Braineous Data Platform는 기업 데이터, ETL/ELT, 분석 및 기계 학습 애플리케이션용 오픈 소스 고규모 데이터 파이프라인 플랫폼입니다.
이 기사에서는 기술적 개념과 플랫폼에서 첫 번째 데이터 파이프라인을 만드는 시작할 수 있는 실습을 다룹니다.
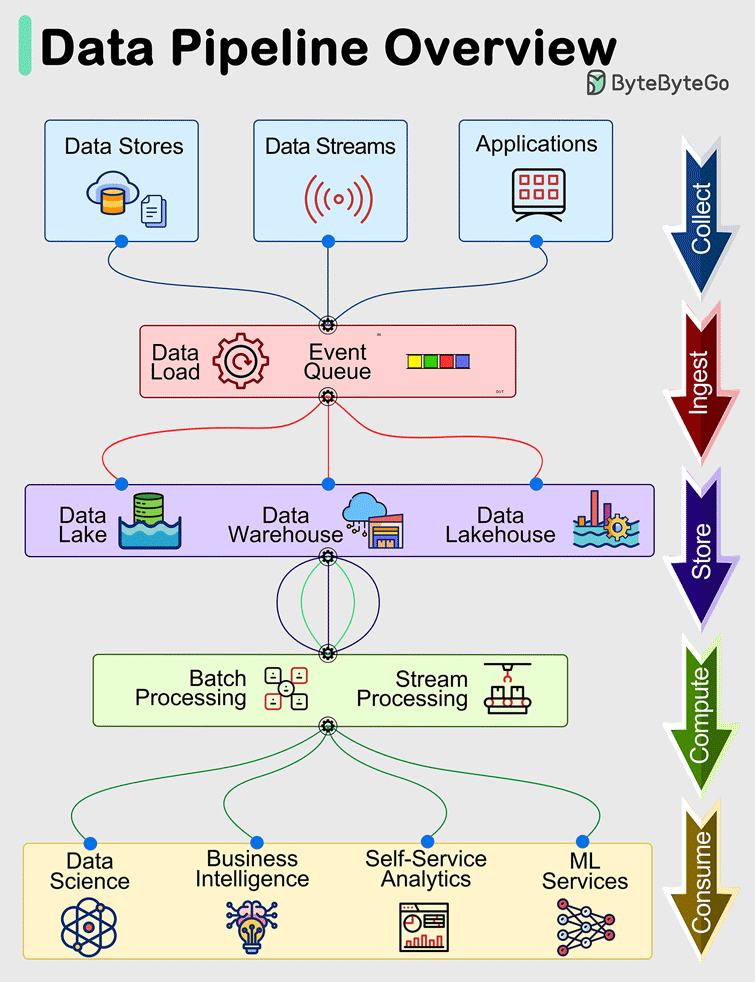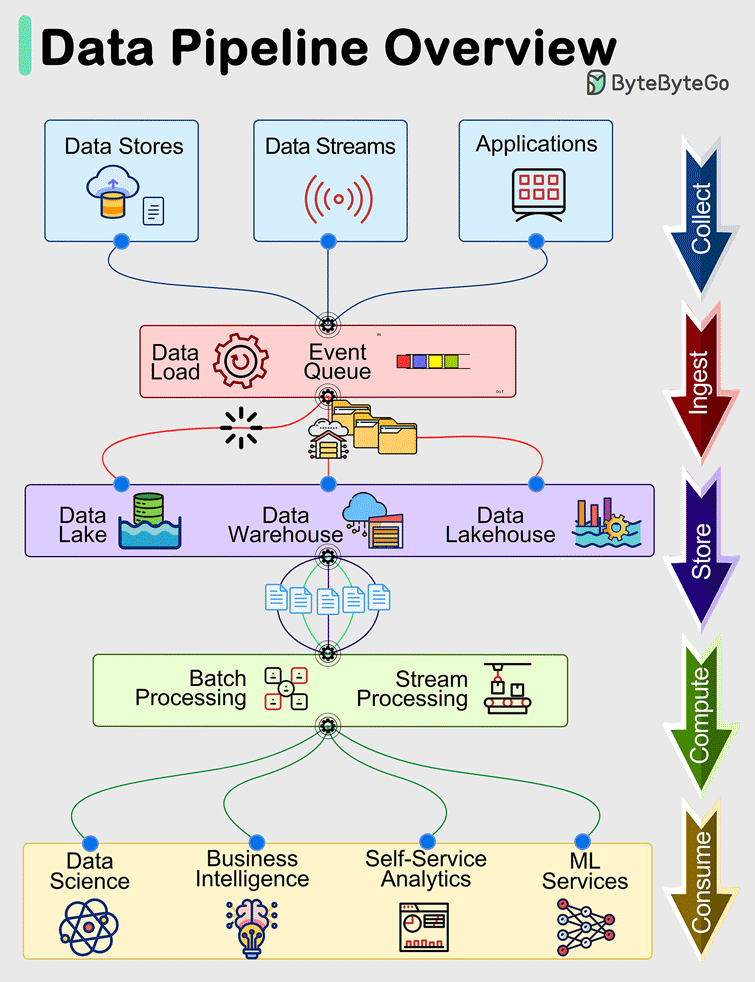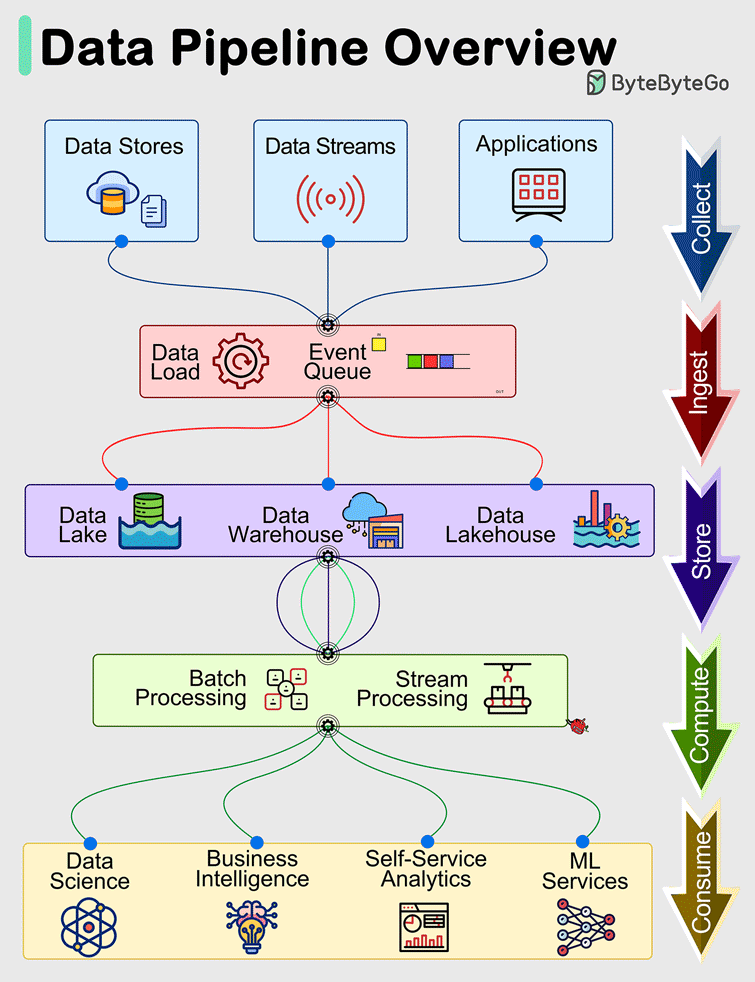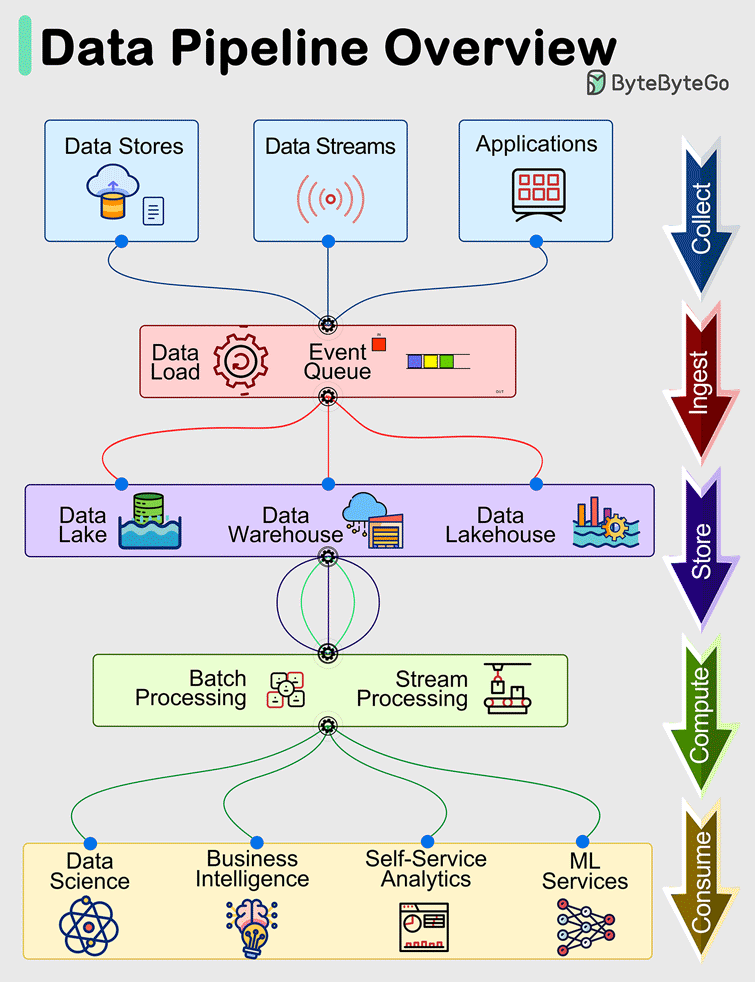
데이터 수집은 임의의 데이터 원본으로부터 데이터를 확보하고 유효성을 검사하며 변환, 정리하고 응용 프로그램에서 하향 스트림 사용을 위해 데이터를 저장하는 과정입니다.
이 프로세스는 데이터를 생성된 위치(데이터베이스, 모바일 기기, IoT 센서 등)에서 응용 프로그램이 사용할 수 있는 대상 시스템으로 이동시키는 것을 포함합니다.
사용 사례:
- 기업 내 데이터 격리 해제
- 비즈니스 파트너와 데이터 공유
- 데이터 과학자를 위한 실시간 데이터 스테이징 및 머신 러닝 모델을 교육
- 비즈니스 인텔리전스 도구를 통해 실행 가능한 통찰력 도출
Conceptually, data ingestion involves a source system that produces data and a target system that utilizes this data. In high-scale data ingestion scenarios, data is generated by systems capturing real-time data from sources such as mobile devices, sensors, flight operations, navigation, etc. The volume and speed of this data, often termed as events in the platform, are usually high.
