OpenAI의 영광스러운 시대가 오기 훨씬 전, 저는 야심찬 자연어 처리 프로젝트의 창립팀 일원이었습니다. 이 프로젝트는 수십억 개의 온라인 고객 리뷰를 수집하여 집에서 개발한 측면 기반 감성 분석(ABSA) 엔진을 통해 실행하고, 이를 지불하고자 하는 누구에게나 AI 요약된 통찰력을 제공하는 것이 목표였습니다.
제품의 특징은 ABSA 엔진이었습니다. 우리는 이 일이 많은 계산을 필요로 할 것이라고 (올바르게) 판단하여, 이를 다른 서비스들로부터 별도로 배치했습니다. 저희의 세계적인 시스템의 간소화된 아키텍처 다이어그램은 이와 같았습니다.
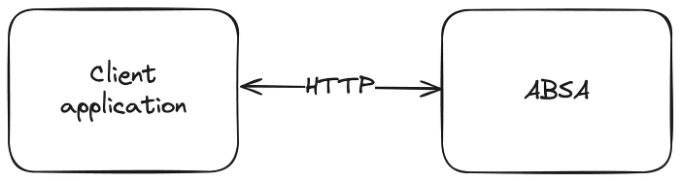
저는(잘못된) 생각으로 API 경계 사이에서 공유하는 데이터 모델을 완전히 분리하고 각 서비스에서 송신 및 수신 끝 모두에서 각 계약을 다시 작성하는 것이 좋은 아이디어일 것이라고 생각했습니다.
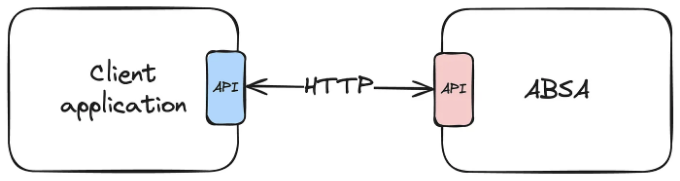
요 모델은 현대 시스템과 유사합니다. 써드파티 API가 문서를 게시하지만 라이브러리를 게시하지는 않는 경우에 해당됩니다. 그래서 API 클라이언트를 처음부터 만들어야 하는 상황입니다.
하지만 우리는 이 계약 양쪽을 모두 소유했습니다!
프로젝트가 시작된 지 세 달 후, 지연의 대부분은 두 API 중 하나에 변경 사항이 개발자들 간에 전달되지 않은 것에서 기인했습니다. 우리는 지식과 코드를 중복 생성했기 때문에 이 서비스들 사이에 불일치가 있을 경우 모든 것을 멈추게 되었습니다.
이제 다시 움직이려면 데이터 모델을 한 API에서 복사하여 다른 API로 붙여 넣는 Ctrl + C 복사가 필요했습니다. (결국에는 이게 당연한 일이라는 걸 깨닫게 됐습니다. 나중에 더 자세히 설명하겠습니다.)
저는 DRY 원칙을 위반했습니다: 자신을 반복하지 마십시오. 그리고 이 문제는 저가 지혜롭게 되어서 리팩토링하기 전까지 코드베이스에서 지속적인 문제였습니다.
DRY는 진정 무엇을 의미합니까?
DRY는 "자신을 반복하지 마십시오"의 약자입니다. Pragmatic Programmer는 이를 자세히 설명하고 있습니다:
시스템에서 복제할 수있는 "지식 조각"은 코드에만 국한되지 않습니다. 문서, 데이터, 공급업체 API, 도메인 엔티티, 워크플로우 등이 될 수도 있습니다. DRY와 WET의 차이는 시스템 내의 기본 지식과 의도로 귀결됩니다.
진정한 중복 vs. 우연한 중복
더 깊이 들어가기 전에 한 가지 유의해야 할 점은 과도한 엔지니어링 없이 진정한 중복을 제거할 때 조심해야 한다는 점입니다. 실제로 문제가 아닌 문제를 해결하면 더 나쁜 시스템이 만들어집니다.
우린 우연한 중복에 너무 신경 쓰지 않으면서 모든 진정한 지식 중복을 피하고 싶습니다. Marius Bongarts가이 주제에 대해 훌륭한 글을 썼고, 진정한 지식 중복인지 파악하기 위해 누구나 물어봐야 할 두 가지 질문을 공유했습니다:
이미지 태그를 Markdown 형식으로 바꿔줍시다.
- 동일한 코드(또는 문서, 데이터 등)가 있는지 확인할 수 있나요?
- 한 코드 블록(또는 독스트링, 레코드 등)을 변경하면 다른 코드도 변경되나요?
