LinkedIn이 실시간 처리를 위해 Apache Beam을 어떻게 활용하는지에 대한 주요 통찰
목차
- 컨텍스트
- 통합 스트리밍 및 배치 파이프라인
- 악용 방지 및 거의 실시간 AI 모델링
- 알림 플랫폼
- 관리되는 스트리밍 처리 플랫폼
- 실시간 ML 피처 생성
소개
나는 왜 항상 스트림/실시간 처리에 매료되는지 잘 모르겠다. 배치 패러다임과 비교할 때 완전히 새로운 세계인 것 같다. 배치 파이프라인에서 잠시 기다리는 것보다 거의 즉각적인 결과를 얻는 것이 더 매력적일지도 모른다.
그런데 이렇게 스트림/실시간 처리에 관심을 갖게 된 이유를 생각하는 대신, 어쨌든 대형 기술 기업들의 다른 실시간 사례 연구에 대해 깊이 파고들어보자. 이번에는 LinkedIn이 Apache Beam의 도움을 받아 하루에 4조 건의 실시간 이벤트를 처리하며 전 세계 9억 5천만 명 이상의 사용자에게 서비스하는 3000개 데이터 파이프라인을 데이터 센터 전체에 두고 있는 방법에 대해 알아볼 것이다.
배경
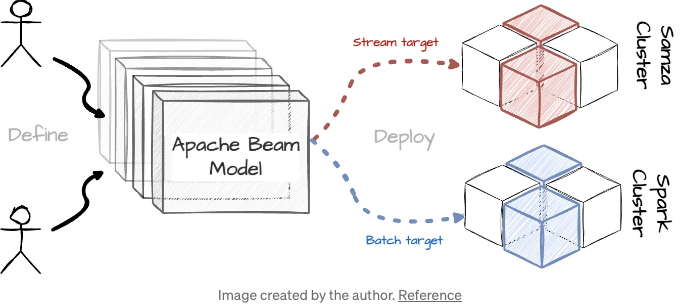
매일 LinkedIn의 실시간 인프라는 전 세계 9억 5천만 명 이상의 사용자에게 서비스하는 데 필요한 약 4조 건의 이벤트를 처리해야 한다. 2023년 말, LinkedIn 엔지니어링팀은 Apache Beam의 도움으로 스트리밍 처리를 혁신적으로 개선했다는 훌륭한 기사를 발표했다. 이 프레임워크는 Apache Samza(실시간 처리 엔진)와 Apache Spark(배치 처리 엔진)에서 실행 가능한 능력을 통해 LinkedIn에서 스트림과 배치 처리를 통합시켰고, 이로써 새로운 파이프라인 개발 주기를 몇 달에서 몇 일로 줄일 수 있었다.
그러나 람다에는 한 가지 큰 단점이 있습니다: 두 개의 코드베이스와 두 개의 배치 및 스트리밍 데이터 엔진을 유지해야 합니다. 이로 인해 2016년 Apache Beam이 출시되면서 LinkedIn에게 큰 전환점이 되었습니다. Apache Beam은 Python, Go 및 Java를 지원하는 오픈 소스 통합 프로그래밍 모델을 제공하여 배치 및 스트리밍 처리를 위한 이상적인 솔루션을 제공했습니다. 이는 어떤 엔진에서도 다국어 파이프라인을 구축하고 실행하는 데 적합한 것입니다. LinkedIn은 첫 번째 사용 사례를 도입하고 2018년에는 Beam을 위한 Apache Samza 러너를 개발했습니다. 2019년까지 Beam 파이프라인은 여러 중요한 사용 사례를 지원하고 있습니다.
아래 섹션에서는 LinkedIn에서 Apache Beam을 활용하는 몇 가지 사용 사례를 소개하겠습니다.
