음악 데이터에서 의미 검색과 주관 분석의 시범
의미 검색을 통해 우리의 취향과 기분에 맞는 음악을 발견하는 것이 훨씬 쉬워졌습니다. 오늘날은 노래의 광활한 바다에서, 예술가, 제목 또는 장르별로 검색하는 전통적인 방법은 종종 우리가 찾고 있는 미묘함과 편의성을 포착하기에는 부족하다고 느낍니다.
본문에서는 의미 검색이 음악 발견을 어떻게 향상시키는지 보여주고, 이러한 시스템을 구축할 때 고려해야 할 몇 가지 사항에 대해 의논합니다.
이것은 GenAI 시스템을 구축하는 데 관심이 있는 사람들을 위한 실용적인 예제로 의도되었습니다. 특히 청크 크기가 의미적 결과에 어떤 영향을 미치는지에 대해 설명합니다.
전통 검색 대 의미 검색

전통적인 음악 검색은 아티스트 이름, 제목, 장르 또는 날짜와 같은 명시적 기준을 기반으로 합니다. 이는 해당 항목이 무엇인지에 대한 개념을 가지고 있지 않으며, 단지 그에 정의된 기준("메타데이터")에 따라 동작합니다.
이는 우리가 노래를 검색할 때, 해당 키워드(예: 노래 제목/아티스트명)을 정확하게 일치시키거나 매우 유사하게 일치시켜야 의미 있는 결과를 반환한다는 것을 의미합니다.
대부분의 경우, 우리가 알고 있는 검색 경험이다. 유용하지만, 우리가 명시적으로 알지는 않지만 강한 선호도를 가진 노래를 발견하는 능력을 제공해주지는 않습니다.
반면에 의미 검색은 정의된 범주를 넘어 의미에 기반하여 노래를 찾을 수 있게 해줍니다. 정확한 일치를 찾는 대신, 의미상의 유사성을 기반으로 검색을 수행할 수 있습니다.
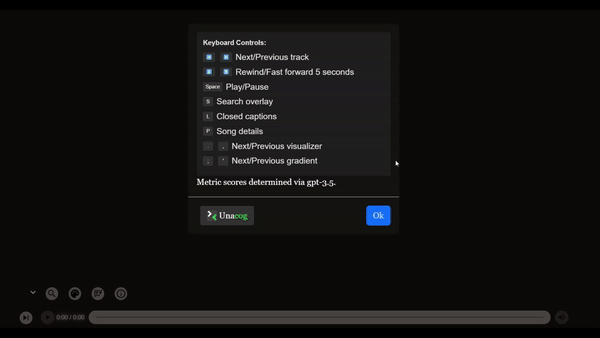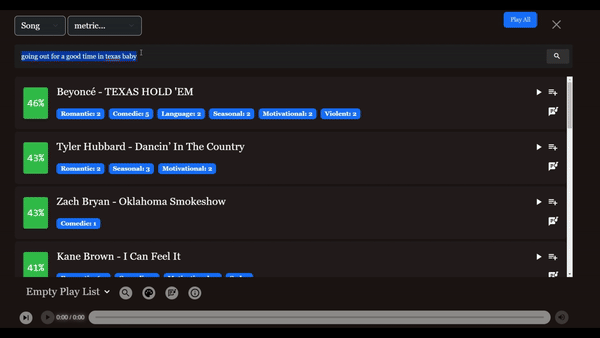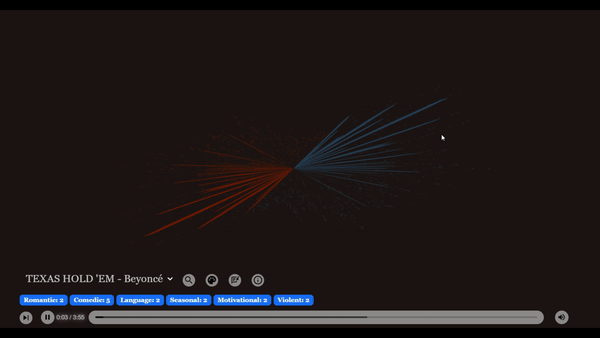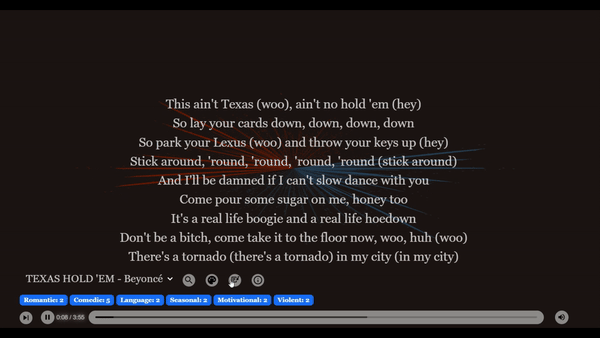
"로맨틱"이나 "슬픔" 아래서 정확히 일치하는 곡을 찾기보다는 "내 남자친구가 밉고 이제 방금 헤어졌어"라는 검색어로 찾을 수 있어요. 그리고 "여름"이나 "인기" 아래서 찾는 대신 "마이애미 보트에서 남자들과 함께하는 여름 분위기" 같은 걸 요청할 수 있죠. 😆
