데이터 분석가가 알아야 할 상위 10가지 엔지니어링 교훈
데이터 분석가는 다양한 영역의 기술을 결합해야 합니다:
- 실제 비즈니스 문제를 해결하고 모든 세부 사항을 고려할 수 있도록 비즈니스 이해와 도메인 지식이 필요합니다.
- 수학, 통계 및 기본적인 머신러닝 기술을 보유하여 데이터로부터 신속하고 신뢰할 수 있는 결론을 도출합니다.
- 시각화 기술과 스토리텔링은 메시지를 전달하고 제품에 영향을 미칠 수 있게 합니다.
- 마지막으로, 컴퓨터 과학과 소프트웨어 엔지니어링의 기본 지식이 효율성의 핵심입니다.
대학에서 컴퓨터 과학에 대해 많은 것을 배웠습니다. 저는 최소 12개 이상의 프로그래밍 언어(저수준 어셈블러 및 CUDA부터 고수준 Java 및 Scala까지)와 무수한 도구를 시도해 보았습니다. 제 첫 직장 제안은 백엔드 엔지니어 역할이었습니다. 저는 이 경로를 추구하지 않기로 결정했지만, 이 모든 지식과 원칙이 저의 분석 경력에 유익했습니다. 그래서 이 글에서 이러한 주요 원칙을 여러분과 공유하고 싶습니다.
Code is not for computers. It’s for people
I’ve heard this mantra from software engineers several times. This philosophy is well articulated in one of the foundational texts in programming, “Clean Code”.
Typically, engineers favor verbose code that is clear and easy to comprehend over concise, one-line solutions.
I must admit, occasionally I'm guilty of breaking this rule by creating overly long one-liners with pandas. For instance, take a look at the code snippet below. Can you decipher what it's accomplishing?
ad-hoc only code
df.groupby(['month', 'feature'])[['user_id']].nunique()
.rename(columns={'user_id': 'users'})
.join(df.groupby(['month'])[['user_id']].nunique()
.rename(columns={'user_id': 'total_users'})).apply(
lambda x: 100*x['users']/x['total_users'], axis=1)
.reset_index().rename(columns={0: 'users_share'})
.pivot(index='month', columns='feature', values='users_share')
이건 솔직히 한 달 안에 이 코드를 숙지하는 데 시간이 좀 걸릴 것 같아요. 이 코드를 더 읽기 쉽게 만들기 위해 단계별로 나눠보겠습니다.
maintainable code
monthly_features_df = df.groupby(['month', 'feature'])[['user_id']].nunique()
.rename(columns={'user_id': 'users'})
monthly_total_df = df.groupby(['month'])[['user_id']].nunique()
.rename(columns={'user_id': 'total_users'})
monthly_df = monthly_features_df.join(monthly_total_df).reset_index() monthly_df['users_share'] = 100*monthly_df.users/monthly_df.total_users
monthly_df.pivot(index='month', columns='feature', values='users_share')
이제 코드가 논리를 따라가기 쉬워졌을 텐데요. 이 코드는 매달 각 기능을 사용하는 고객의 비율을 보여줍니다. 미래의 나는 분명 이렇게 깔끔한 코드를 볼 때 더 행복해할 거에요. 모든 노력에 감사드립니다.
반복되는 작업 자동화하기
만약 자주 반복하는 지루한 작업이 있다면, 자동화를 고려해보는 것이 좋습니다. 저의 경험에서 몇 가지 예를 공유해드릴게요.
분석가들이 작업을 자동화하는 가장 흔한 방법은 매번 수동으로 숫자를 계산하는 대신 대시보드를 만드는 것입니다. 이러한 Self-serve 도구들(스테이크홀더들이 필터를 변경하고 데이터를 조사할 수 있는 구성 가능한 대시보드)은 많은 시간을 절약하고 더 정교하고 영향력 있는 연구에 집중할 수 있게 해줍니다.
