소개
마이크로서비스가 직면한 큰 과제 중 하나는 여러 리소스에서 데이터를 검색해서 결합하고 UI를 지원하는 방법입니다. 모놀리틱 응용프로그램과 달리, 마이크로서비스 아키텍처는 도전적입니다. 쿼리는 종종 여러 서비스가 소유한 데이터베이스 중에 흩어져 있는 데이터를 검색해야 합니다. 하지만 전통적인 분산 쿼리 메커니즘을 사용할 수 없습니다. 실제로 사용할 수 있다 하더라도 캡슐화를 위반하게 됩니다.
이러한 쿼리 연산을 구현하는 것은 간단하지 않습니다.
이 블로그 포스트에서는 마이크로서비스에서 데이터를 쿼리하는 데 사용할 수 있는 주요 방법에 대해 이야기하겠습니다.
마이크로서비스 아키텍처에서 쿼리 작업을 구현하는 두 가지 다른 패턴이 있습니다:
- API 구성 패턴 — 이것은 가장 간단한 접근 방식이며 가능한 경우 사용해야 합니다. 데이터를 소유한 서비스의 클라이언트가 서비스를 호출하고 결과를 결합하는 책임이 있습니다.
- 명령-쿼리 책임 분리 (CQRS) 패턴 — API 구성 패턴보다 강력하지만 더 복잡합니다. 쿼리를 지원하기 위한 목적으로 하나 이상의 뷰 데이터베이스를 유지합니다.
API 구성 패턴을 사용한 쿼리
주문을 찾는 findOrder라는 쿼리를 생성해야 해야 할 필요성이 있다고 가정해봅시다. 이 함수는 orderId를 매개변수로 사용하고 주문에 관한 정보가 포함된 OrderDetails 객체를 반환합니다. 그림에 나타난 것처럼, 이 작업은 주문 상태 뷰를 구현한 프론트엔드 모듈, 예를 들어 모바일 기기나 웹 응용프로그램에 의해 호출됩니다.
주문 상태 뷰에서 표시되는 정보에는 주문의 기본 정보가 포함되어 있습니다. 주문 상태, 결제 상태, 식당의 관점에서의 주문 상태, 그리고 배송 상태가 포함됩니다. 배송 상태는 이동 중인 경우 위치와 예상 배송 시간을 포함합니다.
데이터가 다음 서비스에 흩어져 있는 것을 보실 수 있습니다:
- 주문 서비스 — 주문 정보 및 상태 등 기본 주문 정보
- 주방 서비스 — 식당의 관점에서의 주문 상태 및 픽업 준비 예상 시간
- 배송 서비스 — 주문의 배송 상태, 예상 배송 정보 및 현재 위치
- 회계 서비스 — 주문의 결제 상태
주문 세부 정보를 필요로 하는 모든 고객은 이러한 서비스 전체를 요청해야 합니다.
API 구성 패턴 개요
여러 서비스가 소유한 데이터를 검색하는 findOrder()와 같은 쿼리 작업을 실행하는 한 가지 방법은 API 구성 패턴을 사용하는 것입니다.
다음 그림은 이 패턴의 구조를 보여줍니다. 이 패턴에는 두 종류의 참가자가 있습니다:
- API 구성자 — 이는 공급자 서비스를 쿼리하여 쿼리 작업을 구현합니다.
- 공급자 서비스 — 이는 쿼리가 반환하는 데이터 중 일부를 소유한 서비스입니다.
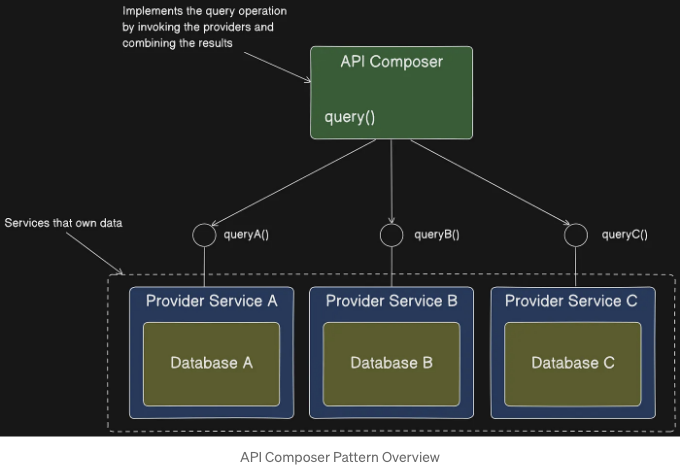
위의 이미지는 세 개의 공급자 서비스를 보여줍니다. API 컴포저는 공급자 서비스에서 데이터를 검색하고 결과를 결합하여 쿼리를 구현합니다. API 컴포저는 웹 페이지를 렌더링하기 위해 데이터가 필요한 클라이언트인 웹 애플리케이션과 같은 경우일 수도 있고, API 게이트웨이와 같은 서비스인 경우도 있을 수 있습니다. 이는 쿼리 작업을 API 엔드포인트로 노출합니다.
특정 쿼리 작업을 구현하는 데이 패턴을 사용할 수 있는지 여러 요소에 따라 달라집니다:
- 데이터가 분할되어 있는지 여부
- 데이터를 소유하는 서비스에서 노출하는 API의 기능
- 서비스에서 사용하는 데이터베이스의 기능
예를 들어, 제공자 서비스에는 필요한 데이터를 검색하기 위한 API가 있더라도 집계기는 대량 데이터 집합을 효율적이지 못한 방법으로 메모리 내 결합할 수도 있습니다. 나중에 이 패턴을 사용할 수 없는 쿼리 작업의 예제를 볼 것입니다. 하지만, 다행히도 이 패턴이 적용 가능한 여러 시나리오가 있습니다. 이 패턴이 실제로 적용된 예시를 살펴보기 위해 다음과 같은 예시를 살펴보겠습니다.
API 조합 패턴을 사용하여 findOrder() 쿼리 작업을 구현하는 방법
findOrder() 쿼리 작업은 간단한 기본 키 기반 equijoin 쿼리에 해당됩니다. 각 제공자 서비스가 orderId에 따라 필요한 데이터를 검색하기 위한 API 엔드포인트를 가지고 있을 것으로 예상됩니다. 따라서 findOrder() 쿼리 작업은 API 조합 패턴을 통해 구현하는 데 우수한 후보입니다. API 작성자는 네 가지 서비스를 호출하고 결과를 결합합니다.