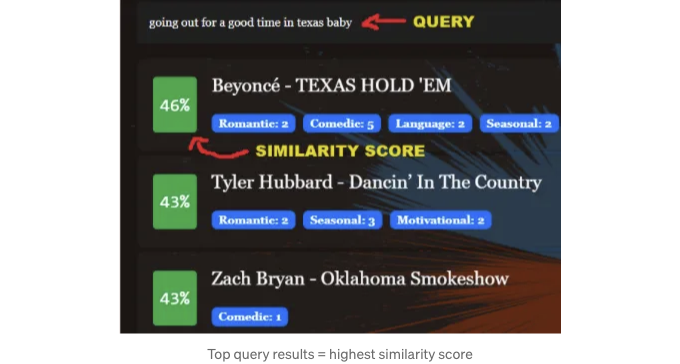
가능한 모든 종류의 쿼리를 생각해보면 가장 유사도 (유사도 점수 사용) 높은 곡들이 반환돼요.
벡터 임베딩: 매우 간략한 개요
시멘틱 검색은 음악 가사 인공지능을 이해 가능하게 만들어 진행됩니다. 이전 글에서 논의된 대로, LLM과 다른 인공지능 모델들은 의미론적 의미를 밀도 있는 벡터 공간으로 수학적으로 표현합니다.
벡터 임베딩은 자연어 처리와 기계 학습에서 기본적인 개념입니다. 이는 단어, 구, 또는 문서를 높은 차원의 공간에서 밀도 있는 벡터로 표현하는 것을 포함합니다. 벡터의 각 차원은 텍스트의 고유한 특징 또는 속성을 나타냅니다.
벡터 임베딩을 만드는 과정은 유사한 의미나 맥락을 가진 단어들이 유사한 벡터 표현을 가져야 한다는 아이디어에 기반합니다.
이는 기계가 단어 간 의미적 관계를 이해하고 시맨틱 검색, 텍스트 분류, 그리고 감성 분석과 같은 작업을 수행할 수 있게 합니다.
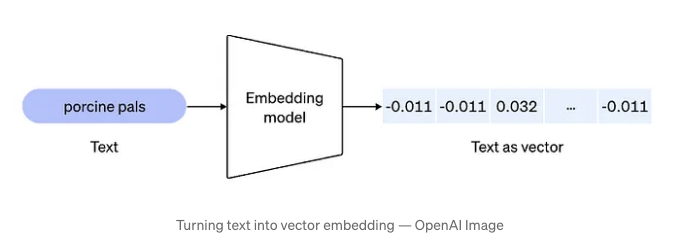
음악 가사에 대한 의미 검색 맥락에서 벡터 임베딩은 단순히 키워드를 일치시키는 대신 가사의 의미와 맥락을 이해할 수 있는 시스템을 가능케 합니다.
사용자의 쿼리의 벡터 임베딩을 노래 가사의 벡터 임베딩과 비교함으로써, 시스템은 쿼리와 의미론적으로 유사한 노래를 검색할 수 있습니다. 실제로 똑같은 단어를 포함하지 않는 경우라도 말이죠.
노래 데모 데이터셋
우리의 음악 발견 데모를 구축하기 위해, 우리는 2024년 1월 1일부터 3월 1일까지의 빌보드 탑 100 곡에 초점을 맞췄습니다.
이 데이터셋은 비교적 작지만 전국에서 가장 많이 재생된 곡들로 구성되어 있기 때문에 탐험의 좋은 기반 역할을 합니다. 마지막으로 우리는 중복된 곡들을 제거하고 데이터셋을 정리하여 총 301곡의 컬렉션이 생성되었습니다.
알아두셔야 할 사항으로는, 크리스마스 고전 곡들을 제거하는 작업이 대부분이었어요 — 휴일 때문에 과도하게 재생되는 곡들이었거든 😓 — 우리의 목표는 새로운 음악을 발견하는 것이었기 때문에 이를 제외했습니다.