대시보드가 선택지가 아니라면, 다른 자동화 방법도 있습니다. 저는 주간 보고서를 작성하고 이를 이메일로 이해 관계자들에게 보내고 있었어요. 시간이 지날수록 꽤 지루한 작업이 되었고, 자동화에 대해 생각하기 시작했어요. 이때 가장 기본적인 도구인 가상 머신의 cron을 사용했어요. 최신 숫자를 계산하고 이메일을 보내는 파이썬 스크립트를 스케줄했습니다.
스크립트가 있다면 크론 파일에 한 줄만 추가하면 됩니다. 예를 들어, 아래의 라인은 매주 월요일 오전 9시 10분에 analytical_script.py를 실행합니다.
10 9 * * 1 python analytical_script.py
크론은 기본적이지만 여전히 지속 가능한 해결책입니다. 스크립트를 예약하기 위해 사용할 수 있는 다른 도구로는 Airflow, DBT 및 Jenkins가 있습니다. Jenkins를 CI/CD(지속적 통합 및 지속적 전달) 도구로 알고 있는 경우가 많을 것입니다. 놀랄 수도 있지만 분석 스크립트를 실행하는 데 충분히 사용자 정의할 수 있습니다.
더 많은 유연성이 필요하다면 웹 응용 프로그램을 고려해 보는 것이 좋습니다. 처음으로 소속된 팀에서 A/B 테스트 도구가 없었기 때문에 분석가들은 각 업데이트를 수동으로 분석해야 했습니다. 마침내, 엔지니어들이 스스로 이용할 수 있는 Flask 웹 응용 프로그램을 작성했습니다. 지금은 Gradio나 Streamlit과 같은 가벼운 웹 애플리케이션 솔루션이 있어서 몇 일 안에 배울 수 있습니다.
도구를 능숙하게 다루세요
매일 업무에서 사용하는 도구들은 작업 효율과 최종 결과물에 상당한 영향을 미칩니다. 그래서 그 도구들을 능숙하게 다루는 것이 중요합니다.
물론, 코드를 작성하기 위해 기본 텍스트 편집기를 사용할 수 있지만, 대부분의 사람들은 IDEs(통합 개발 환경)를 사용합니다. 당신은 이 응용 프로그램을 많은 시간동안 사용하게 될 것이므로 선택지를 평가할 가치가 있습니다.
가장 인기 있는 Python용 IDEs를 JetBrains의 2021 설문 조사에서 찾아볼 수 있습니다.
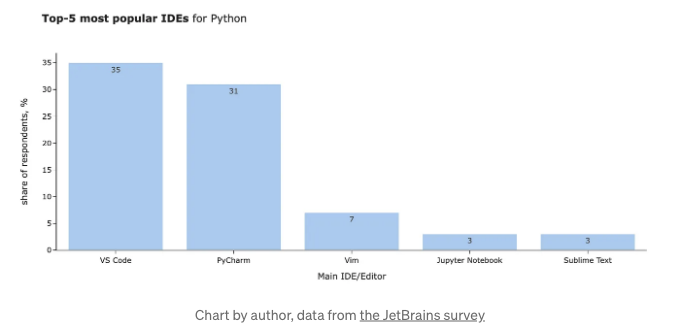
안녕하세요! 저는 평소에 파이썬과 주피터 노트북을 주로 활용하는데요. 내 생각에 이 작업들에 최적화된 IDE는 주피터랩입니다. 하지만 AI 어시스턴트를 활용하기 위해 다른 옵션들을 시험 중이에요. 보일러플레이트 코드를 줄여주는 자동 완성 기능은 저에게는 귀중한데, 이를위한 전환이 필요할지라도 빠르게 채택하고 싶네요. 다양한 옵션을 살펴보고 여러분의 작업에 가장 잘 맞는 것을 찾아보는 걸 장려해요.
더불어 도움이 되는 한 가지 팁은 바로 바로 가기 키(shortcuts)에요. 마우스보다는 바로가기 키를 활용하면 작업을 빠르게 처리할 수 있을 뿐만 아니라 멋있게 보일 수도 있어요. 가장 많이 사용하는 도구인만큼, IDE의 바로 가기 키를 구글링해서 시작하는 것을 추천해요. 제가 실무에서 가장 유용하게 사용하는 명령어는 주피터 노트북에서 새 셀을 생성하는 것, 해당 셀을 실행하는 것, 삭제하는 것, 그리고 마크다운으로 변환하는 것이에요.