다음 이미지는 Find Order Composer의 디자인을 보여줍니다.
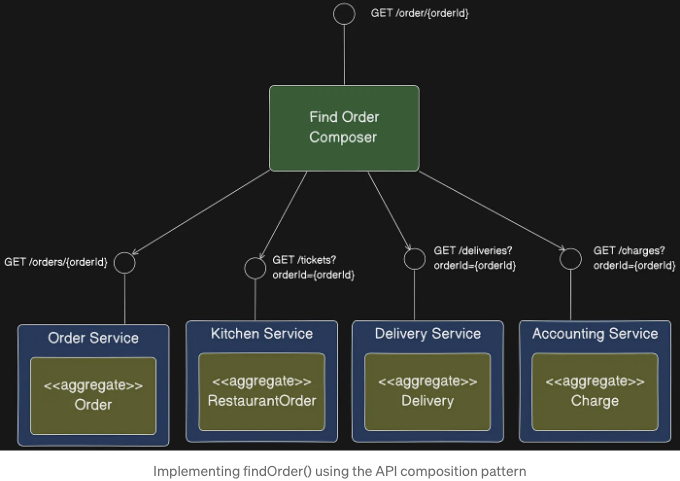
In this example, the API composer is a service that exposes the query as a REST endpoint. The Provider services also implement REST APIs.
The Find Order Composer implements a REST endpoint GET /order/'orderId'. It invokes the four services and joins the responses using the orderId. Each Provider service implements a REST endpoint that returns a response corresponding to a single aggregate. The OrderService retrieves its version of an Order by primary key and the other services use the orderId as a foreign key to retrieve their aggregates.
As you can see, the API composition pattern is quite simple. Let’s look at a couple of design issues you must address when applying this pattern.
API 합성 설계 이슈
이 패턴을 사용할 때, 몇 가지 설계 이슈를 고려해야 합니다:
- 아키텍처에서 쿼리 작업의 API 합성자로 어떤 구성 요소를 결정할 것인가
- 효율적인 집계 로직을 어떻게 작성할 것인가
각 이슈를 살펴보겠습니다.
API 조합자의 역할을 수행하는 주체는 누구일까요?
쿼리 작업의 API 조합자 역할을 맡을 주체를 결정해야 합니다. 선택할 수 있는 옵션은 세 가지가 있습니다.
다음 그림에서 볼 수 있는 첫 번째 옵션은 서비스의 클라이언트가 API 조합자 역할을 담당하는 것입니다.
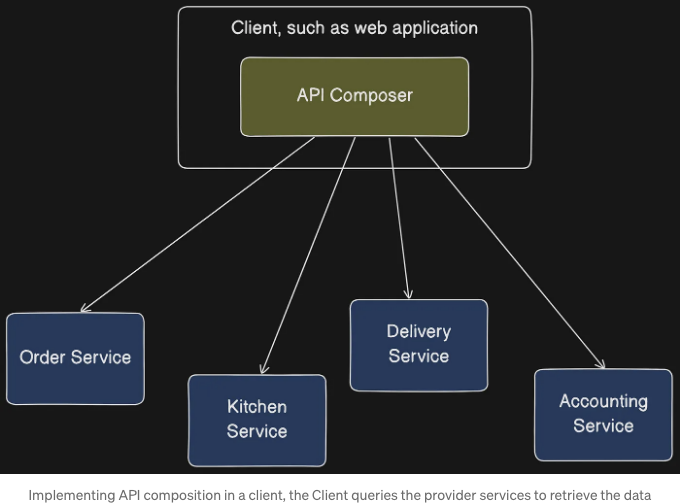
프론트엔드 클라이언트인 웹 애플리케이션은 주문 상태 뷰를 구현하고 같은 LAN에서 실행 중인 경우, 이 패턴을 사용하여 주문 세부 정보를 효율적으로 검색할 수 있습니다. 그러나 방화벽 외부에 있는 클라이언트가 느린 네트워크를 통해 서비스에 액세스 하는 경우에는 실용적이지 않을 수 있습니다. 이에 대해 다른 블로그 포스트에서 논의할 것입니다.
그림에 나타난 두 번째 옵션은 API 게이트웨이가 응용 프로그램의 외부 API를 구현하여 쿼리 작업에 대한 API 구성자 역할을 수행하는 것입니다.
이 옵션은 쿼리 작업이 응용 프로그램의 외부 API의 일부인 경우에 유용합니다. 다른 서비스에 요청을 라우팅하는 대신, API 게이트웨이가 API 구성 논리를 구현합니다.
이 접근 방식을 통해 방화벽 외부에서 실행 중인 모바일 장치와 같은 클라이언트가 단일 API 호출로 여러 서비스에서 데이터를 효율적으로 검색할 수 있습니다.
다음 그림에 나와 있는 세 번째 옵션은 독립된 서비스로서 API 컴포저를 구현하는 것입니다.
여러 서비스 내에서 내부적으로 사용되는 쿼리 작업에 대해 이 옵션을 사용해야 합니다. 또한 API 게이트웨이의 일부로 포함하기에는 집계 로직이 너무 복잡한 외부 접근 가능한 쿼리 작업에도 사용할 수 있습니다.
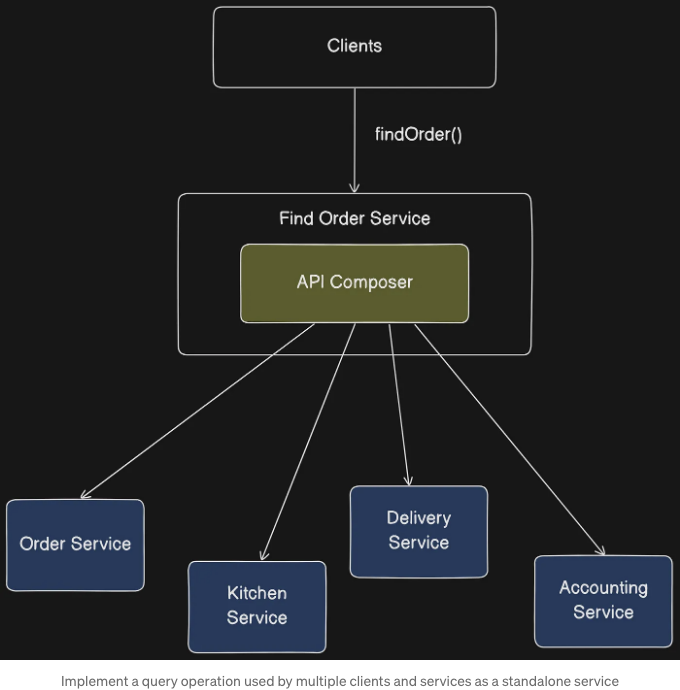
API 컴포저는 리액티브 프로그래밍 모델을 사용해야 합니다.
