
이전 글에서 백엔드 성능을 향상시키기 위한 몇 가지 코드 트릭을 자세히 소개했어요. 하지만 어떻게 주력할 부분을 알고 무엇을 최적화해야 하는지는 어떻게 알았을까요? 실제로 Cython과 같은 저수준 기술을 결합하여 강력한 이유가 있습니다.
제게는 Athenian에서 일하고 있답니다. Athenian은 엔지니어링 리더가 지속적인 개선을 통해 소프트웨어 개발 문화를 구축하는 데 도움을 주는 SaaS를 제공하고 있어요. 저희는 UX에서 지시한 엄격한 성능 목표를 갖고 있어요. 적절한 도구 없이는 훌륭한 P95 응답 시간을 달성하기 힘들어요. 그래서 우리는 고품질의 애플리케이션과 서비스로 자신을 둘러싸고 있어요:
- Sentry Distributed Tracing은 우리가 프로덕션 환경에서 특정 API 요청이 왜 느리게 실행되었는지 조사할 수 있게 해줍니다. 이 도구는 Python 도메인에서 작동해요.
- Prodfiler는 네이티브 CPU 성능을 독립적으로 살펴볼 수 있게 해주는 도구로, 모든 공유 라이브러리를 포함합니다.
- py-spy는 Ben Frederickson이 개발한 훌륭한 저부하 Python 프로파일러에요.
- Prometheus + Grafana는 즉각적인 상황을 모니터링하고 성능 재해 복구를 트리거하는 데 도움을 줍니다.
- Google 로그 기반 메트릭은 중요한 운영 이벤트의 빈발 빈도를 나타내며 이전 도구 체인을 보완합니다.
- Google Cloud SQL Insights는 개별 쿼리 수준에서의 PostgreSQL 성능을 모니터링하는 필수적인 관리형 PostgreSQL 성능 모니터입니다.
- explain.tensor.ru는 제가 가장 좋아하는 PostgreSQL 실행 계획 시각화 도구입니다. 항상 관련성이 있는 많은 자동 힌트를 제공해줘요.
오늘의 게시물에서는 느린 부분을 식별하고 속도를 높이기 위한 주간 루틴을 설명합니다. 특히 Sentry traces, py-spy 및 Prodfiler의 유용성을 보여드리겠습니다.
희생자 찾기
우리는 Sentry의 성능 개요 페이지에서 시작합니다. 우리는 몇 일에 한 번씩 확인합니다.
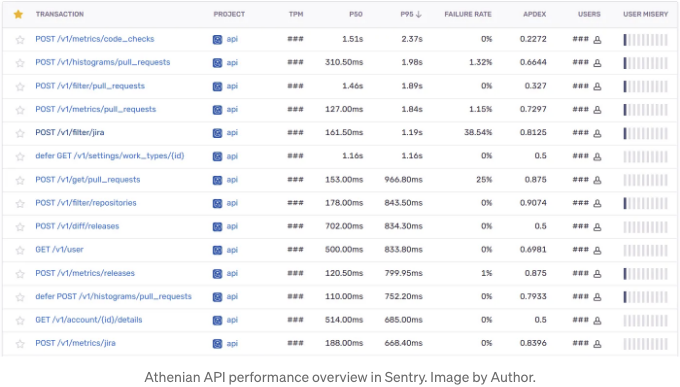
위의 표는 모든 API 엔드포인트에 대한 P50 및 P95 응답 시간 및 주요 요청 처리 후 실행된 보류 중인 작업(oops, that’s my muscle memory 일 때는 에러가 없으면)을 보여줍니다. 예를 들어, 캐시 업데이트와 같은 것입니다. Athenian API는 분석 API입니다. 수백만 개의 항목(예: PR, 릴리스, CI 실행, JIRA 이슈 메타데이터)을 집계하며 일반적으로 수십 개의 필터를 적용하고 실시간으로 통계 및 신뢰 구간을 계산합니다. 따라서 평균 응답 시간은 밀리초 대신 초로 측정됩니다.
P50 및 P95는 Prometheus / Grafana에서도 확인할 수 있으며 아직은 특별한 문제가 없습니다. 그러나 예를 들어 /metrics/code_checks와 같은 엔드포인트를 클릭하면 자세한 정보에 액세스하고 자세히 살펴볼 수 있습니다.
상세 정보 테이블은 선택한 엔드포인트의 분석된 추적을 지속시간을 내림차순으로 정렬하여 보여줍니다. 사용자 열이 아이피 주소 대신 사용자 ID를 표시하도록 Sentry 팀에 요청한 것에 대해 👏🙇♂️ 감사드립니다.
의심스러운 느린 엔드포인트 호출을 클릭하여 프로필과 유사한 구조를 연구하는 방식으로 진행합니다. (물론 코드 작성자에게) DB 및 CPU 병목 현상이 발생한 곳이 즉시 분명해집니다.