다른 자주 사용하는 도구(예: 구글 시트 또는 슬랙)가 있다면, 해당 도구를 위한 명령어도 학습해보세요. 함께 작업하는 다른 도구들을 더욱 효과적으로 활용할 수 있을 거예요.
핵심은 바로 '연습, 연습, 연습'입니다. 이를 반복해 100번 정도 한 후에야 자동으로 사용할 수 있게 됩니다. 심지어 당신을 단축키를 더 많이 사용하도록 장려하는 플러그인도 있습니다 (예를 들어, JetBrains의 이 플러그인이 있습니다).
마지막으로 CLI (Command-Line Interface)가 있습니다. 처음에는 겁을 먹을 수 있지만, CLI에 대한 기본 지식을 가지는 것은 일반적으로 좋은 결과를 가져다 줍니다. 저는 GitHub를 다룰 때조차 정확히 어떤 일이 일어나고 있는지 명확히 이해할 수 있도록 CLI를 사용합니다.
그러나 원격 서버에서 작업할 때와 같이, CLI를 사용하지 않을 수 없는 상황도 있습니다. 서버와 자신있게 상호작용하려면 10개 미만의 명령어를 익혀야 합니다. 이 기사는 당신이 CLI에 대해 기본적인 지식을 얻는 데 도움이 될 수 있습니다.
환경을 관리하세요
좋은 도구를 이어 이야기해보면, 환경을 설정하는 것은 항상 좋은 아이디어입니다. 저는 일상적인 작업에 사용하는 모든 라이브러리가 포함된 Python 가상 환경을 갖고 있어요.
새로운 가상 환경을 만드는 것은 터미널에서 몇 줄의 코드로 매우 쉽습니다 (CLI를 시작하는 좋은 기회이기도 해요).
# 가상 환경 생성
python -m venv routine_venv
# 가상 환경 활성화
source routine_venv/bin/activate
# 필요한 모든 패키지 설치
pip install pandas plotly
# 주피터 노트북 시작
jupyter notebook
이 환경에서 주피터를 시작하거나 IDE에서 사용할 수 있어요.
큰 프로젝트를 위한 별도 환경을 유지하는 것이 좋은 습관입니다. 일반적으로 저는 PyTorch나 새로운 LLM 프레임워크 같은 특이한 스택이 필요하거나 라이브러리 호환성 문제가 발생했을 때에만 이렇게 합니다.
환경을 저장하는 다른 방법은 Docker 컨테이너를 사용하는 것입니다. 저는 이를 주로 서버에서 실행되는 웹 앱과 같이 조금 더 프로덕션 환경과 유사한 것에 사용합니다.
프로그램 성능에 대해 고민해 보세요
솔직히 말해서, 분석가들은 종종 성능에 대해 크게 고려할 필요가 없습니다. 데이터 분석 분야에서 첫 직장을 얻었을 때, 제 리더가 실용적인 성능 최적화 방법을 공유해 주었고, 그 이후로 그 방법을 계속 사용해 왔습니다. 성능에 대해 고려할 때, 총 시간 대비 노력을 고려해 보세요. 예를 들어, 4시간 동안 실행되는 MapReduce 스크립트가 있다고 가정해 봅시다. 이를 최적화해야 할까요? 정답은 시기에 따라 다릅니다.
- 한두 번 실행할 일이라면 단 하루를 투자해 스크립트를 최적화하는 것은 그리 의미가 없을 것입니다.
- 매일 실행할 계획이라면 프로그램을 빨리 실행시키고 컴퓨팅 자원 (그리고 돈) 낭비하는 것을 멈추는 노력을 해볼 가치가 있습니다.
