용어 및 구조.
소개
한동안 Apache Kafka를 배우고 싶었지만, 항상 우선순위가 더 높은 주제들이 있어 미루고만 있었어요.
(엄청나게 미뤄놓는 방법이네요)
이 블로그 글의 주제를 찾아보던 중, 나는 Kafka에 대해 진지하게 공부하는 기회가 있다는 것을 깨달았고, 그것에 대해 쓰기로 결정했다.
내 학습 과정과 일치하는 Kafka 블로그 시리즈를 쓰기로 계획 중이다.
이 블로그는 시리즈의 첫 번째 부분이며, 이 글의 범위는 Kafka의 고수준 개요와 LinkedIn의 데이터 인프라에서의 활용에 대해 다룰 것이다.
고수준 개요
인터넷 기업들은 LinkedIn과 같이 사용자 활동 이벤트(로그인, 페이지 뷰, 클릭) 및 운영 지표(서비스 호출 대기 시간, 오류, 또는 시스템 자원 이용률 포함)를 포함한 방대한 양의 로그 데이터를 생성합니다. 이 로그 데이터는 일반적으로 사용자 참여 및 시스템 성능 추적에 사용되었지만, 이제는 검색 관련성, 추천 및 광고 타겟팅과 같은 제품 기능에도 활용되고 있습니다.
LinkedIn의 로그 처리 요구 사항을 해결하기 위해 Jay Kreps에 의해 이끌리는 LinkedIn 내부 개발 팀은 Kafka라는 메시징 시스템을 구축했습니다. 이 시스템은 기존 로그 집계기와 발행/구독 메시징 시스템의 이점을 결합한 것입니다. Kafka는 고 처리량과 확장성을 제공하기 위해 설계되었습니다. 메시징 시스템과 유사한 API를 제공하며 애플리케이션이 실시간 로그 이벤트를 소비할 수 있습니다.
더욱이 Kafka 개발 당시 대부분의 기존 시스템은 브로커가 데이터를 컨슈머에게 푸시하는 "푸시" 모델을 사용했습니다. LinkedIn 팀은 소비자가 처리할 수 있는 최대 속도로 메시지를 검색할 수 있으며 처리할 수 있는 속도보다 빨리 푸시되는 메시지에 넘치지 않도록하는 "풀" 모델이 더 적합하다는 것을 발견했습니다.
메시지
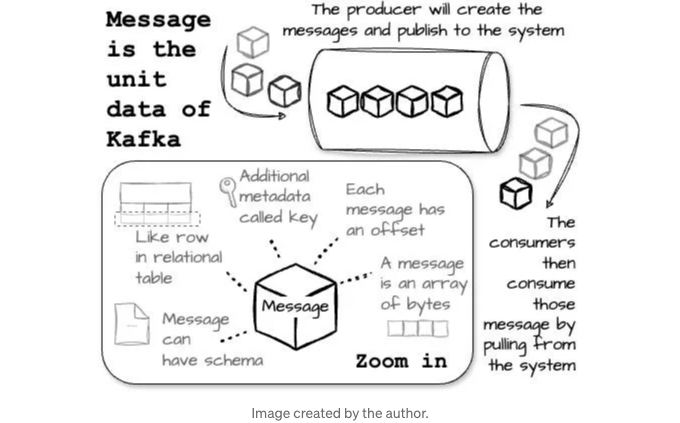
카프카의 데이터 단위는 메시지입니다. 이를 데이터베이스 세계의 행이나 레코드와 유사하다고 생각할 수 있습니다. 메시지에는 키라고하는 선택적인 메타데이터 조각이 포함될 수 있습니다. 내부적으로 메시지와 키는 Byte의 배열일 뿐입니다. 키는 파티셔닝에 더 많은 제어를 원하는 사용자가 사용할 수 있습니다. 예를 들어 Kafka는 일관된 해싱을 사용하여 동일한 키를 가진 메시지가 동일한 파티션에 배치되도록 보장할 수 있습니다.
Kafka에 저장된 메시지에는 명시적인 메시지 ID가 없습니다. 대신 각 메시지는 논리적 오프셋으로 주소 지정됩니다. 이렇게 함으로써 메시지 ID를 실제 메시지 위치로 매핑하는 인덱스 구조를 유지하는 오버헤드를 피할 수 있습니다. 다음 메시지의 오프셋을 계산하려면 소비자는 현재 메시지의 길이를 오프셋에 추가해야 합니다.