Data Pipelines
A data pipeline establishes a connection between the data source and a target storage/system. The data source generates data and sends it to the platform ingestion system using the Braineous Data Ingestion Java SDK. The Braineous data pipeline engine supports various data sources and multiple target systems that can be linked to a single pipeline. It can handle as many pipelines as needed for applications operating at scale.
The platform can transform data in any format (XML, CSV, or JSON) into JSON format for processing. Once converted into internal JSON format, a simple Object Graph is created and leverages configured JSONPATH expressions to generate data for the target system before delivering it in the desired data format.
The process is always changing. Simply adjust the pipe configuration and roll.
The platform seamlessly connects unstructured datasets to structured datasets in real-time. Your Data Lake grows and adapts alongside the dataset. For Analytics and Machine Learning, structured queries are essential for training the AI model. The platform connects these two worlds seamlessly. Downtime is simply not an option for Braineous.
Data Lake
A 'datalake store' serves as the internal repository where the pipeline delivers data for applications focused on analytics and machine learning use cases. The platform utilizes Apache Flink as its data processing engine and supports data lakes based on Apache Hive.
Braineous의 미래 릴리스에는 고객이 개발한 사용자 정의 데이터 레이크를 지원할 수 있는 데이터 레이크 커넥터 프레임워크가 포함될 예정입니다.
ETL/ELT
이 플랫폼을 통해 데이터 통합이 원활하게 이루어집니다. 고객들은 ETL의 변환 부분만 처리하는 데도 몇 달 동안의 통합 비용(돈과 시간 모두)을 지불해야 합니다. 그러나 Braineous를 사용하면 고객은 단순히 가공되지 않은 데이터를 보내기만 하면 '구성'을 통해 시스템들끼리 대화하도록 할 수 있어 시간과 비용을 절약할 수 있습니다.