제 작업의 대다수가 일회성 연구인 점을 감안하면 보통은 코드를 최적화할 필요가 없습니다. 그러나 몇 시간을 기다릴 필요는 없도록 하는 몇 가지 기본적인 규칙은 따르는 것이 가치가 있습니다. 작은 꿍이 큰 결과로 이어질 수 있습니다. 이와 관련한 한 예를 살펴보겠습니다.
기초부터 시작해서, 성능의 중요한 요소는 빅 오 표기법입니다. 간단히 말해, 빅 오 표기법은 실행 시간과 작업하는 요소의 수 사이의 관골을 보여줍니다. 그래서 만약 내 프로그램이 O(n)이면, 데이터 양을 10배로 증가시킨다면 실행 시간도 대략 10배가 걸릴 것입니다.
코드를 작성할 때, 알고리즘의 복잡성과 주요 데이터 구조를 이해하는 것이 가치가 있습니다. 예를 들어, 요소가 목록에 있는지 찾는 것은 O(n) 시간이 걸리지만, 집합에서는 단 한 번의 계산으로 처리됩니다. 어떻게 이것이 우리 코드에 영향을 미칠 수 있는지 살펴볼까요.
Q1과 Q2 사용자 거래 내역이 담긴 2개의 데이터 프레임을 가지고 있습니다. Q1 데이터 프레임의 각 거래에 대해 해당 고객이 유지되었는지 확인하고 싶습니다. 데이터 프레임은 상대적으로 작은 규모로, 약 30-40만 개의 행이 있습니다.
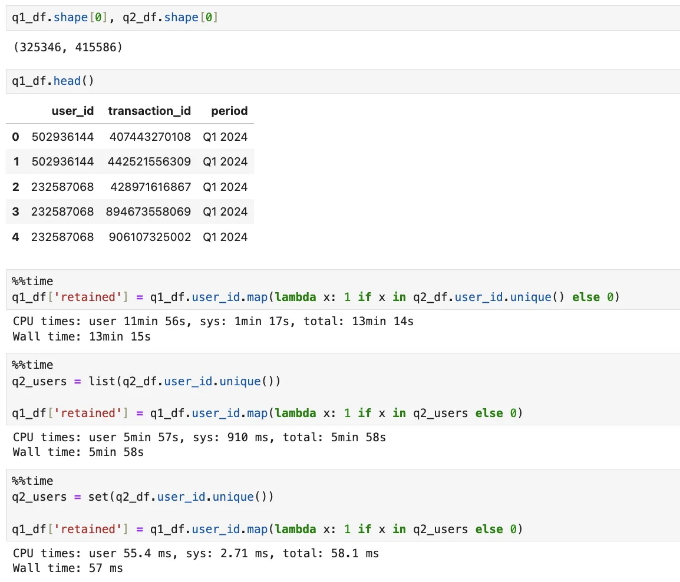
성능이 많이 다른 걸 보실 수 있습니다.
- 첫 번째 방법은 각 반복마다(Q1 데이터 세트의 각 행 별) 고유한 사용자 ID 목록을 계산하고, 해당 목록에서 O(n) 복잡도로 요소를 찾습니다. 이 작업은 13분이 소요됩니다.
- 미리 목록을 계산하는 두 번째 방법은 조금 나아졌지만, 여전히 거의 6분이 걸립니다.
- 사용자 ID 목록을 미리 계산하고 세트로 변환하면 순식간에 결과를 얻을 수 있습니다.
마음가짐을 가져보세요! 기본 지식만으로도 코드를 10,000배 이상 빠르게 만들 수 있다고요. 이것은 게임 체인저입니다.
또 다른 일반적인 조언은 순수한 파이썬 대신 판다스나 넘파이와 같은 성능이 우수한 데이터 구조를 선호하는 것입니다. 이러한 라이브러리들은 C에 구현된 배열에 대한 벡터화된 연산을 사용하기 때문에 빠르게 동작합니다. 일반적으로 판다스가 넘파이 위에 만들어졌지만 약간 더 효율적인 결과를 보여줄 수 있는데요, 판다스가 넘파이 위에 만들어졌지만 약간 더 효율적인 결과를 보여줄 수 있는데요, 어느 정도 부가 기능이 추가되어 성능이 조금 떨어지기 때문입니다.