토픽과 파티션
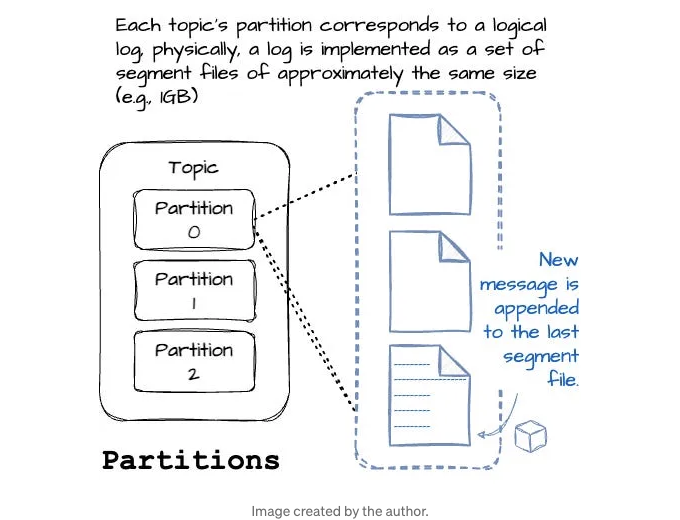
Kafka의 메시지는 주제(topic)로 구성됩니다. 데이터베이스 시스템의 테이블과 비슷하게 생각할 수 있습니다. 주제는 여러 파티션으로 분할될 수 있습니다.
파티션은 Kafka가 제공하는 복제 및 확장성의 방법입니다. 파티션은 다른 서버에 호스팅될 수 있으며, 이는 주제가 여러 서버를 가로지르는 가로 방향으로 확장될 수 있음을 의미합니다.
주제의 각 파티션은 논리적 로그에 해당합니다. 물리적으로 로그는 대략적으로 동일한 크기의 세그먼트 파일 집합으로 구현됩니다 (예: 1GB). 메시지가 파티션에 쓰여지면 브로커는 해당 메시지를 마지막 세그먼트 파일에 추가합니다.
생산자
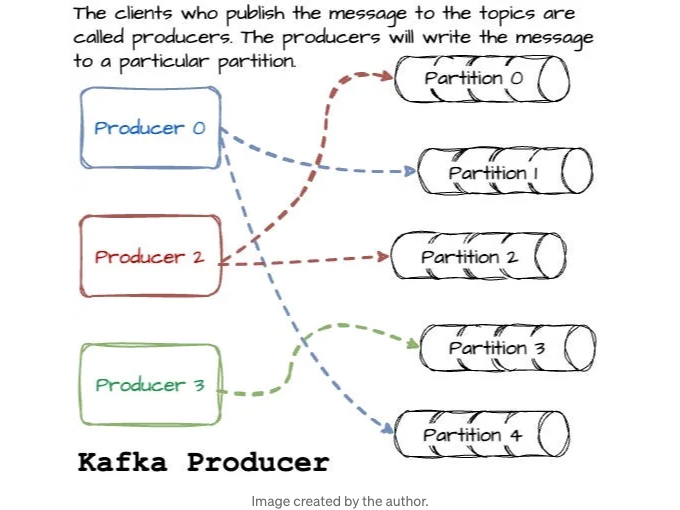
메시지를 토픽에 발행하는 클라이언트들을 생산자(Producers)라고 합니다. 생산자들은 메시지를 특정 파티션에 작성합니다. 이는 메시지 키와 파티셔너를 사용하여 키의 해시를 생성하고 특정 파티션에 매핑하는 것으로 이루어집니다. 기본적으로, 생산자는 모든 토픽 파티션에 메시지를 공평하게 분산시킵니다. 경우에 따라, 생산자는 메시지를 특정 파티션으로 직접 전송할 수 있습니다. 이는 메시지 키에 특정 파티션 체계를 적용함으로써 달성됩니다.