다른 청크 크기는 의미론적 결과를 변경합니다
시맨틱 검색에 대해 이야기할 때, 우리가 어떤 것을 분해하고 분석하는 방법은 우리가 얻는 결과에 상당한 영향을 줄 수 있어요.
Chunk size는 데이터를 분석하고 벡터 표현을 위해 얼마나 세분화하는지를 말해요. 그들은 서로 다른 시맨틱 의미를 가지기 때문에, 바로 벡터 임베딩의 성격과 따라서 시맨틱 검색 결과에 직접적인 영향을 미치죠.
Chunk size는 노래 검색에서 중요한 역할을 함
청크 크기의 선택은 검색 결과의 특성에 직접적인 영향을 미칩니다. 일반적으로 우리는(이전의 데모에서 알 수 있듯이) 더 큰 청크와 매칭하는 것이 테마/개념에 대한 포괄적인 시각을 제공하는 반면, 더 작은 청크와 매칭하는 것은 보다 특정 키워드 결과를 얻을 수 있게 합니다.
이를 더 실험하기 위해, 우리는 4가지 다른 종류의 청크 세그먼트를 만들기로 결정했습니다:
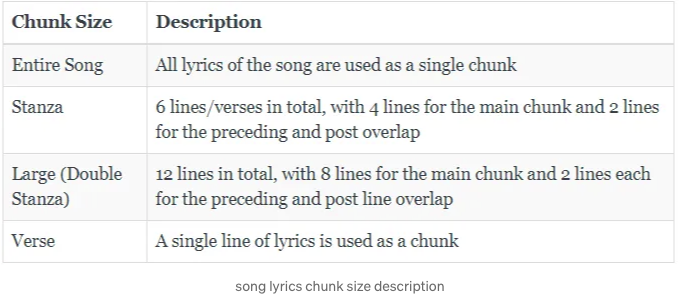
즉, 전체 음악 청크 외에도, 다른 세그먼트 유형은 기본적으로 노래 가사를 여러 청크로 나누어 각각의 벡터 임베딩을 갖게 합니다.
일치 청크 시각화로 명확한 피드백 제공
저희는 노래 가사에 하이라이트를 추가하여 쿼리, 일치하는 청크, 그리고 최종 결과 사이의 관계를 시각화하는 데 도움을 주었습니다.
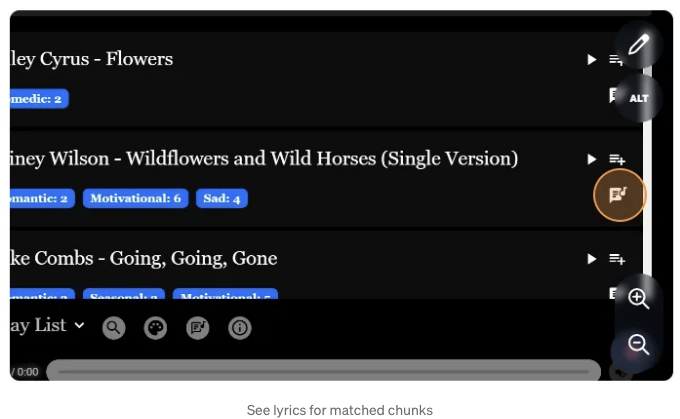
- 일치하는 청크 (주황색)
- 중첩 부분 (노란색, 스탠자 및 대 스탠자에 대한 중첩만)

결과의 일반적인 논의
시맨틱 검색이 올바르게 작동하는지 확인하는 것은 꽤 직관적이었습니다. 결과는 우리가 입력한 쿼리와 매우 상관이 있었습니다. 우리의 초점은 상위 결과에 있었으며, 이는 이상적인 사용자 경험을 시뮬레이트하며, 300개의 노래가 아닌 30,000곡과 같은 큰 데이터 세트를 처리할 때 어떤 느낌이 될지를 보여줍니다.
가끔은 정확한 노래를 찾기 위해 올바른 표현을 찾는 데 몇 번을 시도해야 했지만, 그것은 일관되고 예측 가능했습니다. 즉, 찾고 있는 노래가 최상위 결과가 아닌 경우에도 왜 그런지 명확했습니다.
아래는 청크 크기를 기반으로 한 결과들에 대한 토론입니다:
벌스(Verse) 결과에 대한 토론
벌스는 우리가 찾고 있는 정확한 일치를 반환하는 데 가장 쉽고 예측 가능한 것으로 보입니다. 이는 검색어를 상대적으로 잘 알고 있어야 한다는 점에서 전통적인 Google 검색과 매우 유사합니다.