DRY 규칙을 잊지 마세요.
DRY는 "Don't Repeat Yourself"의 약자로, 말 그대로 반복하지 말라는 원칙입니다. 이 규칙은 쉽게 재사용할 수 있는 구조화된 모듈식 코드를 찬양합니다.
만약 코드 덩어리를 세 번째로 복사하여 붙여넣기하고 있다면, 코드 구조를 고려하고 이 논리를 캡슐화하는 방법을 생각해보아야 합니다.
표준 데이터 분석 작업은 데이터 가공이며, 보통 절차적 패러다임을 따릅니다. 그래서 코드를 구조화하는 가장 분명한 방법은 함수를 사용하는 것입니다. 하지만 객체 지향 프로그래밍을 따를 수도 있고, 이전 글에서는 시뮬레이션에 대한 객체 지향 접근의 예를 공유했습니다.
모듈식 코드의 장점은 더 나은 가독성, 빠른 개발 및 쉬운 변경입니다. 예를 들어, 시각화를 라인 차트에서 영역 플롯으로 변경하고 싶다면, 한 곳에서 변경하고 코드를 다시 실행할 수 있습니다.
특정 도메인과 관련된 일련의 함수가 있다면, 해당 기능을 다른 Python 라이브러리처럼 상호 작용할 수 있도록하기 위해 Python 패키지를 만들 수 있습니다. 이를 수행하는 방법에 대한 자세한 가이드는 여기에서 확인할 수 있습니다.
레버리지 테스트
내가 생각하기에 분석 세계에서 가치가 충분히 인정받지 못한 또 다른 주제는 테스트입니다. 소프트웨어 엔지니어들은 테스트 커버리지에 대한 KPI를 종종 갖고 있습니다. 이는 분석가에게도 유용할 수 있습니다. 그러나 많은 경우, 우리의 테스트는 코드 자체보다는 데이터와 관련이 있을 수 있습니다.
제 동료 중 한 명으로부터 배운 꿀팁은 데이터의 최신 상태에 대한 테스트를 추가하는 것입니다. 우리는 분기별 및 연간 보고서를 단기간에 실행하는 여러 스크립트를 가지고 있었습니다. 그래서 그가 테이블의 최신 행이 보고 기간이 끝난 이후에 있는지 확인하는 체크를 추가했습니다(테이블이 업데이트되었는지 보여줍니다). 파이썬에서는 이를 위해 assert 문을 사용할 수 있습니다.
assert last_record_time >= datetime.date(2023, 5, 31)
만약 조건이 충족되면 아무 일도 일어나지 않습니다. 그렇지 않으면 AssertionError가 발생합니다. 이는 문제를 빨리 발견할 수 있는 빠르고 쉬운 확인 작업입니다.
다른 것으로 검증하는 것은 합계 통계입니다. 예를 들어 데이터를 분할, 가공 및 변환하는 경우 전체 요청 및 메트릭 수가 동일한지 확인하는 것이 좋습니다. 일반적인 실수로는 다음과 같은 것들이 있습니다:
- 조인으로 인해 발생한 중복,
- pandas.groupby 함수를 사용할 때 None 값을 필터링한 경우,
- 내부 조인으로 인해 차원이 필터링된 경우.
또한, 중복 데이터를 항상 검사합니다. 각 행이 각각의 사용자를 나타낼 것으로 예상하는 경우, 행의 수는 df.user_id.nunique() 와 동일해야 합니다. 만약 일치하지 않으면 데이터에 문제가 있으며 조사가 필요합니다.
가장 까다로우면서도 유용한 테스트는 의미 체크입니다. 이에 대한 몇 가지 가능한 접근 방식에 대해 논의해보겠습니다.
- 먼저, 결과가 전반적으로 타당한지 확인해야 합니다. 예를 들어, 1개월 보유율이 99%이거나 유럽에서 10억 명의 고객을 확보했다면 코드에 버그가 있을 가능성이 높습니다.