분산 시스템을 개발할 때는 대기 시간을 최소화하는 것이 항상 고려해야 합니다. 가능한 경우 API 합성기는 쿼리 작업의 응답 시간을 최소화하기 위해 공급 업체 서비스를 병렬로 호출해야 합니다.
예를 들어 Find Order Aggregator는 호출 사이에 의존성이 없기 때문에 네 가지 서비스를 동시에 호출해야 합니다. 그러나 때로는 API 합성기가 다른 서비스를 호출하려면 하나의 공급 업체 서비스의 결과가 필요할 수 있습니다. 이 경우 일부 공급 업체 서비스를 순차적으로 호출해야 할 수 있습니다.
순차 및 병렬 서비스 호출을 효율적으로 실행하는 로직은 복잡할 수 있습니다. API 합성기가 유지 관리 가능하고 성능 및 확장성이 좋도록 하려면 Java Completable-Future 또는 RxJava observables와 같은 반응형 디자인을 사용해야 합니다.
API 구성 패턴의 장단점
이 패턴은 마이크로서비스 아키텍처에서 쿼리 작업을 구현하는 간단하고 직관적인 방법입니다. 그러나 몇 가지 단점이 있습니다:
- 오버헤드 증가
- 가용성 감소 위험
- 트랜잭션 데이터 일관성 부족
이 세 가지를 살펴보겠습니다.
오버헤드 증가
이 패턴의 한 단점은 여러 서비스를 호출하고 여러 데이터베이스를 쿼리하는 데 발생하는 오버헤드입니다. 단일 요청으로 데이터를 검색할 수 있는 모놀리식 애플리케이션의 경우, 일반적으로 단일 데이터베이스 쿼리가 실행됩니다. 반면에 API 조합 패턴을 사용하는 경우에는 여러 요청과 데이터베이스 쿼리가 포함됩니다. 결과적으로 더 많은 컴퓨팅 및 네트워크 리소스가 필요해져 애플리케이션 실행 비용이 증가하게 됩니다.
가용성 감소의 위험
이 패턴의 또 다른 단점은 가용성이 감소한다는 점입니다. 작업의 가용성은 관련된 서비스의 수와 함께 감소합니다. 쿼리 작업의 구현은 API 컴포저와 적어도 두 개의 제공자 서비스를 포함하므로 단일 서비스보다 가용성이 크게 감소합니다. 예를 들어, 개별 서비스의 가용성이 99.5%라면, 네 개의 제공자 서비스를 호출하는 findOrder() 엔드포인트의 가용성은 99.5%(4+1) = 97.5%가 됩니다!
가용성을 향상시키기 위한 몇 가지 전략이 있습니다. 첫 번째 전략은 API 컴포저가 제공자 서비스가 사용할 수 없을 때 이전에 캐싱된 데이터를 반환하는 것입니다. API 컴포저는 때로 성능을 향상시키기 위해 제공자 서비스가 반환한 데이터를 캐시에 저장합니다. 이 캐시를 사용하여 가용성을 향상시킬 수도 있습니다. 제공자가 사용할 수 없는 경우 API 컴포저는 캐시에서 데이터를 반환할 수 있지만 해당 데이터는 오래된 것일 수 있습니다.
가용성을 향상시키는 또 다른 전략은 API 컴포저가 불완전한 데이터를 반환하는 것입니다. 예를 들어, Kitchen Service가 일시적으로 사용할 수 없는 경우 findOrder() 쿼리 작업의 API 컴포저는 그 서비스의 데이터를 응답에서 제외할 수 있습니다. 이는 사용자 인터페이스가 여전히 유용한 정보를 표시할 수 있기 때문입니다.
거래 데이터 일관성 부족
API 구성 패턴의 또 다른 단점은 데이터 일관성의 부족입니다. 단일체 애플리케이션은 일반적으로 단일 데이터베이스 트랜잭션을 사용하여 쿼리 작업을 수행합니다. ACID 트랜잭션은 고립 수준에 대한 세부 정보를 고려하더라도, 여러 데이터베이스 쿼리를 실행해도 응용 프로그램이 데이터의 일관된 뷰를 가지도록 보장합니다. 반면에 API 구성 패턴은 여러 데이터베이스에 대해 여러 데이터베이스 쿼리를 실행합니다. 따라서 쿼리 작업이 일관되지 않은 데이터를 반환할 위험이 있습니다.
예를 들어, 주문 서비스에서 검색한 주문은 "취소됨" 상태일 수 있지만, 주방 서비스에서 검색한 해당 티켓은 아직 취소되지 않을 수 있습니다. API 구성자는 이러한 불일치를 해결해야 하며, 이는 코드 복잡성을 증가시킵니다. 더 나쁜 상황은 API 구성자가 항상 일관성 없는 데이터를 감지하지 못할 수 있으며 이를 클라이언트에 반환할 수 있습니다.
이러한 단점에도 불구하고, API 구성 패턴은 매우 유용합니다. 이를 사용하여 많은 쿼리 작업을 구현할 수 있습니다. 그러나 이 패턴을 사용하여 효율적으로 구현할 수 없는 쿼리 작업도 있습니다. 예를 들어, 쿼리 작업은 API 구성자가 대량 데이터 집합을 인메모리 조인해야 하는 경우가 있을 수 있습니다.
CQRS 패턴 활용하기
많은 기업 애플리케이션은 트랜잭션 기록 시스템으로 RDBMS를 사용하고 Elasticsearch 또는 Solr과 같은 텍스트 검색 데이터베이스를 텍스트 검색 쿼리용으로 사용합니다. 일부 애플리케이션은 두 데이터베이스에 동시에 쓰기를 통해 동기화를 유지합니다. 다른 애플리케이션은 정기적으로 RDBMS에서 데이터를 텍스트 검색 엔진으로 복사합니다.
이 아키텍처를 사용하는 애플리케이션은 다중 데이터베이스의 장점을 활용합니다: RDBMS의 트랜잭션 속성 및 텍스트 데이터베이스의 쿼리 기능.
CQRS는 이러한 종류의 아키텍처의 일반화입니다. 이는 하나 이상의 뷰 데이터베이스를 유지하며, 해당 데이터베이스는 애플리케이션의 하나 이상의 쿼리를 구현합니다.