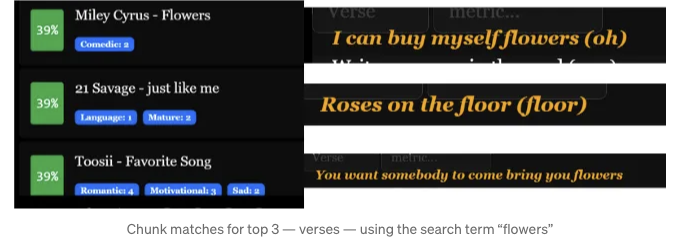
작은 조각들은 강력한 "퍼지(fuzzy)" 검색 역할을 할 수 있습니다. 여기에서 키워드나 개념과 일치할 수 있습니다. - 꽃의 경우, 장미 반환.
그러나 전반적인 주제나 개념을 기반으로 한 검색에 비해 더 큰 조각들보다는 덜 유용합니다.
전체 노래 가사 결과 논의
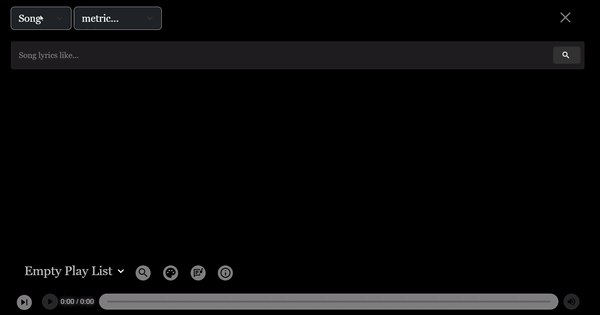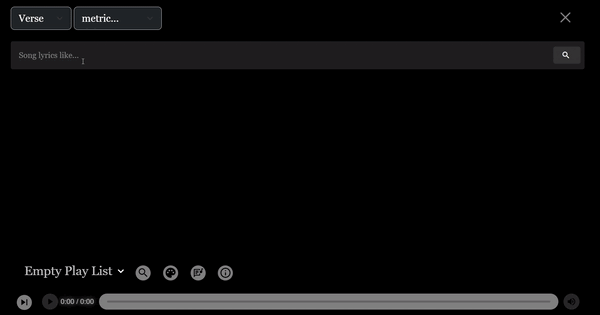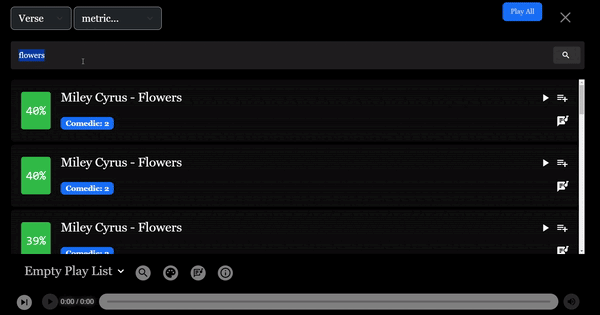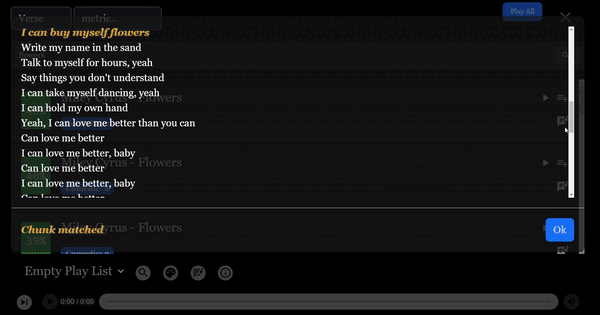
이 점을 설명하기 위해 "flower"라는 용어로 전체 곡 가사를 검색할 수 있습니다. 이 결과로 Miley의 곡이 4위에 올라 약 23%가 일치합니다.
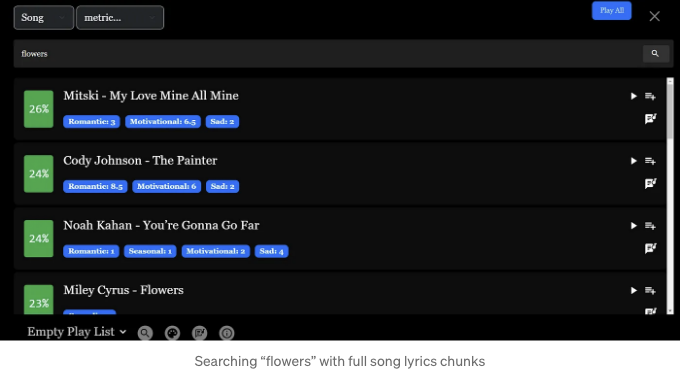
곡 가사를 분석하면 이해할 수 있는데, "flower"라는 용어 자체가 전체 노래의 작은 부분만을 차지하기 때문입니다.