통합된 스트리밍 및 배치 파이프라인
LinkedIn이 Apache Beam을 활용한 첫 번째 사용 사례 중 하나는 실시간 계산과 주기적인 백필링 요구 사항이 포함되어 있었습니다. 예를 들어, LinkedIn의 표준화 프로세스는 AI 모델을 활용하여 사용자 입력 (예: 직책 또는 기술)을 직업 추천을 위한 미리 정의된 내부 ID로 매핑하는 일련의 파이프라인을 보유하고 있습니다. (예: "데이터 엔지니어"와 "빅 데이터 엔지니어" 사이의 표준화). 이러한 프로세스는 사용자 업데이트에 적응하려면 실시간 처리 능력이 필요하며 새로운 AI 모델이 출시될 때 백필링 능력이 필요합니다.
처음에는 백필링 작업에 5,000GB 시간 이상의 메모리와 총 4,000시간 가량의 CPU 시간이 필요했습니다. 따라서 LinkedIn 엔지니어들은 "하나의 코드베이스를 유지하면서 배치 작업 또는 스트리밍 작업으로 실행할 수 있는 방법이 있는지" 궁금해했습니다. 이제 이에 대한 솔루션을 짐작할 수 있습니다.
바로 Apache Beam입니다.
Apache Beam API를 사용하면 LinkedIn 엔지니어들은 비즈니스 로직을 한 번 구현하여 실시간 표준화 및 백필링 프로세스에서 효율적으로 실행할 수 있습니다. Beam의 유연성을 통해 사용자는 파이프라인 러너와 러너별 구성과 같은 다양한 측면을 사용자 정의할 수 있습니다. 이는 기반이 되는 인프라를 추상화하고 LinkedIn이 데이터 처리 엔진을 전환할 수 있도록 신속하게 해줍니다.
LinkedIn이 표준화된 파이프라인을 Apache Beam으로 마이그레이션한 이후의 인상적인 숫자는 다음과 같습니다:
- 통합 Apache Beam 파이프라인으로의 일괄 처리 파이프라인 이전은 메모리 및 CPU 사용량에서 50%의 큰 개선을 이끌어냈습니다 (~5000GB RAM 시간 및 ~4000 CPU 시간에서 ~2000 RAM GB 시간 및 ~1700 CPU 시간으로)
- 처리 시간은 7.5시간에서 25분으로 개선되었습니다.
반-악용 및 거의 실시간 AI 모델링
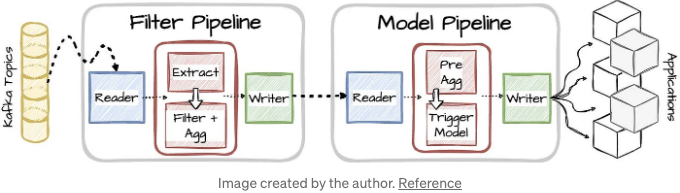
LinkedIn의 반-악용 AI 팀은 가짜 계정 생성 또는 회원 프로필 스크래핑과 같은 다양한 악용 형태를 탐지하고 예방할 수 있는 AI 및 딥 러닝 모델을 생성, 배포 및 유지하는 역할을 맡고 있습니다. 이 플랫폼은 두 개의 스트리밍 Apache Beam 파이프라인을 활용합니다:
-
필터 파이프라인은 Kafka에서 사용자 활동 이벤트를 받아 필요한 필드를 추출하고 이벤트를 집계 및 필터링한 후 하류 파이프라인으로 출력합니다.
-
모델 파이프라인은 이러한 필터링된 메시지를 소비하고 정의된 시간 창으로 회원 활동을 집계합니다. 그 후, 파이프라인은 AI 스코어링 모델을 트리거하고 악용 점수를 다양한 애플리케이션에 작성합니다.
Apache Beam의 플러그인 아키텍처의 유연성과 다양한 I/O 옵션 지원 덕분에 안티 악용 플랫폼 엔지니어들은 카프카 및 키-값 저장소와 파이프라인을 통합할 수 있었습니다. LinkedIn은 악용 행위를 라벨링하는 데 걸리는 시간을 1일에서 5분으로 줄이고 초당 300만 건 이상의 쿼리 처리량을 달성했습니다.