왼쪽 패널의 이름들은 수동 코드 계측의 결과입니다. 예를 들어, mine_check_runs() 함수 호출을 계측하는 방법을 살펴보겠습니다:
@sentry_span
async def mine_check_runs(...):
# 엔드포인트 로직
@sentry_span은 호출을 Sentry span - 트레이스 트리의 노드로 래핑하는 함수 데코레이터입니다. 물론 우리가 가진 모든 메서드를 데코레이팅하지는 않습니다. 대신, 측정할 만한 흥미로운 부분과 소음인 부분을 따릅니다.
sentry_sdk.start_span()은 내부의 경과 시간 측정을 수행합니다. sentry_sdk.Hub(sentry_sdk.Hub.current)와 함께 사용하는 것은 Sentry SDK에서 불완전한 asyncio 지원에 대한 해결책입니다. __tracebackhide__는 pytest와 Sentry의 콜 스택에서 래퍼 함수를 숨기는 마법같은 로컬 변수입니다.
/metrics/code_checks는 GitHub에 보고된 CI 실행에 대한 여러 통계를 반환합니다. GitHub Actions, CircleCI, Appveyor 등이 포함됩니다. 한 커밋은 수십 개, 심지어 수백 개의 CI 실행을 생성할 수 있으며, Sentry의 트레이스에 따르면 우리는 고객 X의 두 주 동안 164,610개의 CI 실행을 로드했습니다. DB에서 CI 실행을 가져오려면 약 10개의 JOIN이 필요합니다. 보통은 문제가 되지 않고 쿼리가 ~500ms 내에 완료되지만, 우리는 불행했습니다. 두 번째 문제는 _disambiguate_pull_requests() Python 함수에서 발생했습니다. GitHub에 보고된 CI 실행은 풀 리퀘스트가 아닌 커밋에 매핑됩니다. 그것이 GitHub의 동작 방식입니다. 결과적으로, 동일한 커밋을 가진 여러 PR이 있는 경우 CI를 트리거한 PR을 결정해야 합니다. _disambiguate_pull_requests()는 이러한 퍼즐을 해결하기 위해 여러 휴리스틱을 적용합니다. 우리는 이 함수 결과를 미리 계산할 수 있지만, 몇 가지 도메인 특정 문제 때문에 아직 그렇게 하지 않았습니다.
긴 이야기를 짧게 말하면, _disambiguate_pull_requests()에서 1초를 소비하는 것은 괜찮지 않으며, 내부를 자세히 살펴보고 최적화해야 합니다.
프로필, 재작성, 반복
Sentry 추적 메타데이터에 요청 본문을 저장해 두어서, 언제든 프로덕션 DB를 로컬로 재생할 수 있습니다. 함수의 인수를 디스크에 저장하고 매크로 벤치마크를 준비해 진행합니다.
# curl --data '{...}' http://localhost:8080/v1/metrics/code_checks
async def _disambiguate_pull_requests(*args, **kwargs):
with open("/tmp/args.pickle", "wb") as fout:
pickle.dump((args, kwargs), fout)
exit()
저는 벤치마킹을 위한 pytest 플러그인인 pytest-benchmark을 사용합니다.
def test__disambiguate_pull_requests(benchmark):
with open("/tmp/args.pickle", "rb") as fin:
args, kwargs = pickle.load(fin)
benchmark(_disambiguate_pull_requests, *args, **kwargs)
pytest --benchmark-min-rounds=N을 사용하여 벤치마크를 실행하십시오. 여기서 N은 정밀도와 벤치마크 시간 사이의 균형점입니다. N은 라운드 변동을 목표 수준으로 제한하는 데 충분히 큰 값이어야 합니다. 평균 대비 0.5%에서 2% 비율 사이를 목표로 삼습니다.
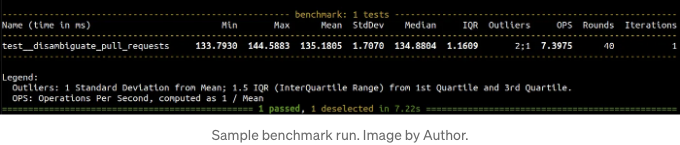
매크로벤치마크를 설정하고 이제 프로파일 최적화 주기로 진입합니다.
- 현재 코드의 프로필을 수집합니다.
- 프로필을 분석합니다: 병목 현상은 무엇인가요? 마지막 변경 사항이 도움이 되었나요?
- 프로필이 고르게 평평하게 나타나거나 더 최적화하기 어려울 때는 멈춥니다.
- 최적화 가설을 정립하고 코드를 그에 맞게 다시 작성합니다.
- 1단계로 이동합니다.
저는 py-spy로 프로필을 수집하는 것을 선호합니다. 이는 Python용 샘플링 프로파일러로, 프로세스의 메모리 덤프를 일정한 빈도로 읽어들인 후 쓰레드 스택을 인식하고 분석합니다. 샘플링 빈도가 늘어날수록 오버헤드가 자연스럽게 증가하며 언제나 절충점이 존재합니다. 일반적으로 괜찮은 결과를 얻기 위해 500 Hz로 설정합니다.
py-spy record -r 500 -o profile.ss -f speedscope -- pytest ...
py-spy는 speedscope 플레임그래프와 유사한 형식의 파일을 출력할 수 있습니다. 저는 "Left Heavy" 뷰의 speedscope를 좋아하며, 반복적인 벤치마크 반복을 조사하는 데 이상적입니다.


