요약
- .NET 채널은 스레드 동기화와 같은 공통적인 도전 과제를 관리하지 않고도 정보의 고효율, 동시/병렬 처리를 쉽게 달성할 수 있는 방법이다.
- .NET 채널은 판별된 연합체와 잘 어울리며 서로 다른 유형의 데이터를 동시에 하나의 스트림으로 처리하고 출력하는 방법이다.
- 함께 사용할 때 .NET 채널과 판별된 연합체는 데이터 스트림을 깔끔하고 쉽게 처리하고 결합할 수 있다.
.NET 및 판별된 연합체
만약 TypeScript나 F# 또는 DUs를 원래 지원하는 언어를 사용해 보았다면 이미 익숙할 것입니다.
현재 C#은 언어 기능으로 판별된 연합을 지원하지 않지만, 여러 달 동안 (몇 년째인가요?) 로드맵에 있었습니다.
오늘날에는 두 .NET 라이브러리를 사용하여 C# 코드베이스에 DU와 비슷한 패턴을 쉽게 추가할 수 있습니다:
- OneOf
- dunet
양식 그대로 쓰신 후에 코드를 Markdown 형식으로 변경해 드릴게요.
둘 다 C# 코드베이스에서 DUs를 점진적으로 적용하기 쉽게 만들어줍니다.
DUs에는 많은 혜택과 사용 사례가 있지만, 내가 가장 좋아하는 것 중 하나는 .NET 채널과 함께 사용하는 것입니다. 하나의 레코드를 다른 논리로 처리한 후 결과를 결합해야 하는 경우가 많기 때문이에요.
일반적으로 그러려면 코드가 이렇게 나올 수 있어요:
foreach (var record in records)
{
// Serially execute each action.
var result1 = await ProcessingAction1Async(record);
var result2 = await ProcessingAction2Async(record);
var result3 = await ProcessingAction3Async(record);
// Get all of the results and perform the final step.
await FinalActionAsync(result1, result2, result3);
}
이것은 각 단계가 빠르고 병렬화될 수 없는 경우에는 괜찮습니다. 하지만 각 단계가 비용이 들고 실제로 이산적인 경우 (이전 결과에 의존하지 않음) 어떨까요? 모든 세 단계를 병렬로 처리하면 하드웨어를 보다 효과적으로 활용하고 시스템의 처리량을 향상시킬 수 있습니다.
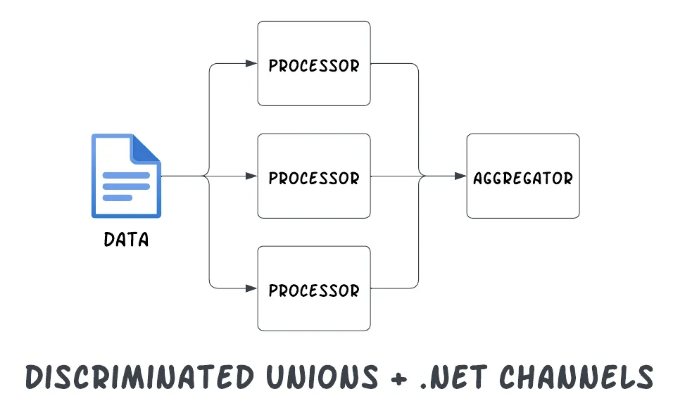
오늘은 C#의 구분된 연합(discriminated unions)을 사용하여 .NET 채널(channels)과 함께 이를 정확히 어떻게 구현할 수 있는지 살펴보겠습니다.
사용 사례
CSV 파일을 처리하는 시스템의 디자인을 상상해보세요. 이 파일에는 통화 로그 목록이 포함되어 있으며 처리 파이프라인은 통화 레코드에서 병렬로 일련의 프롬프트(prompt)를 실행하여 다음을 수행해야 한다고 가정해보겠습니다:
- 전화의 긴급도를 파악합니다.
- 긴급도와는 별개로 전화를 어떤 부서로 연결할지 결정합니다.
- 전화와 관련된 키워드를 추출하여 태그를 붙여 나중에 찾을 수 있도록 합니다.