CQRS를 사용하는 동기
API 구성 패턴은 여러 서비스에서 데이터를 검색해야 하는 많은 쿼리를 구현하는 좋은 방법입니다. 그러나 이것은 마이크로서비스 아키텍처에서 쿼리하는 문제의 부분적인 해결책에 불과합니다. 그것은 API 구성 패턴으로 효율적으로 구현할 수 없는 여러 서비스 쿼리가 있기 때문입니다.
다음과 같은 상황에서 CQRS 패턴을 고려할 수 있습니다:
- 구현이 어려운 단일 서비스 쿼리도 있습니다. 어쩌면 서비스의 데이터베이스가 쿼리를 효율적으로 지원하지 않을 수도 있습니다.
- 또는 때로는 서비스가 다른 서비스가 소유한 데이터를 검색하는 쿼리를 구현하는 것이 합리적일 수도 있습니다.
여기서부터 시작해 보죠. 먼저 API 조합을 사용하여 효율적으로 구현할 수 없는 다중 서비스 쿼리를 살펴봅시다.
FindOrderHistory() 쿼리 작업 구현
findOrderHistory() 작업은 고객의 주문 내역을 검색합니다. 다음과 같은 여러 매개변수가 있습니다:
- consumerId — 고객을 식별합니다.
- pagination — 반환할 결과 페이지
- filter — 주문의 최대 연령, 선택적 주문 상태, 선택적으로 일치하는 음식점 이름 및 메뉴 항목을 포함한 필터 기준을 포함합니다.
이 쿼리 작업은 매칭되는 주문을 나이순으로 정렬한 OrderHistory 객체를 반환합니다. Order History 뷰를 구현하는 모듈에서 호출됩니다. 이 뷰는 주문 번호, 주문 상태, 주문 총액 및 예상 배송 시간을 포함한 각 주문의 요약을 표시합니다.
표면적으로 이 작업은 findOrder() 쿼리 작업과 유사합니다. 윯은 차이는 단지 하나가 아닌 여러 주문을 반환한다는 점입니다. API 컴포저가 각 Provider 서비스에 대해 동일한 쿼리를 실행하고 결과를 결합하기만 하면 되는 것 같지만, 그렇게 간단하지는 않습니다.
그것은 필터링이나 정렬에 사용되는 속성을 모든 서비스가 저장하지 않기 때문입니다. 예를 들어, findOrderHistory() 작업의 필터 기준 중 하나는 메뉴 항목과 일치하는 키워드입니다. Order Service 및 Kitchen Service만 주문의 메뉴 항목을 저장하며, Delivery Service나 Accounting Service는 메뉴 항목을 저장하지 않아 이 키워드를 사용하여 데이터를 필터링할 수 없습니다. 마찬가지로, Kitchen Service나 Delivery Service는 orderCreationDate 속성을 기준으로 정렬할 수 없습니다.
API 컴포저가 이 문제를 해결할 수 있는 두 가지 방법이 있습니다. 한 가지 해결책은 API 컴포저가 다음 그림에 표시된 대로 인메모리 조인을 수행하는 것입니다. Delivery Service와 Accounting Service에서 소비자를 위한 모든 주문을 검색하고, Order Service 및 Kitchen Service에서 검색된 주문과 조인 작업을 수행합니다.
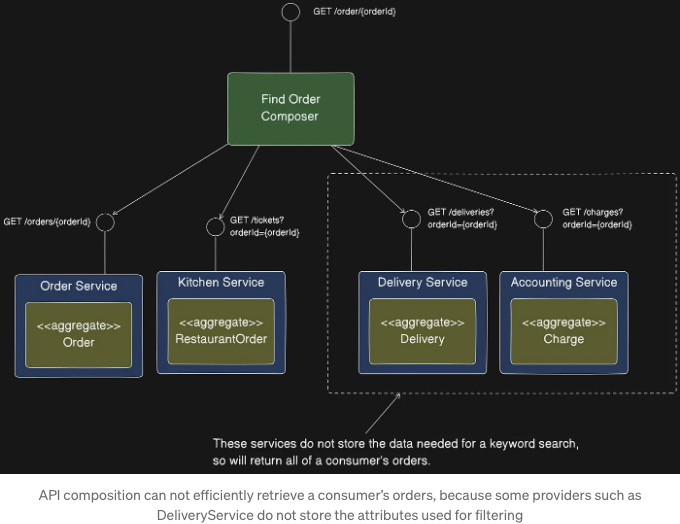
이 방법의 단점은 API 구성자가 대규모 데이터 세트를 검색하고 결합해야 할 수도 있어 효율적이지 않을 수 있다는 것입니다.
다른 해결책은 API 구성자가 Order Service 및 Kitchen Service에서 일치하는 주문을 검색한 다음 ID로 다른 서비스에서 주문을 요청하는 것입니다.
그러나 이는 해당 서비스가 대량 검색 API를 보유하고 있을 때에만 실행 가능합니다. 주문을 개별적으로 요청하는 것은 과도한 네트워크 트래픽 때문에 효율적이지 않을 것입니다.
findOrderHistory()와 같은 쿼리는 API composer가 RDBMS의 쿼리 실행 엔진의 기능을 복제해야 합니다. 한편으로는 덜 확장 가능한 데이터베이스에서 더 확장 가능한 애플리케이션으로 작업을 옮길 수 있습니다. 그러나 다른 한편으로는 덜 효율적일 수도 있습니다. 또한, 개발자들은 비즈니스 기능을 작성해야 하며, 쿼리 실행 엔진을 만들어야 하는 것은 아닙니다.
어려운 단일 서비스 쿼리: findAvailableRestaurants()
방금 본 것처럼, 여러 서비스에서 데이터를 검색하는 쿼리를 구현하는 것은 어려울 수 있습니다. 그러나 하나의 서비스에 로컬한 쿼리조차 구현하기 어려울 수 있습니다. 이는 몇 가지 이유 때문일 수 있습니다. 하나는, 곧 논의할 것처럼, 때로는 데이터를 소유하는 서비스가 쿼리를 구현하는 것이 적절하지 않을 수 있기 때문입니다. 다른 이유는 때로는 서비스의 데이터베이스(또는 데이터 모델)가 쿼리를 효율적으로 지원하지 않을 수 있기 때문입니다.