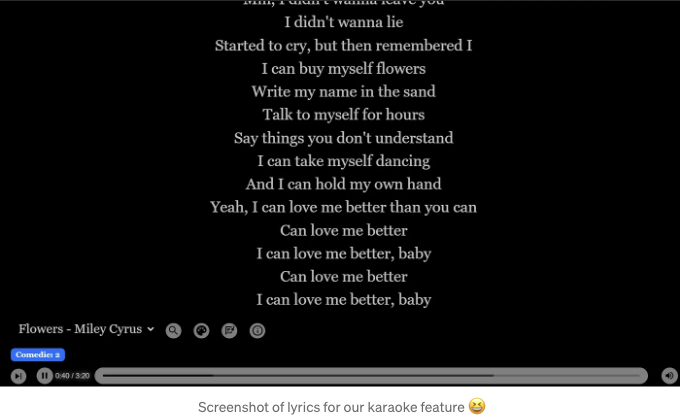
"Flower" may be in the song title, but it doesn't play a significant role in the overall message. The song mainly focuses on the journey to self-empowerment post-breakup. In a large dataset, Miley's song might not rank highly in search results.
Here's another example highlighting search terms and song excerpts:
Let's delve into Benson Boone's "Beautiful Things" to showcase how semantic search enhances the user experience.
다시 한 번 강조하자면, 우리의 주요 관심은 노래를 높은 확률로 식별하여 대규모 데이터셋을 사용하는 느낌을 시뮬레이션하는 것에 있습니다.
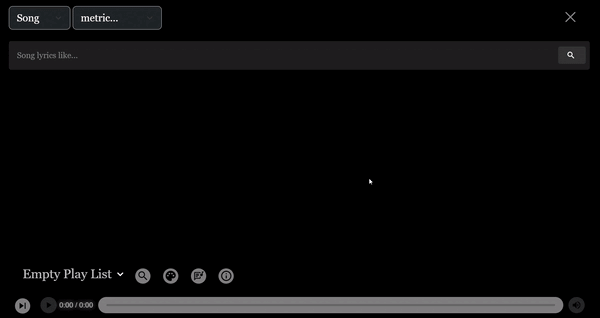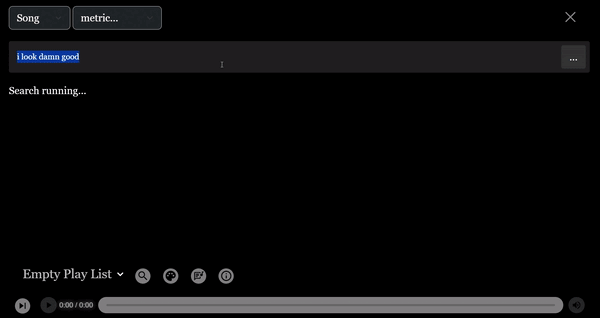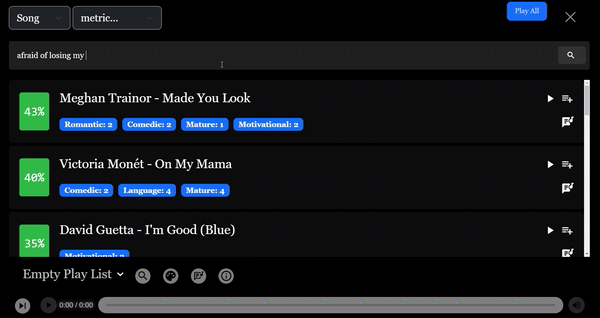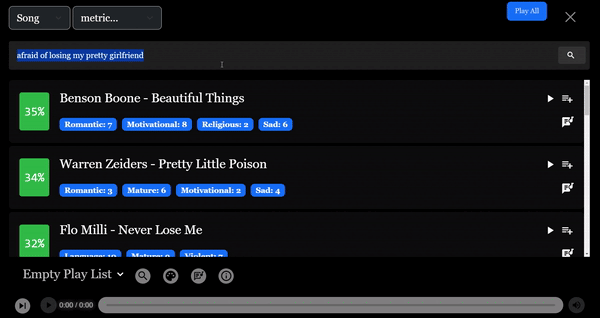
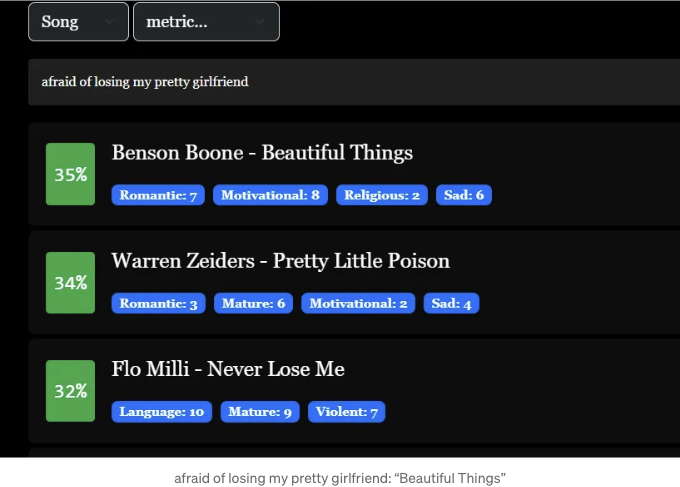