이러한 작업들은 모두 별개로 진행될 수 있으므로 각각을 병렬로 처리할 수 있습니다 (예: 다른 LLM 프롬프트를 사용하여). 그런 다음 통화 로그의 각 요소를 마지막에 하나로 집계하여 라우팅할 수 있는 단일 레코드로 만들 수 있습니다.
.NET 채널과 디스크리미네이트 유니온에 대한 완벽한 사용 사례.
디스크리미네이트 유니온
이 경우에 데이터 구조를 모델링하는 합리적인 방법은 적어도 세 가지가 있습니다:
- 기본 클래스를 사용하는 방법; 하지만 호출 레코드의 ID를 공유하는 것 외에는 여러 부분이 대부분 개별적입니다.
- Fragment
T와 같은 제네릭 클래스를 사용하는 방법; 그러나 실제 집계 측면에서 작업을 처리하는 데 일부 에르고노믹 문제가 있습니다. - Discriminated union을 사용하는 방법!
하나의 호출 레코드에서 세 가지 유형의 Facet이 생성될 수 있는데, 이 세 가지 유형의 discriminated union을 사용하여 구조를 모델링할 수 있습니다:
public record UrgencyScore;
public record RoutingTicket;
public record KeywordTags;
/// <summary>
/// "세 가지 중 하나"를 나타내는 discriminated union
/// </summary>
[GenerateOneOf]
public partial class CallLogFacet
: OneOfBase<UrgencyScore, RoutingTicket, KeywordTags>;
CallLogFacet 유형은 UrgencyScore, RoutingTicket 또는 KeywordTags 중 하나일 수 있습니다.
FragmentT 구현과 명백한 유사성이 있지만 DU는 기본 클래스 또는 인터페이스를 정의할 필요없이 세 가지 특정 유형만을 제한합니다. DU는 계약의 위치를 대신합니다.
또한, DU는 소진을 강제하는 특성을 갖고 있어 더 견고한 코드를 작성하는 데 도움이 됩니다. (더 자세한 내용은 다른 기사를 확인해보세요: 더 나은 코드를 위한 TypeScript 레코드 유형 사용).
데이터 원본 설정
호출 기록이 과연 어떻게 공급되는지 정확한 메커니즘이 중요하지 않으며, 이 예시의 범위를 벗어납니다. 사실, 이 예시에서는 숫자 시퀀스를 생성하는 간단한 Enumerable을 사용합니다. (실제 세계에서는 이 데이터를 CSV의 한 행이나 데이터베이스에서 읽어올 수 있습니다):
// 우리의 producer는 메타데이터를 생성하려는 호출의 각 측면을 처리하는 비동기 작업들의 순서를 생성합니다.
var producerTasks = Enumerable
.Range(0, 100)
.AsParallel()
.WithDegreeOfParallelism(10)
.SelectMany(i => {
return new Task[] {
// TODO: 병렬로 작업 수행하기
};
});
0부터 100까지의 숫자 범위(이를 호출 센터 로그 데이터베이스의 100개 행으로 상상해보세요)에 대해 코드는 긴급도, 라우팅 및 키워드를 결정하기 위해 일부 작업을 병렬로 실행합니다.
채널 설정하기
이를 지원하기 위해 먼저 System.Threading.Channel을 생성하여 레코드를 병렬로 처리하고 그 정보를 동기적으로 단일 집계기에 집계하는 것으로 시작하십시오.
여기서 채널은 병렬 처리의 동기화를 읽기 측의 단일 스레드로 단순화시키므로 적합한 추상화입니다.
이 경우, 튜플 타입을 사용하여 채널을 생성합니다. 이 튜플은 ID를 나타내는 정수와 생성된 통화 로그의 facet을 가지고 있습니다:
var channel = Channel.CreateUnbounded<(int, CallLogFacet)>();
메인 처리 흐름
주요 처리 흐름은 레코드를 로드한 다음 레코드 세트를 횡단/병렬 처리 작업으로 시작합니다:
// 👇 집계기를 시작하지만 기다리지는 않음
var aggregatorTask = aggregator(channel.Reader);
// 👇 연속된 통화 레코드에 대해 세 가지 측면을 병렬로 처리
var producerTasks = Enumerable
.Range(0, 20)
.AsParallel()
.WithDegreeOfParallelism(10)
.SelectMany(i =>
{
return new Task[]
{
urgencyProducer(channel.Writer, i),
routingProducer(channel.Writer, i),
keywordsProducer(channel.Writer, i)
};
});
// 👇 모든 병행/병렬 작업의 완료를 기다립니다.
