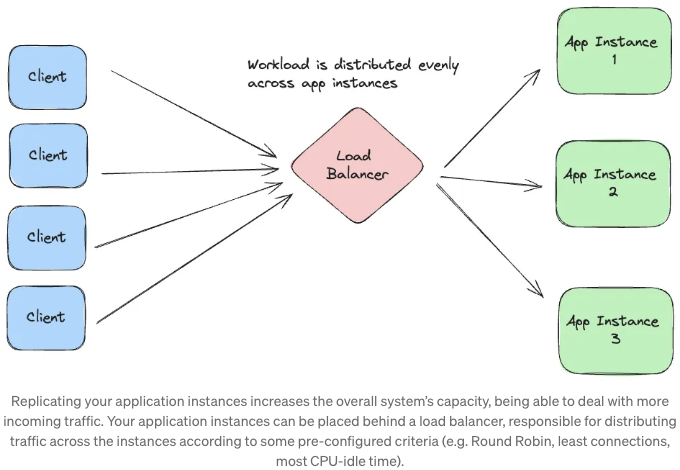
백엔드 응용 프로그램의 확장은 복제를 수반할 수 있습니다. 이는 주 어플리케이션 프로세스를 복제하거나 클러스터링하는 것뿐만 아니라 인프라를 복제하는 것을 의미합니다. 가상 머신의 수(쿠버네티스의 워커 노드)와 어플리케이션 인스턴스의 수(pods in Kubernetes)를 늘리면 더 많은 트래픽을 처리할 수 있습니다. 그러나 이것이 항상 해결책은 아닙니다. 더 많은 트래픽을 처리하기 위해 복제가 유일한 방법이라면 새로운 아키텍처 대안을 고려할 시기일 수도 있습니다. 복제는 병행성 문제와 같은 새로운 도전 과제를 도입할 수 있으며, 어플리케이션이 단일 인스턴스로 실행될 때 발생하지 않았던 문제가 발생할 수 있습니다. 그러나 적용 가능하다면 어플리케이션을 복제함으로써 병렬성과 부하 분산을 활용할 수 있습니다.
결론
요약하면, 웹 백엔드를 최적화하기 위해 가장 흔히 사용되는 몇 가지 기술을 살펴보았습니다. 본문에서 다루지 않은 많은 기술들이 더 있습니다. 이러한 개선 사항을 구현할 지를 결정하는 것은 우리가 작업하는 애플리케이션의 유형과 기능적 비기능적 요구 사항에 달려 있으며, 종종 기존 아키텍처에 제약을 가하고 우리의 행동 영역을 제한할 수 있습니다.
측정과 테스트는 어떤 수정을 구현할지 결정하고 어떻게 구현해야 하는지를 결정하는 데 필수적입니다. 이 없이는 해당 애플리케이션에 적합하게 작동할 것을 보장할 수 없습니다. 여러분은 여러 기능 집합을 선택하고 Proof of Concept(PoC)를 실행하여 통찰을 얻을 수 있습니다. 이 문맥에서 부하 테스트는 높은 작업량 시나리오를 에뮬레이션하고 최적화 전후에 애플리케이션이 얼마나 잘 작동하는지 확인하는 데 매우 도움이 됩니다.
마지막으로 본 기사에서 다룬 기술들은 다음과 같습니다:
애플리케이션 계층 최적화
- 사용 중인 알고리즘 최적화
- 비동기 함수 사용
- 병렬 처리 기능 활용하기
- 클라이언트/서버 상호작용 최적화하기
데이터베이스 레이어 최적화
- 인덱싱 활용
- 선택적 쿼리 사용
- 데이터베이스 확장
- 데이터 파티셔닝 구현
- 데이터베이스 솔루션 재설계
인프라스트럭처 레이어 최적화
- CDN 사용
- 네트워크 아키텍처 검토
- HTTP/2 또는 HTTP/3로 업그레이드
- TCP 최적화를 위한 낮은 수준 설정 활성화
- 데이터 압축
- 대안 웹 API 기술 고려
- 인프라 복제
만약 이 기사가 도움이 되었다면, 좋아요 버튼을 꾹 눌러주세요! 그리고 구독도 잊지 말아주세요. 앞으로 더 멋진 팁과 요령이 쏟아질테니 기대해주세요. 여러분의 의견을 듣는 것을 좋아해요, 의견을 남겨주세요. 더 멋진 콘텐츠가 여러분을 기다리고 있어요!