첫 눈에 보았을 때 가사는 무엇인가에 감사하는 주제를 중심으로 하고 있는 것으로 보였습니다, 특히 사랑하는 관계(가족, 연인 등)에서 그것을 감사해하는 것에 대한 맥락에서, 그래서 첫 번째 검색어로 "가진 것에 감사하는 것"을 사용했습니다.
그러나 결과는 23%의 유사도를 가진 세 번째로 나타났습니다. 가사를 더 자세히 살펴보니, 이는 매우 말이 되는 것 같습니다. 노래 전반을 주도하는 주제는 당신이 사랑하는 사람을 잃을까 두려워하는 깊은 두려움인 것 같습니다.
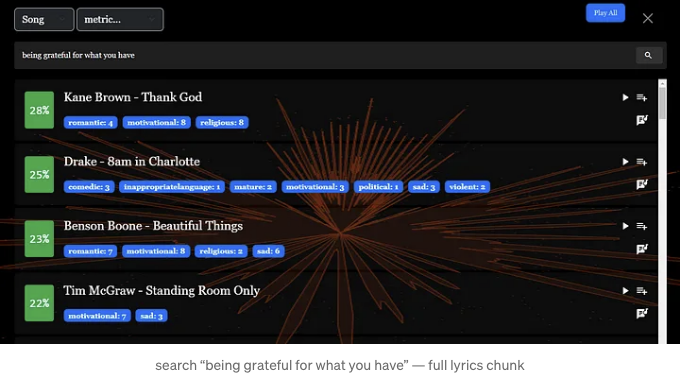
결과를 개선하기 위해 "예쁜 여자친구를 잃을까봐 두려워"라는 검색어를 수정하여 유사도 점수가 35%로 더 높은 결과인 이 노래를 최상위 결과로 반환받았습니다.
이렇게 하니까 훨씬 좋았어요. 1000배 더 큰 데이터셋이었다면 "가진 것에 감사하는 법"이라는 검색어는 아마 이것을 최상위 결과로 반환하지 않았을 것입니다.
한편, 흥미로운 점은 "예쁜"이라는 단어를 "섹시한"으로 대체했을 때 유사도 점수가 31%로 떨어졌고, 여성에 대한 유사한 언급을 한 다른 노래들이 37% 일치율로 결과 상단에 오르는 것을 볼 수 있었습니다.
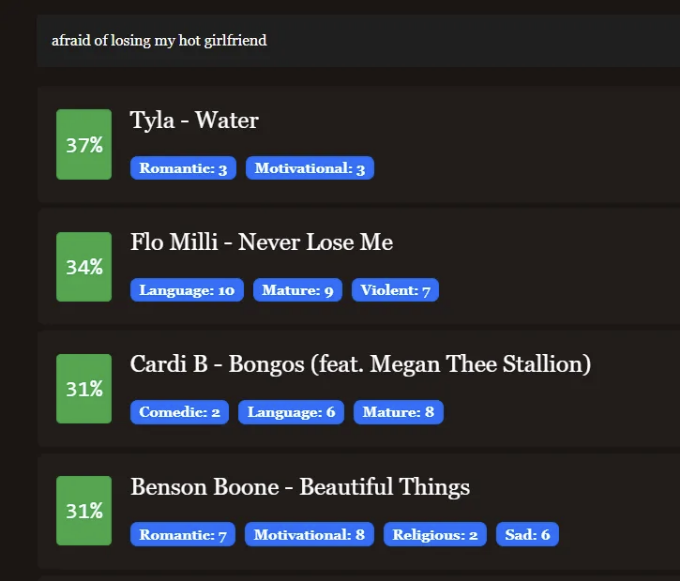
이는 질의어의 선택이 검색 결과에 상당한 영향을 미칠 수 있다는 것을 명백히 보여줍니다. 전반적인 주제가 동일한 경우에도 말이죠.
