스레드 풀은 동시 프로그래밍에서 기본적인 개념으로 여러 가지 중요한 이유로 사용됩니다. 다음은 우리가 스레드 풀을 필요로 하는 주요 이유입니다:
1. 자원 관리
- 제어된 스레드 생성: 각 작업마다 새 스레드를 생성하는 것은 과도한 자원 소비와 시스템 불안정을 유발할 수 있습니다. 스레드 풀은 일정 수의 스레드를 관리함으로써 계속해서 스레드를 생성하고 파괴하는 불필요한 오버헤드와 비효율성을 피합니다.
- 최적화된 자원 활용: 고정된 스레드 세트를 재사용함으로써 스레드 풀은 시스템 자원을 더 잘 활용하여 예측 가능하고 안정적인 애플리케이션 성능을 제공합니다.
2. 성능 향상
-
지연 시간 감소: 스레드 풀은 이미 생성되어 작업을 할당 받을 준비가 된 스레드가 있기 때문에 작업 실행에 관련된 지연 시간을 줄일 수 있습니다. 이는 스레드 생성과 관련된 지연을 피할 수 있습니다.
-
향상된 처리량: 여러 스레드를 동시에 관리함으로써, 스레드 풀은 응용 프로그램의 전체 처리량을 향상시킬 수 있습니다, 특히 멀티코어 프로세서에서.
3. 확장성
-
동적 부하 분산: 워크 스틸링 풀과 같은 고급 스레드 풀은 유휴 스레드가 바쁜 스레드로부터 작업을 가져와 CPU 이용률을 최적화하는 동적 부하 분산 기능을 제공합니다.
-
멀티 코어 시스템 전체 가능성: 스레드 풀은 여러 CPU 코어를 효율적으로 활용할 수 있도록 설계되어 있어, 현대적인 멀티코어 시스템에서 응용 프로그램이 확장되고 더 나은 성능을 발휘할 수 있게 됩니다.
4. 향상된 안정성
- 제어된 동시성: 동시 실행 스레드 수를 제한함으로써, 스레드 풀은 스레드 경합, 데드락 및 리소스 고갈과 같은 문제를 예방하여 더 안정적이고 신뢰할 수 있는 애플리케이션을 구축하는 데 도움이 됩니다.
- 일관된 성능: 스레드 풀은 작업이 어떻게 예약되고 실행되는지 관리함으로써 다양한 부하 하에서도 일관된 애플리케이션 성능을 유지하는 데 도움이 됩니다.
사용 사례 예시
- 웹 서버: 웹 서버는 종종 스레드 풀을 사용하여 여러 클라이언트 요청을 동시에 처리합니다. 각 요청은 풀에서 스레드에 할당되어 서버가 각 요청에 대해 새 스레드를 생성하지 않고도 많은 요청을 효율적으로 처리할 수 있게 합니다.
- 데이터베이스 연결 풀: 스레드 풀과 유사하게 데이터베이스 연결 풀은 여러 작업에서 재사용할 수 있는 데이터베이스 연결 풀을 관리하여 데이터베이스 액세스의 효율성을 향상시킵니다.
이 글에서는 두 가지 유형의 스레드 풀에 대해 논의하겠습니다:-
- 고정 스레드 풀
- Work Stealing Pool
고정 스레드 풀과 워크 스틸링 풀 중에서 선택하는 것은 애플리케이션의 특정 요구사항과 특성에 따라 다릅니다. 아래는 고정 스레드 풀을 워크 스틸링 풀 보다 선호하는 경우와 고려해야 할 사항들입니다:
고정 스레드 풀을 선호하는 경우
-
예측 가능한 작업 부하:
-
일정한 작업 소요 시간: 작업이 상대적으로 균일하고 예측 가능한 실행 시간을 갖는다면, 고정 스레드 풀이 작업 부하를 효과적으로 관리할 수 있습니다.
-
알려진 작업 양: 작업의 수와 빈도가 균일하고 예측 가능할 때 고정 스레드 풀은 안정적인 성능을 제공합니다.