예를 들어, findAvailableRestaurants() 쿼리 작업을 고려해 봅시다. 이 쿼리는 주어진 주소와 시간에 배달할 수 있는 레스토랑을 찾습니다. 이 쿼리의 핵심은 배달 주소에서 일정 거리 내에 있는 레스토랑을 찾는 지리(위치 기반) 검색입니다. 주문 프로세스의 중요한 부분이며, 이는 사용 가능한 레스토랑을 표시하는 UI 모듈에 의해 호출됩니다.
이 쿼리 작업을 구현할 때 핵심적인 어려움은 효율적인 지리적 쿼리를 수행하는 것입니다. findAvailableRestaurants() 쿼리를 구현하는 방법은 레스토랑을 저장하는 데이터베이스의 기능에 따라 다릅니다.
예를 들어 MongoDB 또는 Postgres와 MySQL 지리적 확장을 사용하여 findAvailableRestaurants() 쿼리를 구현하는 것은 간단합니다. 이러한 데이터베이스는 지리적 데이터 유형, 색인 및 쿼리를 지원합니다. 이러한 데이터베이스 중 하나를 사용할 때 Restaurant Service는 위치 속성을 가진 데이터베이스 레코드로 레스토랑을 유지합니다. 위치 속성에 대한 지리적 색인에 의해 최적화된 지리적 쿼리를 사용하여 사용 가능한 레스토랑을 찾습니다.
어플리케이션이 레스토랑을 다른 유형의 데이터베이스에 저장하는 경우, findAvailableRestaurant() 쿼리를 구현하는 것은 더 어려워집니다. 지리적 쿼리를 지원하도록 설계된 데이터 형식의 레스토랑 데이터의 복제본을 유지해야 합니다.
예를 들어 어플리케이션은 DynamoDB에 대한 Geospatial Indexing Library를 사용하여 테이블을 지리적 색인으로 사용할 수 있습니다. 또는 어플리케이션은 레스토랑 데이터의 복제본을 전혀 다른 유형의 데이터베이스에 저장할 수 있으며, 이는 텍스트 쿼리에 텍스트 검색 데이터베이스를 사용하는 것과 매우 유사한 상황일 수 있습니다.
복제본 사용의 어려움은 원본 데이터가 변경될 때 복제본을 최신 상태로 유지해야 한다는 것입니다. 다음에 알아볼 것은 CQRS가 복제본의 동기화 문제를 해결하는 방법입니다.
관심 분리의 필요성
단일 서비스 쿼리를 구현하는 것이 어려운 이유 중 하나는 때로는 데이터 소유 서비스가 쿼리를 구현해서는 안 되는 경우가 있기 때문입니다.
findAvailableRestaurants() 쿼리 작업은 레스토랑 서비스가 소유한 데이터를 검색합니다. 이 서비스는 레스토랑 소유자가 레스토랑 프로필과 메뉴 항목을 관리할 수 있도록 합니다. 레스토랑의 이름, 주소, 요리, 메뉴, 영업 시간을 포함한 다양한 속성을 저장합니다.
서비스가 데이터를 소유하고 있다면, 이 쿼리 작업을 실행하는 것이 합리적으로 보입니다. 하지만 데이터 소유권은 고려해야 할 유일한 요소가 아닙니다.
고려해야 할 또 다른 요소는 관심사를 분리하고 서비스에 너무 많은 책임을 부담시키지 않는 것입니다. 예를 들어, 레스토랑 서비스를 개발하는 팀의 주요 책임은 레스토랑 관리자가 레스토랑을 유지할 수 있도록 하는 것입니다. 이는 고부하이고 중요한 쿼리를 구현하는 것과는 매우 다릅니다.
거기다가, 만일 findAvailableRestaurants() 쿼리 작업을 담당하게 된다면, 팀은 주문 접수를 방해하는 변경사항을 배포할까 봐 끊임없이 두려워하게 될 것입니다.
레스토랑 서비스가 단지 레스토랑 데이터를 제공하고 findAvailableRestaurants() 쿼리 작업을 구현하고 있을 것으로 보이는 다른 서비스에 제공하는 것이 합리적입니다. findOrderHistory() 쿼리 작업을 처리할 때처럼, 지리적 위치 색인을 유지해야 하는 요구 사항이 있을 때, 쿼리를 실행하기 위해 데이터의 최종 일관성 복제를 유지해야 합니다. CQRS를 사용해 그것을 어떻게 달성할 수 있는지 살펴봅시다.
CQRS 개요
이 섹션에서 설명한 예제는 마이크로서비스 아키텍처에서 쿼리를 구현할 때 일반적으로 마주치는 세 가지 문제를 강조했습니다:
- 여러 서비스에 분산된 데이터를 검색하기 위해 API 구성 패턴을 사용하면 비용이 많이 들고 효율적이지 않은 인메모리 조인이 발생합니다.
- 데이터를 소유하는 서비스가 필요한 쿼리를 효율적으로 지원하지 않는 형식이나 데이터베이스에 데이터를 저장합니다.
- 관심을 분리해야 하므로 데이터를 소유하는 서비스가 쿼리 작업을 구현해야 하는 서비스가 아닙니다.
이 세 가지 문제 모두 해결하는 해결책은 CQRS 패턴을 사용하는 것입니다.
CQRS는 명령(Command)을 조회(Query)로부터 분리합니다
CQRS(명령 조회 책임 분리)는 이름에서도 알 수 있듯이 분리 또는 관심사 분리에 관한 것입니다.
다음 그림에서 확인할 수 있듯이, 이것은 영구 데이터 모델을 및 이를 사용하는 모듈을 두 부분, 즉 명령 측면과 조회 측면으로 분할합니다.
명령 측의 모듈과 데이터 모델은 생성, 업데이트 및 삭제 연산을 구현합니다(CUD로 약어됨 - 예: HTTP POST, PUT, DELETE).
쿼리 측면 모듈 및 데이터 모델은 쿼리(예: HTTP GET)를 구현합니다. 쿼리 측면은 명령 측면에서 발행된 이벤트를 구독하여 데이터 모델을 동기화합니다.
성능을 위해 몇 가지 쿼리는 도메인 모델을 우회하고 데이터베이스에 직접 액세스할 수 있습니다. 단일 영구 데이터 모델은 명령과 쿼리를 모두 지원합니다.
CQRS 기반 서비스에서 명령 측면 도메인 모델은 CRUD 작업을 처리하고 별도의 데이터베이스에 매핑됩니다. 또한 비조인, 기본 키 기반 쿼리와 같은 간단한 쿼리를 처리할 수 있습니다.