알림 플랫폼
Apache Beam과 Apache Samza는 LinkedIn의 대규모 알림 플랫폼을 지원합니다. Apache Beam 파이프라인은 LinkedIn 사용자의 모든 이벤트를 수신, 집계 및 처리한 후 하류 머신러닝 모델로 데이터를 보냅니다. 그런 다음 모델은 사용자의 과거 활동에 기반한 맞춤형 알림을 제공합니다. 결과적으로 LinkedIn 회원들은 관련성 높고 실행 가능한 활동 기반 알림을 받게 됩니다.
관리형 스트리밍 처리 플랫폼
성공적인 시험 운행을 거친 후에는 LinkedIn 내에서 Beam을 파이프라인 개발에 사용하는 수요가 증가했습니다. 따라서, 빔을 활용하여 내부적인 프로세스를 최적화하고 자동화하기 위해 관리형 빔이라는 플랫폼을 개발했습니다. 이 플랫폼을 통해 사용자들은 다음과 같은 여러 방법으로 빔 파이프라인을 개발할 수 있습니다:
- 빔 SDK를 사용하면 LinkedIn 엔지니어들이 재사용 가능한 사용자 정의 파이프라인을 만들고 표준 PTransforms로 노출할 수 있습니다. 이는 새로운 파이프라인을 구축하는 데 사용되는 기본 구성 요소로 작용합니다.
- 이 플랫폼에는 배포 UI, 운영 대시보드, 관리 도구 및 자동화된 파이프라인 라이프사이클 관리와 같은 기능을 제공하는 제어 평면이 포함되어 있습니다.
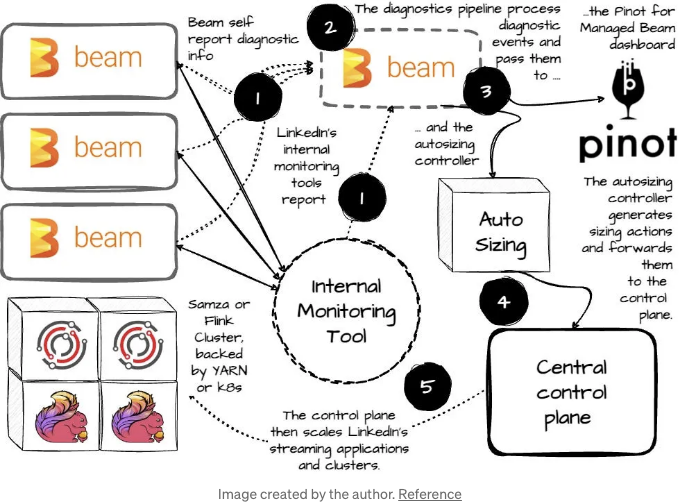
- 러너 프로세스와 사용자 정의 함수 (UDF)의 독립성을 보장하기 위해 관리형 빔은 이 둘을 gRPC를 통해 통신하는 두 개의 독립적인 프로세스로서 Samza 컨테이너에서 실행되는 두 개의 별개의 JAR 파일로 패키징합니다. 이 설정을 통해 LinkedIn은 사용자 로직이 망가질 염려 없이 자동화된 프레임워크 업그레이드의 이점을 활용할 수 있었습니다. (사용자 정의 함수 (UDFs)와 러너 프로세스의 분리)
- 비즈니스 가치에 따라 Beam 파이프라인 보고서 진단 정보를 Kafka 토픽 형식으로 제공하고, 관리형 빔은 내부 모니터링 이벤트 및 로그를 처리한 후 이를 자동 크기 조정 컨트롤러로 전달하여 Apache Pinot에 기록합니다. Apache Pinot은 관리형 빔의 운영 및 분석 대시보드에 사용됩니다.
- 관리형 빔 제어 평면은 자동 크기 조정 컨트롤러에서 수신한 신호를 기반으로 LinkedIn의 스트리밍 애플리케이션 및 클러스터의 크기를 조절합니다.