노래 및 스탠자 청크 결과에 대한 토론
스탠자와 이중 스탠자를 청크로 검색하는 것은 특정 곡을 찾으려고 할 때 가장 어려운 것으로 나타났습니다. 사용자 관점에서 각 청크에 어떤 개념이 포함될 수 있는지 명확히 파악하기 어려운 점 때문입니다.
개념적으로, 주요 정보가 분할되어 완전히 두 청크 모두의 전제가 변경될 때 어려움이 발생합니다. 스탠자와 큰 스탠자 청크의 중첩은 이를 돕기 위해 있지만, 절대 완벽한 해결책은 아닙니다.
그러나 보통 곡의 주제나 일부분을 알고 있으면 검색할 수 있는 경우가 많았습니다. 그 이유는 대부분 빌보드 Top 100 노래들이 많은 반복을 포함하고 있기 때문입니다.
이는 "Beautiful Things"에서도 마찬가지였습니다. "afraid of losing my pretty girlfriend"라는 쿼리는 노래, 스탠자 및 대 스탠자 세 가지 청크 크기를 모두 포괄할 수 있는 효과적인 검색어였습니다. 이는 당신의 소중한 이들을 보호하는 주제가 이 노래 전체에 걸쳐 여러 부분에서 뚜렷하게 드러나기 때문입니다.
스탠자 결과
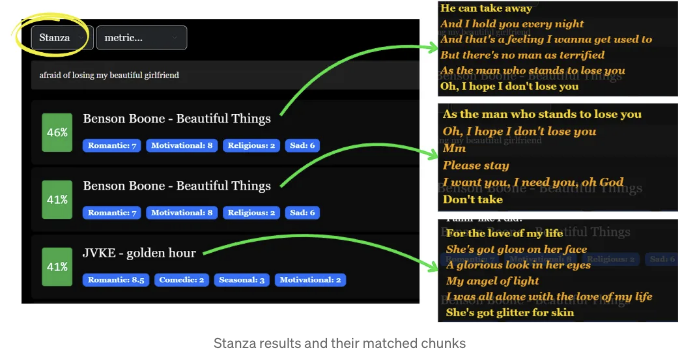
Results for Large Stanza (double stanza)
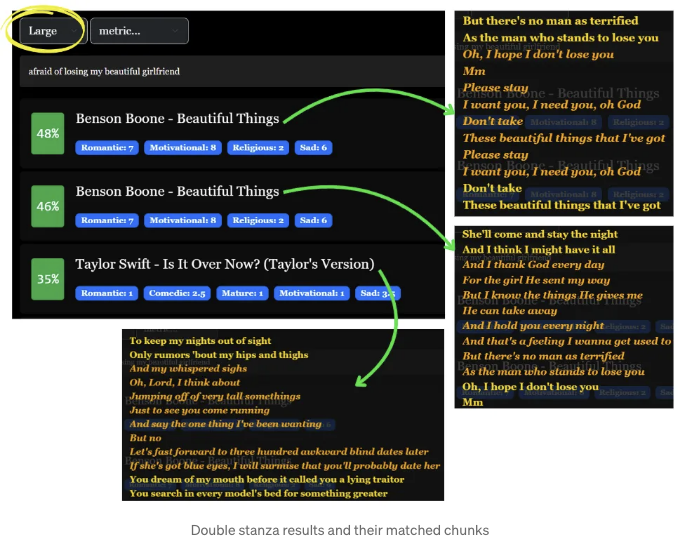
The query "afraid of losing my pretty girlfriend" performed the worst at the song level, compared to 45% and 47% for stanza and large stanza, respectively.
Examining the lyrics more closely reveals that there are other themes present beyond the romantic one captured by our query. This makes sense as there are in theory many other queries that will also return "Beautiful Things" in the top results.

그리고 실제로 우리의 메트릭스(산출된 LLM 주관적 분석에서)는 로맨틱한 테마 외에도 "내 귀여운 여자친구를 잃을 것 같아" 라는 쿼리로 캡슐화된 것이 주된 요소임을 보여줍니다. 또한, 그 안에는 동기부여, 종교적, 슬픔과 같은 요소들도 포함되어 있습니다.