코드 중복 (복사-붙여넣기)
코드 내 중복은 엔지니어들이 DRY를 어기는 가장 잘 알려진 방법 중 하나입니다, 아마도 확인하기 쉽고 명시하기 쉬우니까일 것입니다. 또한 다른 중복들보다 덜 위험하며, 해결하는 것도 쉽습니다.
다음은 DRY를 준수하지 않는 함수입니다.
func PrintBalance(acct Account) {
fmt.Printf("Debits: %d\n", acct.Debits)
fmt.Printf("Credits: %d\n", acct.Credits)
if acct.Fees < 0 {
fmt.Printf("Fees: (%d)\n", -acct.Fees)
} else {
fmt.Printf("Fees: %d\n", acct.Fees)
}
if acct.Balance < 0 {
fmt.Printf("Balance: (%d)\n", -acct.Balance)
} else {
fmt.Printf("Balance: %d\n", acct.Balance)
}
}
우리는 이 PrintBalance 함수를 살펴보며 중복을 줄이고 코드를 더 DRY하게 만들 수 있는 몇 군데가 있다.
첫째로, 음수 값을 처리하는 두 가지 브랜치가 동일하다. 이것은 우리의 DRY 확인에 어떻게 적용될까요?
- ⚠️ 코드가 동일해 보입니다. acct.Fees 및 acct.Balance를 처리하는 브랜치가 완전히 같아 보입니다.
- ⚠️ 코드가 함께 변경됩니다. 두 브랜치는 논리적으로 동일한 확인을 수행하며, 하나를 업데이트하는 것은 아마도 두 가지를 모두 업데이트해야 할 수도 있습니다.
지식 중복 사례를 발견했습니다! 해당 논리를 전용 함수로 추출할 수 있습니다.
func formatAmount(amt int) string {
if amt < 0 {
return fmt.Sprintf("(%d)", amt)
}
return fmt.Sprintf("%d", amt)
}
func PrintBalance(acct Account) {
fmt.Printf("Debits: %s\n", formatAmount(acct.Debits))
fmt.Printf("Credits: %s\n", formatAmount(acct.Credits))
fmt.Printf("Fees: %s\n", formatAmount(acct.Fees))
fmt.Printf("Balance: %s\n", formatAmount(acct.Balance))
}
이미 이렇게 많이 개선되었습니다. 만약 행이 출력되는 방식을 변경하고 싶다면, 각 금액 앞에 $를 추가한다면 어떨까요? 여전히 4줄의 코드를 업데이트해야 할 것입니다. 그것을 개선해보겠습니다.
func formatAmount(amt int) string {
if amt < 0 {
return fmt.Sprintf("(%d)", amt)
}
return fmt.Sprintf("%d", amt)
}
func printReportLine(name string, amt int) {
fmt.Printf("%s: $%s\n", name, formatAmount(amt))
}
func PrintBalance(acct Account) {
printReportLine("Debits", acct.Debits)
printReportLine("Credits", acct.Credits)
printReportLine("Fees", acct.Fees)
printReportLine("Balance", acct.Balance)
}
이제 숫자가 표시되는 방식을 바꾸려면 formatAmount를 변경합니다. 줄이 인쇄되는 방식을 바꾸려면 printReportLine을 변경합니다. 이것은 매우 DRY 시스템입니다!
코드 중복을 피하려고 너무 노력하면 조심해야 합니다. 그렇게 해서 오히려 다른 이유들 때문에 진화해야할 두 유사한 코드 조각을 DRY해버릴 수도 있습니다.
이 행동은 초유화(過早化)에 관련이 있지만 실제로는 "초기 일반화"에 가깝습니다. 이 효과는 주로 다양한 사용 사례를 다룰 수 있도록 성장한 베이스 클래스를 발견했을 때 객체지향 언어에서 가장 명확하게 확인할 수 있습니다.
문서 중복
모든 함수에 주석을 다는 것이 좋을까요?
모든 코드에 항상 주석을 다는 것을 지지하는 사람들은 이와 같은 내용을 작성할 것입니다:
// 사용자의 멤버십 유형을 반환합니다.
// 사용자가 멤버십이 없으면 무료 멤버십으로 간주됩니다.
// 사용자의 멤버십이 만료된 경우 무료 멤버십으로 간주됩니다.
// 사용자의 멤버십이 만료되지 않은 경우 유료 멤버십으로 간주됩니다.
func (c *Client) GetMembershipType(ctx context.Context, userID string) (MembershipType, error) {
user, err := c.GetUser(ctx, userID)
if err != nil {
return nil, err
}
if user.Membership == nil {
return MembershipTypeFree, nil
}
if user.Membership.ExpiresAt != nil && user.Membership.ExpiresAt.Before(time.Now()) {
return MembershipTypeFree, nil
}
return MembershipTypePaid, nil
}
여기서 의도가 두 번 언급되었습니다: 한 번은 주석으로, 다시 한 번은 코드로 나타났습니다. 질문을 확인하면 이것이 명백한 DRY(Don't Repeat Yourself) 위반임을 알 수 있습니다.