- 둘째, 결과가 타당한지 검증하기 위해 다른 데이터 소스나 이전 연구 자료를 찾아볼 것입니다.
- 유사한 연구 자료가 없는 경우(예를 들어, 새 시장에 제품을 출시한 후 잠재적인 수익을 추정하는 경우)에는 다른 기존 세그먼트의 수치와 비교하는 것이 좋습니다. 예를 들어, 새로운 시장에 제품을 출시한 후 수익에 미치는 추가 효과가 현재 수입의 5배인 경우, 너무 낙관적이라고 판단하고 가정을 재검토하는 것이 좋습니다.
이 마인드셋이 보다 타당한 결과를 얻는 데 도움이 되길 바라겠습니다.
팀원들에게 버전 관리 시스템 사용을 권장합니다.
공학자들은 혼자 작업하는 작은 프로젝트라도 버전 관리 시스템을 사용합니다. 한편으로, 분석가들이 쿼리를 저장하기 위해 Google Sheets를 사용하는 것을 종종 볼 수 있습니다. 모든 코드를 저장소에 유지하는 것을 적극적으로 지지하고 옹호하는 저의 생각을 여기에 공유하는 기회를 놓칠 수 없겠네요.
저는 10년 이상의 데이터 경력 동안 왜 저장소를 사용해 왔을까요? 주요 이점은 다음과 같습니다:
- 재현성. 이전 연구를 조정해야 할 때가 많습니다 (예: 하나의 차원을 추가하거나 연구를 특정 세그먼트로 좁힘). 코드를 구조화된 방식으로 저장하면 이전 작업을 빠르게 재현할 수 있습니다. 대게 많은 시간을 절약할 수 있죠.
- 투명성. 코드를 연구 결과에 링크시키면 동료들이 방법론을 세밀하게 이해하고 더 많은 신뢰를 가져다 줍니다. 또한 버그나 개선 사항을 쉽게 파악할 수 있게 도와줍니다.
- 지식 공유. 쉽게 탐색 가능한 카탈로그를 가지고 있다면 (또는 코드를 작업 추적기에 링크한다면), 동료들이 코드를 빠르게 찾아 처음부터 조사를 시작하지 않게 해줍니다.
- 되돌리기. 어제 잘 작동하던 코드가 오늘 변경 후 완전히 망가진 적이 있나요? 정기적으로 코드를 커밋하기 시작하기 전까지 그렇게 여러 번 경험했죠. 버전 관리 시스템을 통해 전체 버전 히스토리를 확인하고 코드를 비교하거나 이전에 작동했던 버전으로 되돌릴 수 있습니다.
- 협업. 다른 사람들과 협업하여 코드를 작업하는 경우, 버전 관리 시스템을 활용하여 변경 사항을 추적하고 병합할 수 있습니다.
지금 잠재적 이점을 확인하실 수 있기를 바랍니다. 이제 코드를 저장하는 제 평범한 설정을 간단히 공유해드리겠습니다:
- 저는 버전 관리 시스템으로 git + Github를 사용합니다. 아직 명령줄 인터페이스를 사용하는 고대의 열사이며(제게 느는 것을 느끼게 해줘서 좋아요), 당신은 GitHub 앱이나 IDE의 기능을 사용할 수 있습니다.
- 대부분의 작업은 연구(코드, 숫자, 차트, 주석 등)이기 때문에 코드의 95%를 Jupyter Notebook으로 저장합니다.
- 코드를 Jira 티켓에 연결합니다. 일반적으로 저장소에 작업 폴더를 두고 하위 폴더를 티켓 키로 지정합니다(예: ANALYTICS-42). 그런 다음, 이 하위 폴더에 해당 작업과 관련된 모든 파일을 배치합니다. 이러한 방식으로 (거의) 어떤 작업에 대한 코드도 몇 초 안에 찾을 수 있습니다.
GitHub에서 Jupyter Notebook을 사용할 때 주목할 만한 세세한 점이 몇 가지 있습니다.