결론
벡터 임베딩과 의미 검색은 우리가 구축할 수 있는 새로운 길을 열어줍니다. 다양한 청크 크기는 의미 검색 기능을 사용자 정의할 수 있게 해줍니다. 노래의 본질을 포착하는 적절한 쿼리를 만드는 것은 어렵습니다. 특히 다른 청크 크기 사이를 변경할 때 말이죠.
AI 에이전트 시스템을 구축하는 사람들에게는 청킹 전략 (즉, 어떤 크기가 어떤 사용 사례에 적합한지)을 고려하는 것이 중요한 기본 사항입니다. 이는 우리 에이전트에 공급되는 정보의 크기와 유형을 결정하기 때문입니다. 이 예에서는 노래 데이터를 고려했지만, 여기서 사용된 데이터 기술은 다른 사용 사례와 산업에 널리 적용될 수 있습니다.
이전에 다뤘던 것처럼, 절은 의미론적 문맥이 매우 작기 때문에 거의 키워드 검색과 유사하게 사용됩니다. 반면, 더 큰 청크 크기로 작업할 때 의미를 더 잘 이해할 수 있습니다.
청킹이 자연어 검색 방법에 어떤 영향을 미치는지 고려해야 합니다. 고려해야 할 몇 가지 질문은 다음과 같습니다: 우리의 문맥 창은 얼마나 큰가요? 청크는 문서에 포함된 아이디어를 어떻게 분할할까요? 작업을 수행하는 데 필요한 문맥 유형은 무엇인가요? 사용자 쿼리는 어떻게 생겼나요 (그리고 얼마나 큰가요)?
적절한 청크 크기 선택: 특정 사용 사례와 원하는 사용자 경험을 기반으로 적합한 청크 크기를 선택하는 중요성을 기억해야 합니다. 예를 들어, 사용자가 특정 가사나 구절을 기반으로 노래를 찾을 수 있게 하려면 절과 같은 작은 청크 크기가 더 적합할 수 있습니다. 반면, 전반적인 주제나 감정을 기반으로 노래를 추천하려면 전체 노래나 스탠자와 같은 큰 청크 크기가 더 효과적일 수 있습니다.
정확성과 효율성의 균형 맞추기: 청크 크기를 결정할 때 검색 결과의 정확성과 계산 효율성 사이의 절충을 고려해야 합니다. 보다 작은 청크 크기는 더 정확한 일치를 제공할 수 있지만 더 많은 계산 자원과 저장 공간이 필요합니다. 더 큰 청크 크기는 더 효율적일 수 있지만 덜 정확한 결과를 초래할 수 있습니다. 사용 가능한 자원과 성능 요구 사항을 기반으로 적절한 균형을 찾으세요.
대규모 구현에 들어가기 전에 청킹 및 임베딩 전략을 세밀하게 조정할 수 있도록 작은 데이터셋으로 실험을 권장합니다.
앞으로 바라보는 것: 음악 발견의 미래
우리가 본 것처럼, 의미 검색은 음악 발견에 대한 강력한 새로운 접근 방식을 제공하여 사용자가 노래를 의미, 주제 및 감정에 기반하여 찾을 수 있게 합니다. 이 기술은 아직 초기 단계에 있지만, 음악과 상호 작용하는 방법을 향상시키는 데 큰 약속을 보여줍니다.
가까운 미래에는 의미 검색과 LLM(대형 언어 모델)에서 파생된 측정치를 활용하는 AI DJ 에이전트들이 어떤 상황에도 완벽한 노래를 찾는 데 필수적인 출처로 자리 잡을 수도 있습니다. 다음 글에서는 LLM이 로맨틱 매력이나 감정적 깊이와 같은 주관적 메트릭을 각 노래에 대해 생성하는 방법을 탐구할 것입니다. 이를 통해 음악 추천의 맥락과 개인화를 더욱 강화할 수 있습니다.
계속 읽기
이 시리즈의 두 번째 파트에서 (곧 공개 예정), LLM과 주관적 분석이 어떤 흥미로운 세계를 제공하는 지 살펴볼 것입니다. 어떻게 LLM을 활용하여 데이터 검색을 더 강화하는 유용한 메트릭을 생성하는 지 알아보세요.
DEMO에 액세스하기
Due to the nature of the content, I cannot make this demo public to my readers. If you'd like to learn more about our demos, please visit Unacog.
Let's Stay Connected
Thank you for reading! If you enjoyed this article and would like to see more content like this, please follow me here on Medium to receive notifications whenever I post something new. Also, feel free to connect with me on LinkedIn. 🙏