명령 측면은 데이터가 변경될 때 도메인 이벤트를 발행합니다. 이러한 이벤트는 프레임워크를 사용하거나 이벤트 소싱을 사용하여 발행될 수 있습니다.
비즈니스 규칙을 구현할 책임이 없기 때문에 쿼리 모델은 복잡하지 않은 쿼리를 처리합니다.
쿼리 측면은 해당하는 쿼리를 지원하기 위해 적합한 종류의 데이터베이스를 사용합니다. 쿼리 측면에는 도메인 이벤트에 가입하고 데이터베이스를 업데이트하는 이벤트 핸들러가 있습니다.
CQRS 및 쿼리 전용 서비스
쿼리 서비스는 명령 처리 기능이 없는 쿼리 작업으로 구성된 API를 갖고 있습니다. 다른 하나 이상의 서비스에서 발행된 이벤트에 가입하여 데이터베이스를 업데이트하여 쿼리 작업을 실행합니다.
쿼리 측면 서비스는 여러 서비스에서 발행된 이벤트를 구독하여 구축된 뷰를 구현하는 좋은 방법입니다. 이 종류의 뷰는 특정 서비스에 속하지 않으므로 독립적인 서비스로 구현하는 것이 합리적입니다.
이러한 서비스의 좋은 예시는 주문 기록 서비스입니다. 이 서비스는 findOrderHistory() 쿼리 작업을 구현하는 쿼리 서비스입니다. 그림에서 보듯, 이 서비스는 주문 서비스, 배송 서비스 등 여러 서비스에서 발행된 이벤트를 구독합니다.
주문 기록 서비스에는 여러 서비스에서 발행된 이벤트를 구독하고 주문 기록 뷰 데이터베이스를 업데이트하는 이벤트 핸들러가 있습니다.
쿼리 서비스는 또한 단일 서비스에 의해 소유된 데이터를 복제하는 뷰를 구현하는 좋은 방법입니다. 그러나 관심을 분리해야하는 필요 때문에 해당 서비스의 일부는 아닙니다. 예를 들어 개발자들은 이전에 설명한 findAvailableRestaurants() 쿼리 작업을 구현하는Available Restaurants Service를 정의할 수 있습니다. 이 서비스는 Restaurant Service에서 발행된 이벤트를 구독하고 효율적인 지리적 쿼리를 위해 설계된 데이터베이스를 업데이트합니다.
CQRS는 주로 텍스트 검색 엔진이 아닌 더 넓은 범위의 데이터베이스 유형을 사용한다는 점이 다릅니다. 또한 CQRS 쿼리 측면 뷰는 이벤트를 구독하여 거의 실시간으로 업데이트됩니다.
CQRS의 혜택
CQRS에는 혜택과 단점이 모두 있습니다. 혜택은 다음과 같습니다:
- 마이크로서비스 아키텍처에서 쿼리의 효율적인 구현 가능
- 다양한 쿼리의 효율적인 구현 가능
- 이벤트 소싱 기반 응용 프로그램에서 쿼리 가능
- 관심사 분리 개선
CQRS의 단점들
CQRS에는 몇 가지 이점이 있지만 중요한 단점도 있습니다:
- 더 복잡한 아키텍처
- 복제 지연 처리에 대한 대응
CQRS 뷰 디자인
CQRS(View) 모듈은 하나 이상의 쿼리 작업으로 구성된 API를 가지고 있습니다. 이 모듈은 하나 이상의 서비스에서 발행된 이벤트를 구독하여 유지하는 데이터베이스를 쿼리하여 이러한 쿼리 작업을 구현합니다. 그림에 나와 있는 것처럼, View 모듈은 View 데이터베이스와 세 개의 서브모듈로 구성됩니다.
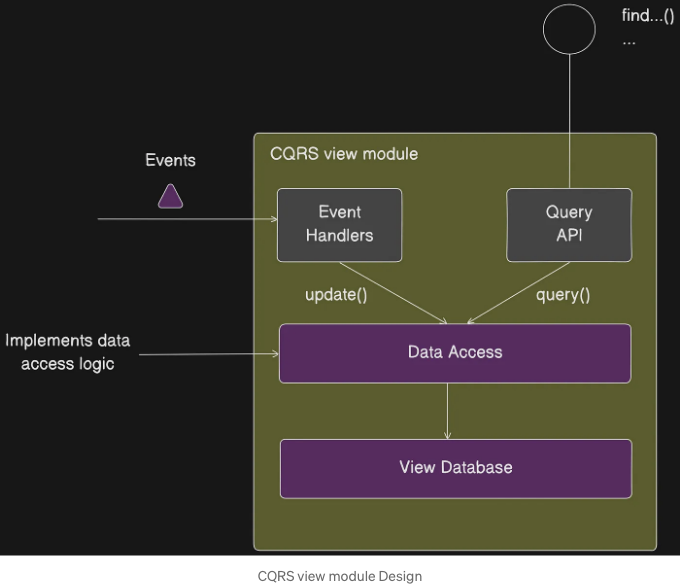
- 데이터 액세스 모듈은 데이터베이스 액세스 로직을 구현합니다.
- 이벤트 핸들러와 쿼리 API 모듈은 데이터 액세스 모듈을 사용하여 데이터베이스를 업데이트하고 쿼리합니다.
- 이벤트 핸들러 모듈은 이벤트를 구독하고 데이터베이스를 업데이트합니다.
- 쿼리 API 모듈은 쿼리 API를 구현합니다.
View 모듈을 개발할 때 중요한 설계 결정을 해야 합니다.
- 데이터베이스를 선택하고 스키마를 설계해야 합니다.
- 데이터 액세스 모듈을 설계할 때, 업데이트가 항등성을 보장하고 동시 업데이트를 처리하는 등 다양한 문제를 해결해야 합니다.
- 기존 애플리케이션에 새로운 뷰를 구현하거나 기존 애플리케이션의 스키마를 변경할 때, 효율적으로 뷰를 구축하거나 다시 구축하는 메커니즘을 구현해야 합니다.
- 이전에 설명한 복제 지연을 처리하는 클라이언트가 뷰를 활용할 수 있도록 결정해야 합니다.
이러한 각 문제를 살펴보겠습니다.