소비자
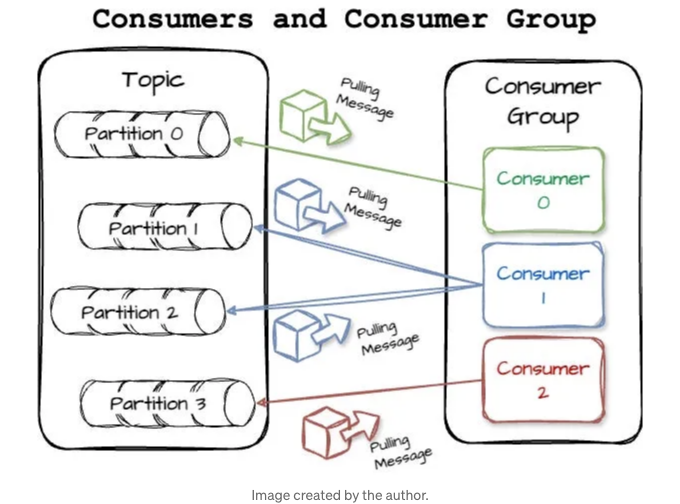
클라이언트는 한 개 이상의 구독 주제에서 메시지를 가져와서 메시지를 읽습니다. 소비자는 파티션에 작성된 순서대로 메시지를 읽습니다. 소비자는 메시지 오프셋을 사용하여 소비를 추적합니다. 소비자가 특정한 메시지 오프셋을 확인하면, 해당 오프셋 이전의 모든 메시지를 받았다는 것을 의미합니다.
소비자는 소비자 그룹의 일부로 작동하며, 한 개 이상의 소비자가 함께 주제를 소비하는 구조로 동작합니다. 그룹은 각 파티션에 대해 단 하나의 소비자만이 책임을 질 수 있도록 설계되었습니다. 예를 살펴보죠. 다음 그림에서는 네 개의 파티션(p0,p1,p2,p3)이 있는 메시지 토픽과 세 개의 소비자(c0,c1,c2)로 구성된 소비자 그룹이 있습니다; 파티션-소비자 매핑 예시는 다음과 같습니다: c0가 p0, c1이 p1, c2가 p3를 담당합니다.
"생산자들"처럼, 저는 곧 카프카 소비자를 위한 전체 기사를 작성할 계획입니다.
브로커
게시된 메시지는 브로커라고 불리는 서버 집합에 저장됩니다. 브로커는 프로듀서로부터 메시지를 받아 offset을 할당하고 디스크에 기록합니다. 또한 메시지 가져오기 요청에 응답하여 소비자를 지원합니다.
클러스터
카프카 브로커는 클러스터의 일부로 작동합니다. 클러스터 내에서 하나의 브로커가 클러스터 컨트롤러 역할을 수행합니다. 컨트롤러는 관리 작업을 담당합니다.
Kafka에서 복제는 파티션 내의 메시지의 중복성을 제공하여 브로커가 실패할 경우 팔로워 중 하나가 리더십을 대신할 수 있게 합니다. 모든 프로듀서는 메시지를 발행하기 위해 리더에 연결해야 하지만, 소비자는 리더 또는 팔로워 중 하나에서 메시지를 가져올 수 있습니다.
클러스터에는 하나의 브로커가 있으며 파티션을 소유합니다. 이 브로커가 파티션의 리더로 불립니다. 복제된 파티션은 파티션의 팔로워로 지정되는 추가 브로커들에 할당됩니다.
Architecture
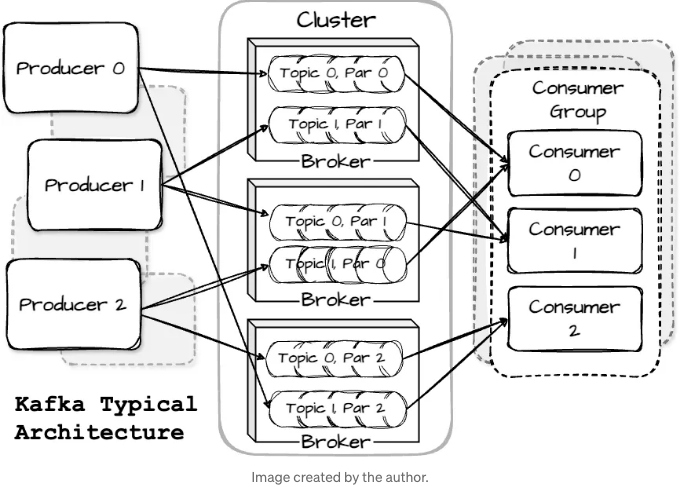
A Kafka cluster usually involves several brokers working together. Topics are partitioned to balance the workload, with each broker handling one or more partitions. This setup allows for multiple producers and consumers to interact simultaneously.
Now that we have covered some basic information about Apache Kafka, let's move on to exploring how Kafka is utilized at LinkedIn.