일반적으로 최적화된 프로파일 루프를 약 열 번 반복해야 벽에 부딪혀 멈춥니다. 위의 두 이미지는 최적화를 시작한 시점과 6회째 반복한 시점의 speedscope 프로파일입니다. 오른쪽의 관련없는 분홍색 불길이 더 넓어지고, 왼쪽의 일부 불길이 사라진 걸 볼 수 있습니다 — 이것은 좋은 징조입니다.
유감스럽게도, 대부분의 경우 매크로벤치마크는 일부 마이크로벤치마크 문제를 상속받아 컨텍스트에 대한 의존성이 있습니다. 물론, 성능 문제에 대한 최고의 해결책은 다른 팬더스 통합을 우회하는 대신 알고리즘을 변경하는 것입니다. 모두에게 Fedor Pikus의 "Design for Performance" 토크를 보길 권장합니다. C++을 걱정하지 마세요, 제시된 개념들은 보편적으로 적용할 수 있습니다.
모니터링 가정
문맥에 대한 의존성을 고려합니다. 특정 고객을 위해 _disambiguate_pull_requests()를 최적화했습니다. 다른 고객에 대한 성능 하락이 없는지 어떻게 확신할 수 있을까요? P95가 감소하는 대신 전체적인 영향은 뭘까요? Prodfiler가 도와줍니다.
eBPF에 대해 많은 사람이 들어봤을 것입니다. 아놑가면 최고의 Linux 커널 기술 중 하나로 쓰인 기술입니다. 우리는 JIT가 있는 커널 가상 머신을 가지고 있고, 이는 런타임에서 가벼운 프로그램을 실행할 수 있습니다. eBPF는 py-spy와 유사하게 Python 호출 스택을 샘플링할 수 있지만 오버헤드가 적고 다른 언어로 일반화될 수 있습니다. Prodfiler는 eBPF 기반 에이전트들의 추적을 집계하는 SaaS입니다. 에이전트는 노드에 대한 전체 액세스 권한을 가진 그림자 Kubernetes pod입니다.
Prodfiler의 다음 flamegraph는 _disambiguate_pull_requests()가 하루 동안 우리의 프로덕션에서 어떻게 실행되었는지 보여줍니다. 집계 기간이 길수록 Profiler가 수집하는 샘플이 많아지고 정밀도가 높아집니다.
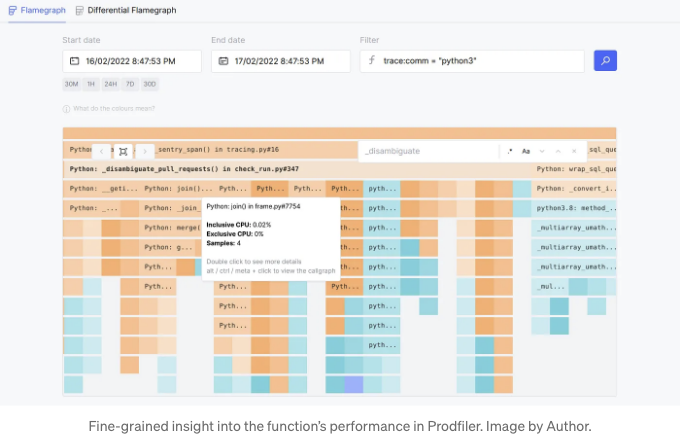
다음은 몇 가지 주의할 점이 있습니다:
- 표준 OS 패키지와 비교하여 CPython을 몇 가지 추가 최적화로 컴파일합니다. 따라서 CI/CD에서 Prodfiler에 디버그 심볼을 제출해야 합니다.
- asyncio는 지원되지 않으므로 코루틴 스택 추적이 없습니다.
- 수동 Sentry와 유사한 계측에 비해 함수의 논리적 부분을 측정할 수 없습니다.
Prodfiler는 성능 최적화를 검증하는 데 훌륭한 도구임이 입증되었습니다. 덤으로, Py-Spy가 할 수 없는 특정 커널 함수까지 세부적으로 Flame을 분해합니다.
요약
저희는 백엔드에서 느린 CPU 성능을 식별하고 프로파일링하며 최적화를 모니터링하는 방법에 대해 설명했습니다. 사용한 도구는 다음과 같습니다:
- Sentry 분산 추적.
- py-spy.
- Prodfiler.
다음 글에서는 PostgreSQL 성능 문제에 대해 다룰 예정이니, 계속 주시하시고 저자를 팔로우해 주세요. 아, 그리고 만약 저희가 개발 중인 제품이 귀하의 엔지니어링 조직에서 필요한 것처럼 들린다면, 저희 웹사이트를 확인해보세요.