뷰 데이터 저장소 선택
주요 설계 결정은 데이터베이스 선택과 스키마 설계입니다. 데이터베이스와 데이터 모델의 주요 목적은 뷰 모듈의 쿼리 작업을 효율적으로 구현하는 것입니다. 데이터베이스 선택 시 고려해야 할 주요 사항은 해당 쿼리의 특성입니다. 그러나 데이터베이스는 또한 이벤트 처리기가 수행하는 업데이트 작업을 효율적으로 구현해야 합니다.
업데이트 작업 지원
쿼리를 효율적으로 구현하는 것 외에도, 뷰 데이터 모델은 이벤트 핸들러에 의해 실행되는 업데이트 작업을 효율적으로 구현해야 합니다.
보통 이벤트 핸들러는 주 키를 사용하여 뷰 데이터베이스의 레코드를 업데이트하거나 삭제할 것입니다.
그러나 때로는 외래 키의 동등물을 사용하여 레코드를 업데이트하거나 삭제해야 할 수도 있습니다. 예를 들어, 배송 이벤트를 위한 이벤트 핸들러를 고려해보겠습니다. 배송과 주문 간에 일대일 대응이 있다면, Delivery.id가 Order.id와 동일할 수 있습니다. 그렇다면 Delivery 이벤트 핸들러는 주문 데이터베이스 레코드를 쉽게 업데이트할 수 있습니다.
그렇다면 Delivery에 자체 기본 키가 있는 경우나 주문과 Delivery 사이에 일대다 관계가 있는 경우를 가정해 봅시다. Delivery 이벤트 중 DeliveryCreated 이벤트와 같은 경우에는 orderId가 포함될 것입니다. 그러나 DeliveryPickedUp 이벤트와 같은 다른 이벤트는 그렇지 않을 수 있습니다. 이러한 시나리오에서 DeliveryPickedUp 이벤트의 이벤트 핸들러는 외래 키와 같은 역할을 하는 deliveryId를 사용하여 주문 레코드를 업데이트해야 합니다.
데이터 액세스 모듈 디자인
이벤트 핸들러와 쿼리 API 모듈은 직접 데이터 저장소에 액세스하지 않습니다. 대신, 데이터 액세스 모듈을 사용하며, 이는 데이터 액세스 객체(DAO)와 해당 도우미 클래스로 구성되어 있습니다. DAO에는 여러 책임이 있습니다. 이는 이벤트 핸들러에 의해 호출되는 업데이트 작업을 구현하고 쿼리 모듈에 의해 호출되는 쿼리 작업을 구현합니다.
DAO는 상위 수준 코드에서 사용되는 데이터 유형과 데이터베이스 API 간의 매핑을 담당합니다. 또한 동시 업데이트를 처리하고 업데이트가 멱등성을 보장해야 합니다.
이러한 문제를 살펴보며 동시 업데이트를 어떻게 처리할지부터 시작해 봅시다.
동시성 처리
가끔 DAO는 동일한 데이터베이스 레코드에 대해 여러 동시 업데이트 가능성을 처리해야 할 수도 있습니다. 한 뷰가 단일 집계 유형에서 발행된 이벤트를 구독하는 경우 동시성 문제가 발생하지 않습니다. 그 이유는 특정 집계 인스턴스에서 발행된 이벤트가 순차적으로 처리되기 때문입니다.
결과적으로 집계 인스턴스에 해당하는 레코드는 동시에 업데이트되지 않습니다. 그러나 한 뷰가 여러 집계 유형에서 발행된 이벤트를 구독하는 경우 여러 이벤트 핸들러가 동시에 동일한 레코드를 업데이트할 수 있습니다.
예를 들어, 주문 이벤트의 이벤트 핸들러가 동일한 주문에 대한 배송 이벤트의 이벤트 핸들러와 동시에 호출될 수 있습니다. 그럼 두 이벤트 핸들러가 동시에 DAO를 호출하여 해당 주문의 데이터베이스 레코드를 업데이트합니다.
IDEMPOTENT EVENT HANDLERS
이벤트 핸들러는 동일한 이벤트를 여러 번 호출할 수 있습니다. 이는 쿼리 측 이벤트 핸들러가 멱등성을 갖는 경우 일반적으로 문제가 되지 않습니다. 이벤트 핸들러가 멱등성을 가지면 중복 이벤트를 처리해도 올바른 결과를 얻을 수 있습니다. 최악의 경우에도 뷰 데이터 저장소는 임시로 최신 상태를 유지하지 못할 수 있습니다.
예를 들어, 주문 내역 뷰를 유지하는 이벤트 핸들러는 (사실상 희박한) 아래 이벤트 순서를 처리할 수 있습니다: DeliveryPickedUp, DeliveryDelivered, DeliveryPickedUp, 그리고 DeliveryDelivered.
DeliveryPickedUp 및 DeliveryDelivered 이벤트를 처음 처리한 후에도, 메시지 브로커가 네트워크 오류로 인해 이전 시점부터 이벤트를 다시 전달할 수 있기 때문에 DeliveryPickedUp 및 DeliveryDelivered를 다시 전달할 수 있습니다.
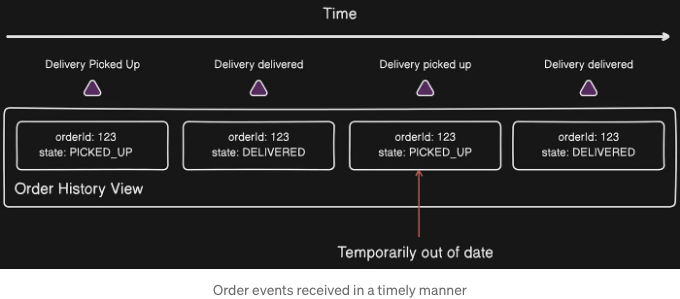
이벤트 핸들러가 두 번째 DeliveryPickedUp 이벤트를 처리한 후에, 주문 이력 뷰에는 DeliveryDelivered이 처리될 때까지 주문의 오래된 상태가 일시적으로 포함됩니다. 이러한 동작이 원치 않은 경우, 이벤트 핸들러는 비멱등한 이벤트 핸들러처럼 중복 이벤트를 탐지하고 버려야 합니다.
예를 들어, 은행 계좌 잔액을 증가시키는 이벤트 핸들러는 멱등성을 가지지 않습니다. 비멱등한 이벤트 핸들러는 처리된 이벤트의 ID를 뷰 데이터 저장소에 기록하여 중복 이벤트를 탐지하고 버려야 합니다. 이벤트 핸들러가 신뢰할 수 있게 작동하려면 이벤트 ID를 기록하고 데이터 저장소를 원자적으로 업데이트해야 합니다.