Kafka at LinkedIn
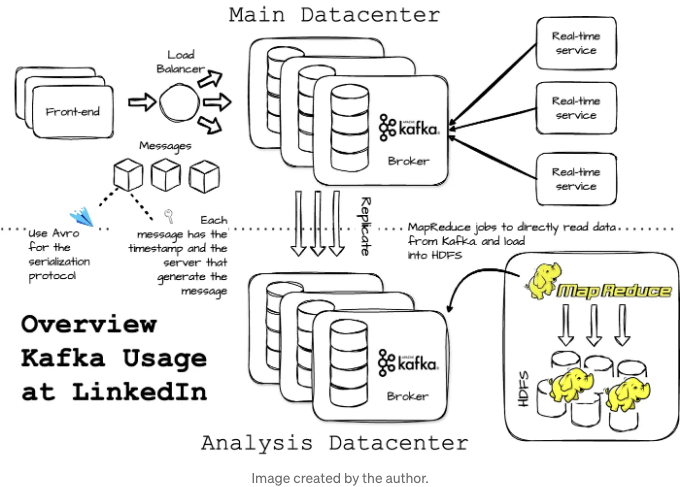
LinkedIn에서는 각 데이터 센터에 공동 Kafka 클러스터가 있습니다. 프론트엔드 서비스는 로그 데이터를 생성하고 일괄적으로 로컬 Kafka 브로커에 발행합니다. 발행 요청을 균등하게 분산하는 로드 밸런서가 있었습니다. 이 클러스터에서 메시지를 검색하는 소비자들도 동일한 데이터 센터에서 실행됩니다.
LinkedIn은 하둡 클러스터 근처에서 오프라인 분석용 별도의 Kafka 클러스터를 운영했습니다. 이 Kafka 인스턴스는 주 클러스터로부터 데이터를 가져오기 위해 내장된 소비자를 이용해 데이터를 복제합니다. 오프라인 클러스터의 데이터는 보고서, 분석 워크로드 및 즉석 쿼리를 제공하는 데 사용됩니다.
LinkedIn 엔지니어들은 데이터 손실이 없도록 감사 시스템을 개발했습니다. 각 메시지는 생성될 때의 타임스탬프와 서버 이름을 가지고 있습니다. 주기적으로 프로듀서들은 고정된 시간 창에서 주제 당 발행된 메시지 수를 기록하는 모니터링 이벤트를 생성합니다. 그런 다음 프로듀서들은 이러한 메시지를 별도의 Kafka 주제에 발행합니다. 전용 소비자들은 주제 당 메시지 수를 계산하고 이를 모니터링 이벤트와 대조하여 올바름을 확인합니다.
데이터와 메시지 오프셋은 HDFS에 저장됩니다. Kafka에서 하둡 클러스터로 데이터로드는 MapReduce 작업에서 데이터를 직접 Kafka에서 읽기 위한 특별한 Kafka 입력 형식을 사용합니다.
"Apache Kafka에서는 효율적이고 스키마 진화를 지원하는 Avro 직렬화 프로토콜을 선택했습니다. 각 메시지에는 해당 Avro 스키마의 ID와 직렬화된 바이트가 페이로드에 저장됩니다. 이 스키마는 데이터 생성자와 소비자 간의 호환성을 보장합니다. 게다가 LinkedIn은 경량 스키마 레지스트리 서비스를 사용하여 스키마 ID를 스키마에 매핑했습니다.
마무리
이 글을 통해 Apache Kafka의 고수준 내용, 용어 및 아키텍처를 살펴보고, 마지막으로 LinkedIn이 Kafka를 내부적으로 어떻게 활용하는지 살펴보았습니다.
다음 글에서는 이 시리즈의 중요한 Kafka 설계 결정 사항을 다룰 예정입니다."
그럼, 다음 주에 만나요!
참고 자료
[1] Jay Kreps, Neha Narkhede, Jun Rao. "Kafka: a Distributed Messaging System for Log Processing." (2011)
[2] Gwen Shapira, Todd Palino, Rajini Sivaram, Krit Petty. "Kafka The Definitive Guide Real-Time Data and Stream Processing at Scale." (2021)
제 뉴스레터는 주간 블로그 형식의 이메일로, 제가 더 똑똑한 사람들로부터 배운 것들을 기록합니다.
그러니 저와 함께 배우고 성장하고 싶다면 여기에서 구독해주세요: https://vutr.substack.com.