- 자원 제한:
- 제한된 자원: CPU 및 메모리 자원이 제한적인 환경에서 고정 스레드 풀은 동시 스레드의 수를 제한하여 자원 사용을 더 잘 제어할 수 있습니다.
- 데이터베이스 연결: 데이터베이스 연결을 포함하는 작업을 관리할 때 스레드 수를 제한하면 동시 데이터베이스 연결의 수를 제어하여 자원 고갈을 막을 수 있습니다.
- 간편함과 제어:
- 간단한 작업 관리: 고정 스레드 풀은 모든 작업을 처리하는 일정한 수의 스레드가 있는 간단한 모델로 이해하고 관리하기 쉽습니다.
- 예측 가능한 동작: 고정 스레드 풀은 부하 하에서 더 예측 가능한 동작을 보여주어 성능 및 자원 요구사항을 추정하기 쉽게 합니다.
- 제한된 작업 도둑형 혜택:
- 낮은 오버헤드: 여러 개의 데크를 관리하고 작업 도둑 기구의 오버헤드가 혜택보다 크다면(예: 작업 실행 시간의 분산이 거의 없는 응용 프로그램의 경우) 고정 스레드 풀이 선호됩니다.
- 낮은 경쟁: 작업이 자주 스레드를 비워두지 않는 경우(작업이 일관되게 분배되고 스레드가 계속해서 바쁜 경우) 작업 도둑형의 혜택은 줄어듭니다.
작업 도둑형 풀을 선호하는 경우
- 매우 다양한 작업 부하:
- 불규칙한 작업 시간: 작업이 실행 시간이 매우 다양할 경우, 워크 스틸링 풀은 여유 스레드가 바쁜 스레드로부터 작업을 훔쳐가게 함으로써 동적으로 작업 부하를 균형있게 유지할 수 있습니다.
- 예측할 수 없는 작업 양: 작업의 수와 빈도가 예측할 수 없는 상황에서는 워크 스틸링 풀이 작업을 동적으로 재분배함으로써 더 잘 적응합니다.
- CPU 활용 최대화:
- 높은 병행성: 워크 스틸링 풀은 스레드의 유휴 시간을 최소화하여 CPU 활용률을 극대화하기 위해 설계되었습니다. CPU 바운드 작업에 적합합니다.
- 적응형 부하 분산: 작업이 자주 불균형하게 분배될 때, 워크 스틸링 풀은 더 나은 부하 분산과 자원 활용을 보장합니다.
- 복잡한 작업 그래프:
Example Scenarios
Fixed Thread Pool:
-
웹 서버: 각 요청이 유사한 양의 처리와 리소스 사용을 포함하는 일관된 수의 들어오는 요처 처리.
-
데이터베이스 주도 애플리케이션: 데이터베이스 연결 제한을 초과하지 않도록 고정된 개수의 동시 데이터베이스 작업 관리.
-
일괄 처리: 예정 작업이나 일괄 데이터 처리 작업과 같이 알려진 및 고정된 수의 작업 처리.
-
병렬 알고리즘: 병렬 알고리즘 및 분할 정복 전략과 같은 응용에서 작업이 하위 작업을 더 생성할 수 있는 경우, 워크 스틸링 풀은 이러한 동적 워크로드를 더 효율적으로 처리합니다.
-
재귀적 워크로드: 자연스럽게 더 작은 작업으로 분해되는 작업 부하의 경우, 워크 스틸링 풀에서 작업의 분산 관리는 더 나은 성능을 제공합니다.
Work-Stealing Pool:
- Data Processing Pipelines: This involves processing data streams with tasks having different complexities and execution times. Tasks can even create more subtasks dynamically.
- Real-Time Analytics: This is all about performing real-time data analytics with workloads that can vary unpredictably, requiring flexible task distribution.
- Parallel Computing: This refers to implementing parallel algorithms that gain from dynamic load balancing. For instance, recursive algorithms used in scientific computing.