먼저, 출력에 대해 고려해보세요. Jupyter Notebook을 저장소에 커밋할 때 입력 셀(코드 또는 주석)과 출력을 모두 저장합니다. 따라서 실제로 출력을 공유하고 싶은지 여부를 신중하게 고려하는 것이 좋습니다. 개인 정보 노출이 포함될 수도 있으며, 다른 민감한 데이터가 포함될 수도 있기 때문에 커밋하는 것을 권장하지 않습니다. 또한, 출력물은 상당히 크고 정보가 없는 경우가 많아서 저장소를 그저 난잡하게 만들 수 있습니다. 무작위 데이터 출력이 포함된 10MB 이상의 Jupyter Notebook을 저장할 때, 모든 동료가 git pull 명령을 통해 자신의 컴퓨터로 이 데이터를 불러오게 될 것입니다.
출력물에 있는 차트는 특히 문제가 될 수 있습니다. 우리는 모두 인터랙티브한 Plotly 차트를 좋아합니다. 불행히도 GitHub UI에서는 렌더링되지 않으므로 동료들이 보기 쉽지 않을 것입니다. 이 장애물을 극복하기 위해 Plotly의 출력 유형을 PNG 또는 JPEG로 변경할 수 있습니다.
import plotly.io as pio
pio.renderers.default = "jpeg"
Plotly 렌더러에 대한 자세한 내용은 문서에서 확인할 수 있어요.
마지막으로, Jupyter 노트북의 차이점은 종종 까다로울 수 있어요. 코드의 2가지 버전 간의 차이를 이해하고 싶을 때가 많아요. 그러나 기본 GitHub 뷰에서는 노트북 메타데이터의 변경으로 인해 정보가 혼란스럽게 표시될 수 있어요 (아래 예시와 같이).
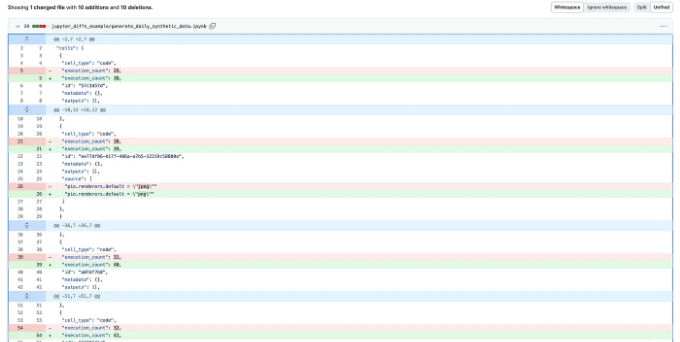
실제로 GitHub가 이 문제를 거의 해결했습니다. 기능 미리보기에서 다양한 차이점 기능을 활성화하면 쉽게 해결할 수 있어요. 설정에서 활성화만 시키면 됩니다.
With this feature, we can easily see that there were just a couple of changes. I’ve changed the default renderer and parameters for retention curves (so a chart has been updated as well).
코드 리뷰 요청
개발자들은 코드 변경 사항에 대해 (거의) 모두 동료 리뷰를 합니다. 이 과정을 통해 버그를 일찍 발견하거나 나쁜 행위자를 막아주며 팀 간 지식을 효과적으로 공유할 수 있습니다.
물론, 이것이 모든 문제를 해결해 주는 마법처럼 작용하는 것은 아닙니다. 리뷰어들이 버그를 놓치거나 나쁜 행위자가 인기 있는 오픈 소스 프로젝트에 침입을 가능하게 할 수도 있습니다. 예를 들어, 인기 있는 리눅스 배포판에서 널리 사용되는 압축 도구에 배후문이 심어졌다는 무서운 이야기가 있었죠.
하지만, 코드 리뷰가 실제로 도움이 된다는 증거가 있습니다. 맥커넬은 자신의 대표적인 책인 "Code Complete"에서 다음과 같은 통계를 공유합니다.