기계 학습
해당 플랫폼이 기계 학습에 어떤 문제를 해결하는지 궁금하신가요? 전체적으로 볼 때, 기계 학습은 컴퓨터에게 어떻게 생각하고 결정을 내리게 할지 가르치는 방법입니다. 이는 예측으로 전환될 수 있는데, 데이터의 패턴을 학습하여 인간 두뇌처럼 대규모로 예측을 할 수 있습니다. 예측의 정확성이 목표입니다. 항공 산업에서 예를 들어 항공사일 경우, 2주 후의 지연 및 제한과 관련된 항공 네트워크가 어떻게 될지 예측할 수 있습니다. 이렇게 하면 조종사 및 승무원 근무 시간과 비행 계획을 더 잘 준비할 수 있습니다. 이를 통해 매출을 절약하고 고객 경험을 향상시키기 위해 그날 네트워크 내 다른 항공편에 승객을 탑승시키지 않도록 하는 최적화된 솔루션을 제공할 수 있습니다.
이를 위해 고수준에서, 해당 기계를 응용 프로그램에 필요한 데이터로 훈련해야 합니다. 훈련 세트에서 사용할 수 있는 데이터가 더 많을수록 예측 정확도가 높아집니다. 이것이 Braineous 데이터 파이프라인 플랫폼이 초점을 맞추는 곳으로, 이 플랫폼은 대규모로 데이터를 처리할 수 있습니다.
해당 플랫폼은 주요 목표인 AI 모델을 구축하는 데 필요한 데이터 과학자와 기계 학습 엔지니어에게 필요한 인프라를 제공할 것입니다.
데이터 커넥터
At the moment, our platform is equipped with core connectors for MongoDB and MySQL as target staging stores. In upcoming updates, we plan to introduce additional target data connectors, including:
- Postgresql
- Oracle
- Snowflake
- Amazon Redshift
- Elasticsearch
- Clickhouse
Braineous offers a Staging Store Framework that empowers developers to create custom connectors. For a practical tutorial, check out our guide on how to Create a Data Connector.
Ready to Get Started? Let's dive in!
스텝 1: MongoDB 설치하기
brew tap mongodb/brew
brew update
brew install mongodb-community@7.0
위 명령어를 순서대로 실행하여 MongoDB를 설치해보세요! 만약 도움이 필요하다면 언제든지 물어보세요. :)
단계 2: Braineous 다운로드하기
Braineous-1.0.0-CR2를 다운로드합니다. '크기가 너무 크므로 로드할 수 없습니다' 메시지는 무시하고 '다운로드' 버튼을 클릭하세요.
자세한 지침: 릴리스 페이지
단계 3: Zookeeper 시작하기
cd braineous-1.0.0-cr2/bin
./start_zookeper.sh
Step 4: Start Kafka
cd braineous-1.0.0-cr2/bin
./start_kafka.sh
Step 5: Flink 시작하기
cd braineous-1.0.0-cr2/bin
./start_flink.sh
단계 6: 하이브 메타스토어 시작하기
cd braineous-1.0.0-cr2/bin
./start_metastore.sh
단계 7: Braineous 시작하기
cd braineous-1.0.0-cr2/bin
./start_braineous.sh
단계 8 : Braineous 설치 테스트
cd braineous-1.0.0-cr2/bin
./test_installation.sh
스텝 9: API 키 및 API 시크릿 생성하기
테넌트 생성
./pipemon.sh
브레이너스
임차인이시면 [l]을 눌러 로그인하십시오. 테넌트를 생성해야 하는 경우 [c]를 누르십시오. c 테넌트 생성 테넌트: cr2_tenant 이메일: cr2@cr2.com 비밀번호: password 테넌트 생성 성공 {principal: cb4e0e9f-1b06-4e38-8f8a-395775d1a83f, apiSecret: e41bc11a-83ea-42e1-96c1-5bb136de9ce1, name: cr2_tenant, email: cr2@cr2.com, password: 5F4DCC3B5AA765D61D8327DEB882CF99, apiKey: cb4e0e9f-1b06-4e38-8f8a-395775d1a83f} Data Platform 사용을 위해 API 시크릿을 안전하게 보관해주세요. 보안상의 이유로 이후에는 표시되지 않을 것입니다.
튜토리얼에 생성된 API 키와 API 시크릿을 사용해주세요.
데이터 파이프라인 생성
감사합니다.
Sohil Shah: Braineous의 창립자: AppGal Labs 바로가기