이것을 수행하는 방법은 데이터베이스의 유형에 따라 다릅니다. 뷰 데이터베이스 저장소가 SQL 데이터베이스인 경우, 이벤트 핸들러는 뷰를 업데이트하는 트랜잭션의 일부로 처리된 이벤트를 PROCESSED_EVENTS 테이블로 삽입할 수 있습니다. 그러나 제한된 트랜잭션 모델을 가진 NoSQL 데이터베이스인 경우, 이벤트 핸들러는 업데이트하는 데이터 저장소 "레코드" (예: MongoDB 문서 또는 DynamoDB 테이블 아이템)에 이벤트를 저장해야 합니다.
중요한 점은 이벤트 핸들러가 모든 이벤트의 ID를 기록할 필요가 없다는 것입니다. 이벤트가 단조로운 증가하는 ID를 가지고 있다면, 각 레코드는 주어진 집합 인스턴스에서 받은 max(eventId)만 저장하면 됩니다.
또한, 레코드가 단일 집합 인스턴스에 해당하는 경우, 이벤트 핸들러는 max(eventId)만 기록하면 됩니다. 여러 집합에서 이벤트 조인을 나타내는 레코드만 [집합 유형, 집합 ID]에서 max(eventId)로의 맵을 포함해야 합니다.
이벤트 최종 일관성 뷰를 사용할 수 있게 하기
이전에 말한 대로, CQRS를 사용할 때의 문제 중 하나는 명령 측면을 업데이트하는 클라이언트가 질의를 즉시 실행하더라도 자신의 업데이트를 볼 수 없을 수 있다는 것입니다. 메시징 인프라의 불가피한 지연으로 인해 뷰는 최종적으로 일관성을 갖습니다. 명령 및 질의 모듈 API는 클라이언트가 다음 접근 방식을 이용하여 불일치를 감지할 수 있도록 할 수 있습니다. 명령 측면 작업은 클라이언트에게 게시된 이벤트의 ID를 포함한 토큰을 반환합니다.
고객은 그런 다음 해당 이벤트로 업데이트되지 않은 경우에 오류를 반환하는 질의 작업에 토큰을 전달합니다. 뷰 모듈은 중복 이벤트 감지 메커니즘을 사용하여 이 메커니즘을 구현할 수 있습니다.
이런 종류의 문제를 다루는 다양한 방법이 있으나 이 블로그 글의 범위를 벗어나므로 분산 시스템에서 최종적 일관성을 다루는 방법에 대한 자세한 정보는 다음 글을 참고하십시오:
CQRS 뷰 추가 및 업데이트
CQRS 뷰는 애플리케이션의 수명 동안 추가 및 업데이트됩니다. 때로는 새 쿼리를 지원하기 위해 새로운 뷰를 추가해야 할 수도 있습니다. 다른 때에는 스키마가 변경되었거나 뷰를 업데이트하는 코드에서 버그를 수정해야 할 수도 있습니다.
뷰를 추가하고 업데이트하는 것은 개념적으로 매우 간단합니다. 새로운 뷰를 만들려면 쿼리 측 모듈을 개발하고 데이터 저장소를 설정하고 서비스를 배포하면 됩니다. 쿼리 측 모듈의 이벤트 핸들러가 모든 이벤트를 처리하고 결국 뷰가 최신 상태가 됩니다. 마찬가지로 기존 뷰를 업데이트하는 것도 개념적으로 간단합니다: 이벤트 핸들러를 변경하고 뷰를 처음부터 다시 빌드하면 됩니다. 그러나 이 방법이 실제로 작동할 가능성은 낮습니다. 문제점을 살펴보겠습니다.
아카이브된 이벤트를 사용하여 CQRS 뷰 빌드하기
하나의 문제는 메시지 브로커가 메시지를 무한히 저장할 수 없다는 것입니다. RabbitMQ와 같은 전통적인 메시지 브로커는 소비자에 의해 처리된 메시지를 한 번 삭제합니다. Mq산ㄴ바 Kafka와 같은 더 현대적인 브로커도 구성 가능한 보존 기간 동안 메시지를 유지하지만 이벤트를 무기한으로 저장할 목적은 아닙니다. 결과적으로 메시지 브로커에서 필요한 모든 이벤트를 읽기만으로 뷰를 빌드할 수는 없습니다.
이외에도 앱은 예를 들어 AWS S3에 아카이브된 이전 이벤트를 읽어들일 수 있어야 합니다. 이를 위해서 Apache Spark와 같은 확장 가능한 빅데이터 기술을 사용할 수 있습니다.
점진적으로 CQRS 뷰 작성하기
뷰를 생성하는 데 또 다른 문제는 시간과 리소스가 성장함에 따라 모든 이벤트를 처리하는 데 필요한 시간이 계속 증가한다는 것입니다. 결국, 뷰 작성이 너무 느려지고 비쌉니다. 해결책은 두 단계의 점진적 알고리즘을 사용하는 것입니다.
- 첫 번째 단계는 주기적으로 각 집계 인스턴스의 스냅샷을 이전 스냅샷과 해당 스냅샷이 생성된 이후 발생한 이벤트를 기반으로 계산합니다.
- 두 번째 단계는 스냅샷과 이후 이벤트를 사용하여 뷰를 생성합니다.
결론
분산 시스템에서 질의와 같이 보이는 간단한 작업들을 구현하는 것은 전통적인 단일체 아키텍처보다 훨씬 더 어려울 수 있습니다. 이 블로그 게시물에서는 마이크로서비스 아키텍처 내에서 질의를 구현하는 다양한 방법을 탐색하면서 특히 Composition API 및 CQRS 패턴에 초점을 맞췄습니다.
Composition API의 한계를 살펴본 후에 더 복잡한 질의를 다루는 대체 접근 방식으로 CQRS 패턴에 대한 논의를 진행했습니다. CQRS와 관련된 어려움을 다루고 이러한 어려움을 완화하기 위한 해결책을 제안하며 마무리했습니다.
실제 시나리오에서는 질의의 구체적인 요구 사항을 정확히 이해하여 가장 적합한 구현 패턴을 선택하는 것이 핵심입니다. 이러한 요소를 신중하게 고려함으로써 선택한 방법이 시스템의 요구 사항을 효과적으로 충족할 수 있도록 할 수 있습니다.
참고 자료
- Microservices Patterns — Chris Richardson
- Building Microservices: Designing Fine-Grained Systems 2nd Edition — Sam Newman