이 모든 이점에도 불구하고, 분석가들은 종종 코드 리뷰를 전혀 사용하지 않습니다. 왜 도전적일 수 있는지 이해할 수 있습니다:
- 분석 팀은 보통 작은 규모이며 이중 확인에 제한된 리소스를 사용하는 것은 합리적으로 들리지 않을 수 있습니다.
- 종종 분석가들은 서로 다른 도메인에서 작업하며, 도메인을 충분히 잘 알아야 하는 유일한 사람이 되는 경우가 있습니다.
하지만, 중요한 사항에 대해 코드 리뷰를 권장합니다. 여기 제가 동료들에게 코드와 가정을 이중으로 확인해 줄 것을 요청하는 경우입니다:
- 새로운 도메인에서 데이터를 사용할 때, 사용된 가정을 검토할 전문가에게 물어보는 것이 항상 좋은 아이디어입니다;
- 고객과의 소통 또는 개입과 관련된 모든 작업은 그 데이터에 오류가 있을 경우 중대한 영향을 줄 수 있습니다 (예: 고객에게 잘못된 정보를 전달하거나 잘못된 사람을 비활성화 한 경우);
- 고위험 결정: 팀의 노력을 6개월 투자할 계획이 있을 경우, 이중 또는 삼중 확인이 가치가 있습니다;
- 예상치 못한 결과가 나왔을 때: 놀라운 결과를 보았을 때 확인해야 할 첫 번째 가설은 코드에 오류가 있는지 확인하는 것입니다.
물론 이것이 모든 경우의 수가 아니지만, 이유를 이해하고 상식을 사용하여 언제 코드 리뷰를 요청해야 하는지 정의할 수 있기를 바랍니다.
최신 정보를 받아보세요
유명한 Lewis Caroll의 말이 현재 기술 도메인의 상황을 상징적으로 잘 대변합니다.
우리 분야는 끊임없이 발전하고 있습니다: 매일 새 논문이 발표되고, 라이브러리가 업데이트되며, 새로운 도구들이 등장합니다. 소프트웨어 엔지니어, 데이터 분석가, 데이터 과학자들에게도 동일한 이야기가 적용됩니다.
현재 정보를 찾아낼 수 있는 정보 출처이 매우 다양하여, 받아들일 정보에는 전혀 문제가 없습니다:
- Towards Data Science 및 다른 구독으로부터 매주 이메일 수신
- LinkedIn 전문가 팔로우 및 이전 Twitter 팔로우
- 사용하는 도구 및 라이브러리에 대한 이메일 업데이트 구독
- 현지 모임 참석
너무 많은 정보에 압도되지 않도록 하는 것이 조금 더 까다로울 수 있습니다. 저는 너무 많은 산만함을 방지하기 위해 한 가지에 집중하려고 노력합니다.
요약
이것으로 분석가에게 유용한 소프트웨어 엔지니어링 관행들을 모두 소개했습니다. 여기서 간단히 요약하겠습니다:
- 코드는 컴퓨터를 위한 것이 아니라 사람을 위한 것입니다.
- 반복적인 작업은 자동화하세요.
- 도구를 숙달하세요.
- 환경을 관리하세요.
- 프로그램 성능에 대해 생각해보세요.
- DRY 원칙을 잊지 마세요.
- 테스트를 활용하세요.
- 팀원들에게 버전 컨트롤 시스템을 사용하도록 권장하세요.
- 코드 리뷰를 요청하세요.
- 최신 기술을 파악해주세요.
데이터 분석은 다양한 분야의 기술을 결합하기 때문에 소프트웨어 엔지니어, 제품 매니저, 디자이너 등의 모범 사례를 배우면 많은 도움이 된다고 생각합니다. 동료들의 검증된 기술을 도입함으로써 효율성과 효과를 향상시킬 수 있습니다. 이와 같은 인접 분야를 탐험하는 것을 강력히 권장합니다.
참고
이미지는 특별히 언급되지 않는 한 저자가 제작했습니다.
감사의 말
내 파트너에게 진심으로 감사의 마음을 전하고 싶어요. 십년동안 공학 지식을 나누어 주시고 제 모든 글을 검토해 주신 분이에요.