실시간 ML 기능 생성
LinkedIn에서는 작업 추천 및 검색 피드와 같은 핵심 기능이 ML 모델에 크게 의존합니다. 그러나 Apache Beam 이전에는 LinkedIn 회원의 작업 후 24~48시간의 지연이 발생하는 원래 오프라인 머신러닝(ML) 기능 생성 파이프라인이 있었습니다.
이 문제를 해결하기 위해 LinkedIn은 Managed Apache Beam을 사용했습니다.
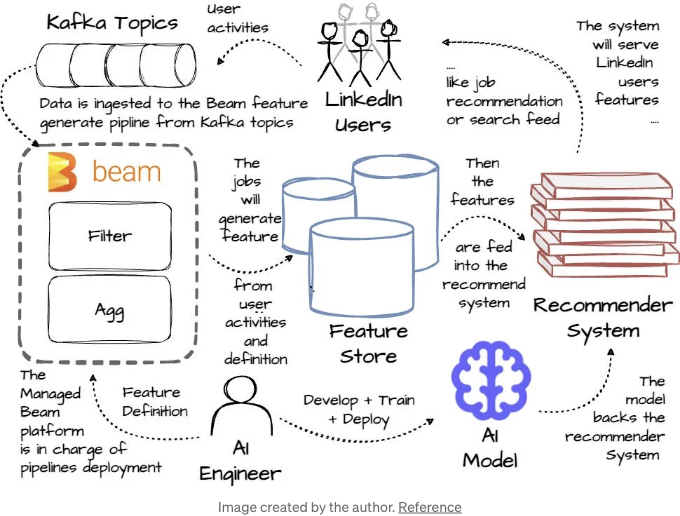
LinkedIn은 Managed Beam을 기반으로 한 ML 피처 생성을 위한 호스팅 플랫폼을 구축했습니다. 이 플랫폼은 AI 엔지니어들에게 실시간 피처를 제공하면서 배포 및 운영 복잡성을 추상화합니다:
- 먼저, Managed Beam을 사용하여 피처 정의를 생성하고 배포합니다.
- 스트리밍 Apache Beam 파이프라인은 Kafka에서 이벤트를 실시간으로 전처리하여 머신러닝 피처를 생성하고 이를 피처 스토어에 출력합니다.
- 다른 Beam 파이프라인은 피처 스토어에서 데이터를 읽어 처리하고 결과를 추천 시스템으로 라우팅합니다.
- 이 새로운 플랫폼은 24-48시간이 아닌 몇 초의 낮은 대기 시간을 달성하는 데 도움이 됩니다.
이러한 LinkedIn의 새로운 플랫폼은 본래의 실시간 솔루션에서의 람다 아키텍처의 복잡성이 문제입니다; 두 개의 코드베이스와 두 개의 별도 환경을 유지해야 합니다.
Apache Beam은 이와 같은 문제를 해결하기 위해 처음 개발되었습니다.
Twitter가 람다 아키텍처의 도전 과제를 다루는 방식과 비교했을 때(얼마 전에 블로그로 작성한 내용인데요), LinkedIn은 Twitter처럼 전체 솔루션을 카파 아키텍처로 변경하지 않았습니다. 대신 LinkedIn은 현재의 아키텍처를 유지하고 Apache Beam의 도움으로 최적화 및 개선했습니다.
지금까지 읽어주셔서 감사합니다. 다음 블로그에서 만나요.
참고 자료
[1] Bingfeng Xia, Xinyu Liu, Revolutionizing Real-Time Streaming Processing: 4 Trillion Events Daily at LinkedIn (2023)
제 뉴스레터는 매주 보내는 블로그형 이메일로, 제가 더 똑똑한 분들로부터 배운 것들을 기록합니다.
그러니 저와 함께 성장하고 배우고 싶다면, 여기에서 구독해주세요: https://vutr.substack.com.