Task.WaitAll([.. producerTasks]);
channel.Writer.Complete();
// 👇 집계기가 모든 측면을 받기를 기다립니다.
await aggregatorTask;
프로듀서들이 호출되지만 기다리지 않는 방법에 유의하세요; 대신에 그들은 단순히 TypeScript에서 Promise의 동등한 Task로 수집됩니다.
프로듀서들
이 경우, 각 "프로듀서"는 단순히 정보 단편을 나타내는 클래스 인스턴스를 생성할 것입니다. 실제로는 코드가 실제 긴급도 점수를 계산하기 위해 LLM에 연결하거나 라우팅 티켓 또는 키워드를 계산할 수 있습니다:
var urgencyProducer = async (
ChannelWriter<(int, CallLogFacet)> writer, int callRecord
) =>
{
// TODO: 이곳에서 긴급성을 계산하는 실제 논리
await writer.WriteAsync((callRecord, new UrgencyScore()));
};
var routingProducer = async (
ChannelWriter<(int, CallLogFacet)> writer,
int callRecord
) =>
{
// TODO: 이곳에서 라우팅을 결정하는 실제 논리
await writer.WriteAsync((callRecord, new RoutingTicket()));
};
var keywordsProducer = async (
ChannelWriter<(int, CallLogFacet)> writer,
int callRecord
) =>
{
// TODO: 이곳에서 키워드를 추출하는 실제 논리
await writer.WriteAsync((callRecord, new KeywordTags()));
};
리더
그리고 마지막으로, 채널에서 메시지를 읽고 통화 기록이 모두 준비되었는지 확인하는 집계기가 있습니다. 그렇다면 경로 지정을 위해 보내줍니다:
// 채널의 리더 측은 패싯을 한 곳에 집계하고 경로 지정을 위해 통화 로그를 전송합니다.
var aggregator = async (ChannelReader<(
int RecordId,
CallLogFacet Facet
)> reader) =>
{
var state = new Dictionary<int, CallLog>();
while (await reader.WaitToReadAsync())
{
// 채널에서 개별 메시지를 읽기
if (!reader.TryRead(out var part))
{
continue;
}
if (!state.ContainsKey(part.RecordId))
{
// 아직 패싯을 받지 않았다면 로그 초기화
state[part.RecordId] = new CallLog();
}
var log = state[part.RecordId];
// 👇 각 패싯을 사용하여 로그 업데이트
part.Facet.Switch(
urgency => log.Urgency = urgency,
routing => log.Routing = routing,
keywords => log.Keywords = keywords
// 💡 이 블록은 "모두 다루는" 블록이며 Fragment<T>나 기본 클래스 제약 조건을 사용하는 것과 달리
// 가능한 모든 경우를 처리하도록 코드를 강제합니다.
);
if (log.IsReady)
{
// 로그에 세 가지 부분이 모두 집계되었으면 경로 지정
Console.WriteLine($"통화 레코드 {part.RecordId} 준비 완료; 경로 지정 중...");
await log.RouteAsync();
}
}
};
채널이 통화 로그의 세 가지 완전히 다른 패싯을 생성할 수 있음에도 불구하고, 채널(read) 측의 패싯 처리는 DU와 채널 기반 동시성 구현으로 인해 간결하고 명확합니다. 이러한 단계는 병렬로 실행되지만 명료하게 처리됩니다.
마무리 생각하기
디스크리미네이션 유니언은 .NET 채널과 아주 잘 어울립니다. 작업 부하를 병렬화할 수 있고 작업의 각 부분이 독립적인 결과물을 생성할 때 특히 좋습니다. 채널은 멀티스레드 작업에서 동기화 관련 복잡성을 많이 줄여주는데 DU는 여러 유형의 출력을 생성할 수 있는 채널과 작업할 때 에르고노믹스를 향상시키고 결과 조각을 통합할 때 완전성 제약을 제공합니다.
C#은 현재 DU에 네이티브 지원이 부족하지만 dunet과 OneOf 같은 라이브러리는 C#에서 DU를 쉽게 채택할 수 있도록 지원하며 이 예제와 같은 작업에 좋은 도구입니다.