- ⚠️ Knowledge looks identical. The code and the comments say the same thing.
- ⚠️ Knowledge must change together. If the code is modified, the comments should also be updated to match the new logic.
What is the purpose of this comment in the code? While it may serve to supplement inadequately named components in the code, it primarily duplicates the function logic.
Comments and documentation, especially within code, should enhance the understanding by providing reasoning behind the code ("why"). The code itself describes the functionality ("what").
Here's an enhancement for the documentation. (Alternatively, consider removing the comment entirely.)
// 사용자는 활성 멤버십을 가지고 있을 때에만 유료 회원이어야 합니다.
// 이는 유료 기능에 대한 무료 액세스를 방지합니다.
func (c *Client) GetMembershipType(ctx context.Context, userID string) (MembershipType, error) {
user, err := c.GetUser(ctx, userID)
if err != nil {
return nil, err
}
if user.Membership == nil {
return MembershipTypeFree, nil
}
if user.Membership.ExpiresAt != nil && user.Membership.ExpiresAt.Before(time.Now()) {
return MembershipTypeFree, nil
}
return MembershipTypePaid, nil
}
- ✅ 지식이 동일하지 않습니다. 주석은 코드 자체에 포함되지 않은 지식과 맥락을 추가합니다.
- ✅ 지식은 함께 변경되지 않습니다. 코드가 업데이트되어도 주석은 (아마도) 동일하게 유지됩니다.
이것이 DRY입니다!
데이터에서 DRY 위반
여기 한 예제가 있어요. Python으로 구현된 Rectangle 클래스입니다. (Python은 이런 종류의 중복을 해결하는 데 정말 좋아요.)
from dataclasses import dataclass
@dataclass
class Rectangle:
length: int
width: int
area: float
이 코드를 처음 보면, Rectangle은 보통의 클래스 같아 보이죠. 직사각형은 길이, 너비, 면적을 갖고 있습니다 (물론 이 중 일부는 0일 수도 있어요).
하지만 중복이 있습니다.
직사각형을 설명할 때는 길이와 너비가 필요하지만, 면적은 길이와 너비의 값에 따라 달라집니다. 이를 계산된 필드로 만들어 개선할 수 있습니다.
from dataclasses import dataclass
@dataclass
class Rectangle:
length: int
width: int
@property
def area(self):
return self.length * self.width
이 규칙에는 일반적인 예외가 있습니다. 성능상의 이유로 계산된 값을 저장하고 싶을 수 있습니다. 이것도 괜찮지만, 그 값을 외부로 노출하지 마세요! 중복에 대해 외부 세계에 공개하지 마세요.
from dataclasses import dataclass
@dataclass
class Rectangle:
length: int
width: int
_area: float
@property
def area(self):
return self._area
def _expensive_area_calculation(self):
self.area = ...
사람들 사이의 중복
Medium에서는 미인증 사용자의 세션을 추적합니다. 이들을 "로그아웃된 사용자"라고 부릅니다. 각 세션은 사용자에게 고유한 사용자 ID를 가지고 있습니다. 로그아웃된 사용자의 사용자 ID는 lo_로 접두사가 붙습니다. (이 구문에 많은 논리가 묶여 있지는 않지만, 로그나 데이터베이스 레코드를 볼 때 사용자 유형을 구분하기 쉬운 방법입니다.)
저희 중 한 명의 엔지니어가 공유 세션 라이브러리에 사용자 ID가 로그인했는지 로그아웃했는지 확인하는 함수를 추가했습니다. 그러나 이에 대해 알고 있는 엔지니어는 몇 명뿐이었기 때문에 대부분의 서비스가 자체적인 if strings.HasPrefix(userID, "lo_") '...' 변형을 갖게 되었습니다. 몇 달 후, 한 명의 엔지니어가 이 중복을 발견하고 이를 수정하기 위한 PR을 열었으며, 우리가 사용해야 할 세션 라이브러리에 대한 지식을 공유했습니다.
저희 시스템에 미치는 영향은 미미했고 유지보수 부담도 크지 않았습니다. 그러나 사용자 ID의 구조를 변경해야 하는 상황이 생긴다면 어떻게 될까요?
이중 복제가 해결되기 전에는 각 서비스마다 우리가 한동안 알지 못한 버그가 있었을 가능성이 높습니다.
이중 복제가 해결된 후에는 ID를 구문 분석하는 논리를 하나의 위치에 업데이트하기만 하면 됩니다.