Work-stealing pools provide dynamic load-balancing capabilities
Understanding the Work-Stealing Concept
워크 스틸링 풀에서는 각 워커 스레드가 자체 이중엔드 큐(deque)를 유지합니다. 이 작업의 탈중앙화된 접근 방식은 동적으로 작업을 분산하는 데 중요합니다. 아래에서는 작동 방식을 설명하겠습니다:
-
지역 큐:
-
풀 내 각 스레드는 자체 큐를 갖고 작업을 저장합니다.
-
스레드가 새 작업을 생성하면 자신의 큐에 넣습니다.
- 작업 실행:
- 스레드는 일반적으로 자체 deque에서 작업을 처리하며, 캐시 지역성을 유지하기 위해 후입선출(LIFO) 순서로 작업을 처리합니다.
3. 도난 메커니즘:
- 한 스레드의 deque가 비어있을 때, 그 스레드는 대기하지 않고 다른 스레드의 deque에서 작업을 도난하려고 시도합니다.
- 도난은 일반적으로 다른 스레드의 deque의 반대편에서(FIFO 순서) 이루어지며, 이는 다른 스레드가 접근하는 다른 끝과의 갈등을 최소화하기 위한 것입니다.
작업 흐름 예시
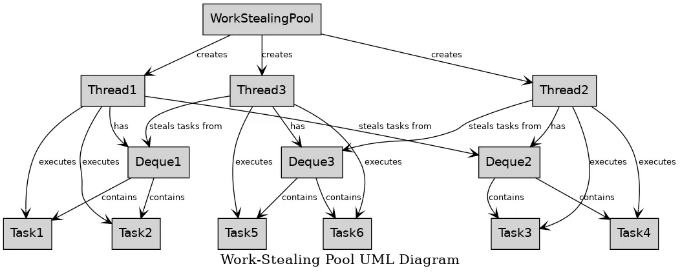
Hey there! Let's dive into an example that demonstrates how dynamic load balancing operates in a work-stealing pool:
- Task Submission:
Imagine we have a system with four threads (T1, T2, T3, T4).
- Thread T1 creates a set of tasks and adds them to its deque.
2. 작업 실행:
- T1은 자체 덱에서 작업을 실행 시작합니다.
- 한편, T2, T3 및 T4도 일부 작업이 담긴 자체 덱을 갖고 있습니다.
3. 고갈 및 훔침:
- T2는 자체 덱의 작업을 빠르게 완료합니다.
- 공백 상태가 되지 않고 다른 스레드의 덱에서 작업을 찾습니다.
- T2는 T1의 덱에 여전히 작업이 남아 있다는 것을 알게 되어 T1의 덱에서 작업을 훔쳐 실행을 시작합니다.
- 작업 균형 유지:
- 작업이 완료될 때마다 스레드는 자체 deque에서 업무를 계속 확인합니다.
- 만약 스레드의 deque가 비어 있다면, 다른 스레드로부터 작업을 빼앗아옵니다.
- 이 프로세스는 계속해서 동적으로 진행되며, 모든 스레드 사이에서 작업 부하를 균형있게 유지합니다.
마지막으로, 데이터베이스 연결 풀 관리
일반적으로는 이 목적을 위해 고정 스레드 풀이 사용됩니다.
왜 고정 스레드 풀이 사용되나요:
- 예측 가능성: 고정 스레드 풀은 미리 결정된 스레드 수를 가지고 있어 리소스 사용에 대한 예측 가능성을 제공합니다. 데이터베이스 연결 관리 시, 연결 수가 보통 제한되어 있기 때문에 중요합니다.
- 제어: 스레드 수를 제한함으로써 동시에 사용되는 데이터베이스 연결 수를 제어할 수 있어 데이터베이스가 과부하되지 않도록 할 수 있습니다.
- 자원 효율성: 고정 스레드 풀은 일련의 스레드를 재사용하여 스레드 생성 및 소멸에 따른 오버헤드를 줄입니다.
결론
Work Stealing Pools와 고정 스레드 풀은 각각의 장단점이 있으며 다른 시나리오에 적합합니다. 두 옵션 중 어떤 것을 선택할지는 작업의 성격, 원하는 부하 분산, 그리고 응용 프로그램의 특정 성능 요구에 따라 결정되어야 합니다.