같은 조직의 엔지니어들 사이의 중복은 발견하기 어려울 수 있지만 장기적인 영향을 미칠 수 있습니다. 이러한 종류의 중복을 다루는 최적의 방법은 엔지니어들 간에 (적극적인) 빈번한 소통을 촉진하는 것입니다. 이 문제의 해결책은 개방적인 의사 소통 문화를 키우는 것입니다.
- 공개 채널에서 커뮤니케이션 유지하기
- 다른 엔지니어들의 PR(Pull Requests) 확인하기
- 다른 엔지니어들이 사용할 수 있는 경우 특히 당신이 만드는 변경사항을 공지하기
DRY 관련 코드 스멜은 무엇인가요?
단위 테스트: 위기의 산호
테스트는 WET 소프트웨어의 징후를 처음으로 발견할 수 있는 곳입니다. 좋은 테스트 프레임워크를 통해 보일러플레이트를 작성하는 것을 피할 수 있고, DRY 코드를 유지하면 테스트가 깨끗하고 간단하게 보일 것입니다. WET 코드는 베이스 소프트웨어에서의 분기 로직을 반영하는 테스트 로직을 미러링하는 것을 의미하며, 이는 DRY 위반의 명백한 징후 중 하나입니다.
Go에는 테이블 기반 테스트라는 멋진 기능이 있습니다. 이를 이용하면 많은 다양한 테스트 케이스를 쉽게 반복할 수 있습니다. 아래는 좋은 테이블 테스트의 예시입니다:
간단하고 깔끔하며 우아하죠. 이 코드를 테스트하는 프로그램은 아마도 DRY(반복하지 않는 원칙)를 따르고 있을 겁니다.
package auth
func TestFormatID(t *testing.T) {
type input struct {
id string
isLoggedOut bool
}
testCases := []struct {
name string
input input
expected string
expectedErr error
}{
{
name: "missing input",
input: input{id: ""},
expected: "",
expectedErr: ErrMissingID,
},
{
name: "input too short",
input: input{id: "a"},
expected: "",
expectedErr: ErrIDTooShort,
},
{
name: "input is at least 4 chars",
input: input{id: "abcd"},
expected: "abcd-001",
expectedErr: nil,
},
{
name: "logged out session",
input: input{id: "abcd", isLoggedOut: true},
expected: "lo_abcd-001",
expectedErr: nil,
},
}
for _, tc := range testCases {
t.Run(tc.name, func(t *testing.T) {
// BAD! Branching logic in unit tests ❌
if tc.isLoggedOut {
actual, err := FormatLoggedOutID(tc.input)
assert.Equal(t, tc.expected, actual)
require.ErrorIs(t, err, tc.expectedErr)
} else {
actual, err := FormatLoggedInID(tc.input)
assert.Equal(t, tc.expected, actual)
require.ErrorIs(t, err, tc.expectedErr)
}
})
}
}
이 테스트에서의 분기 논리는 함수에 대한 모든 가능한 경우를 처리합니다. 테스트 케이스끼리 관련이 있고 검사하는 지식도 관련이 있습니다. 그러나 분기된 테스트 경로는 해당 함수에서 DRY 위반이 있을 수 있다는 코드 냄새를 보여줍니다.
여러 곳에 변경 사항을 복사해야 함
하나의 객체 구조를 동일하게 변경하지 않고 다른 관련 없는 구조를 변경할 수 없다면, DRY 위반(또는 단일 책임 원칙 위반)이 발생할 수 있습니다.
API 계약 실패 사례로 돌아가서, 한 API를 업데이트할 때마다 해당 변경 사항을 다른 API에도 복사-붙여넣기해야 했습니다. 이제는 "자기 반복하지 말라"는 원칙을 위반했다는 것이 명확해졌습니다.
"이것에 대한 함수를 아직 누군가 작성하지 않은 게 놀라울 따름"
만약 코드를 작성하면서 이런 말을 스스로에게 하는 거라면, 한 발 물러나서세요. 코드베이스에 더 많은 지식을 가진 사람에게 당신이 빠뜨린 공유 라이브러리가 있는지 물어보세요. 그렇지 않으면 직접 작성해서 지식을 공유해주세요. 그렇게 함으로써 미래의 프로젝트가 더 DRY해지도록 돕는 것이 중요합니다.
(이렇게 해서 저는 세션 라이브러리에서 로그아웃된 사용자 ID를 확인하는 공유 함수를 발견했습니다.)
이와 같은 훌륭한 엔지니어링 논문들은 The Atomic Engineer에서 확인할 수 있습니다.
질문이나 피드백이 있으시면 댓글을 남겨주세요.