10 개의 파이썬 자동 탐색적 데이터 분석 도구
탐색적 데이터 분석 (EDA)는 데이터 과학 모델 개발 및 데이터셋 연구에 중요합니다.
새로운 데이터셋을 만나면 EDA에 상당한 시간을 투자하여 내재된 정보를 발견합니다.
자동 EDA 파이썬 패키지는 몇 줄의 코드로 EDA를 실행할 수 있습니다.
1. D-Tale
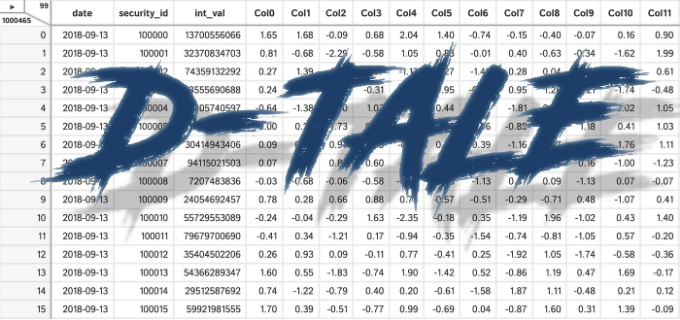
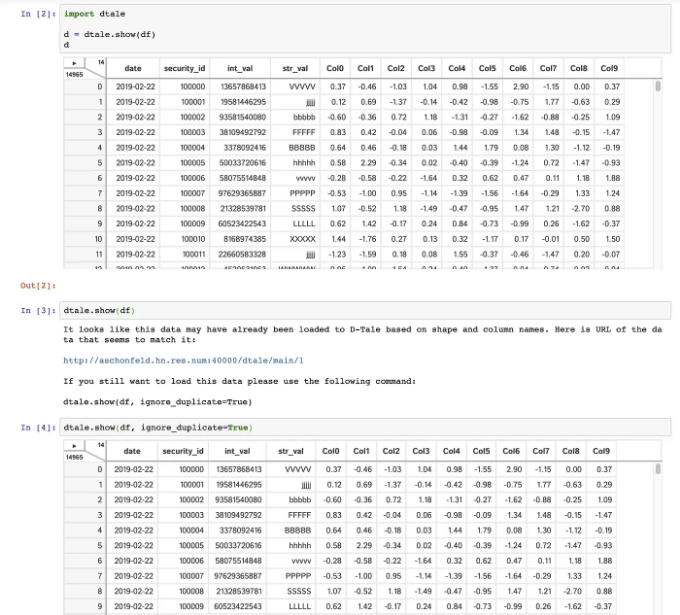
D-Tale은 백엔드로 Flask, 프론트엔드로 React를 사용하며, IPython 노트북 및 터미널과 원활하게 통합됩니다.
D-Tale은 Pandas DataFrame, Series, MultiIndex, DatetimeIndex 및 RangeIndex를 지원합니다.
import dtale
import pandas as pd
dtale.show(pd.read_csv("titanic.csv"))
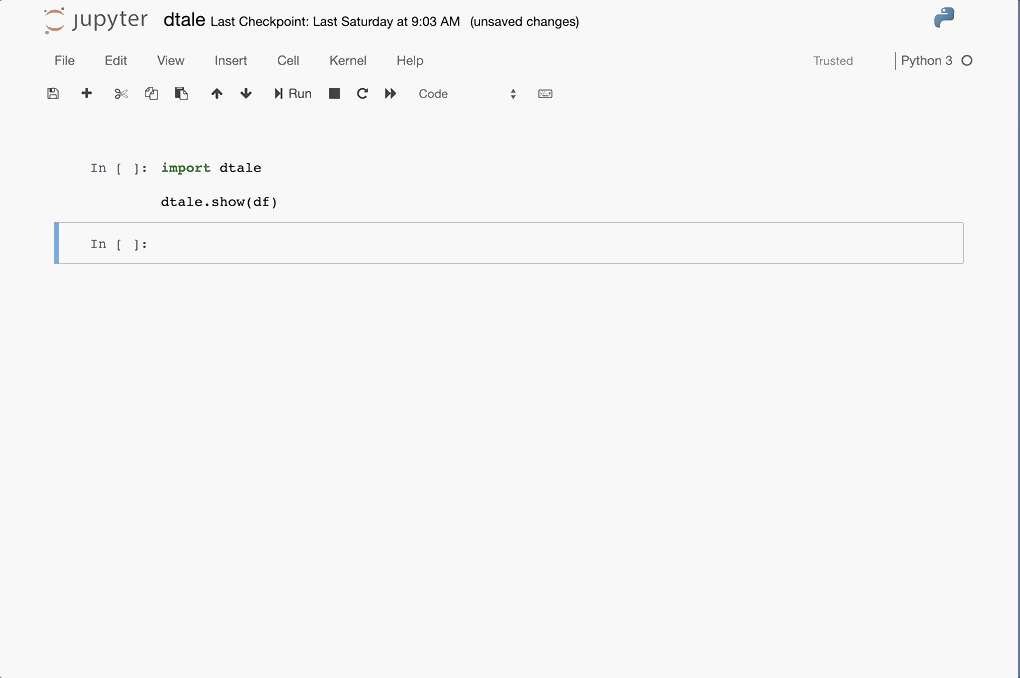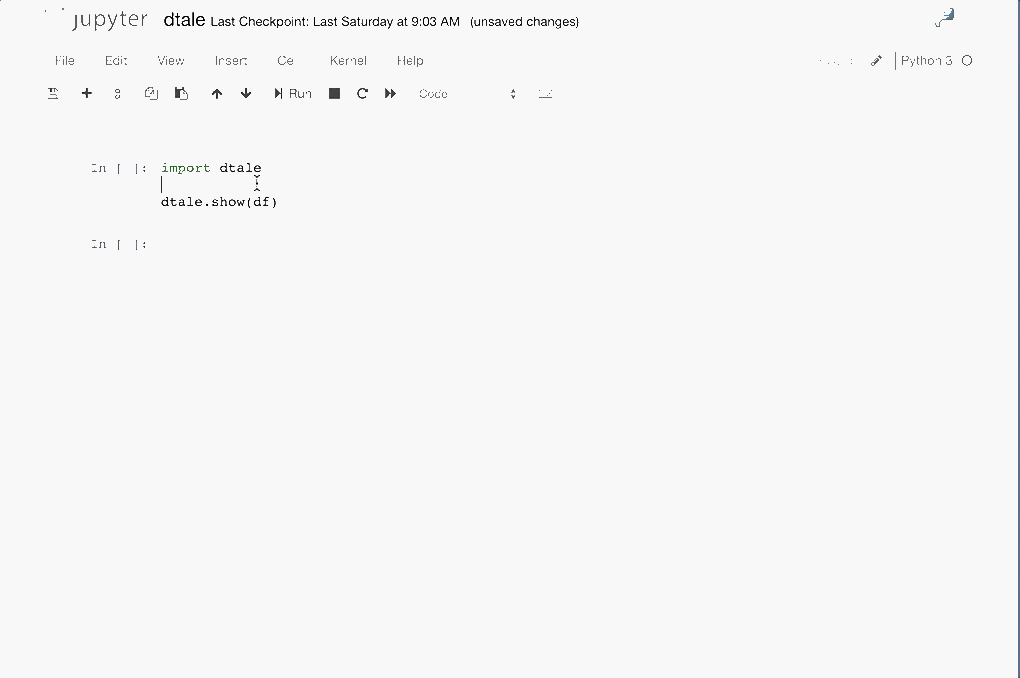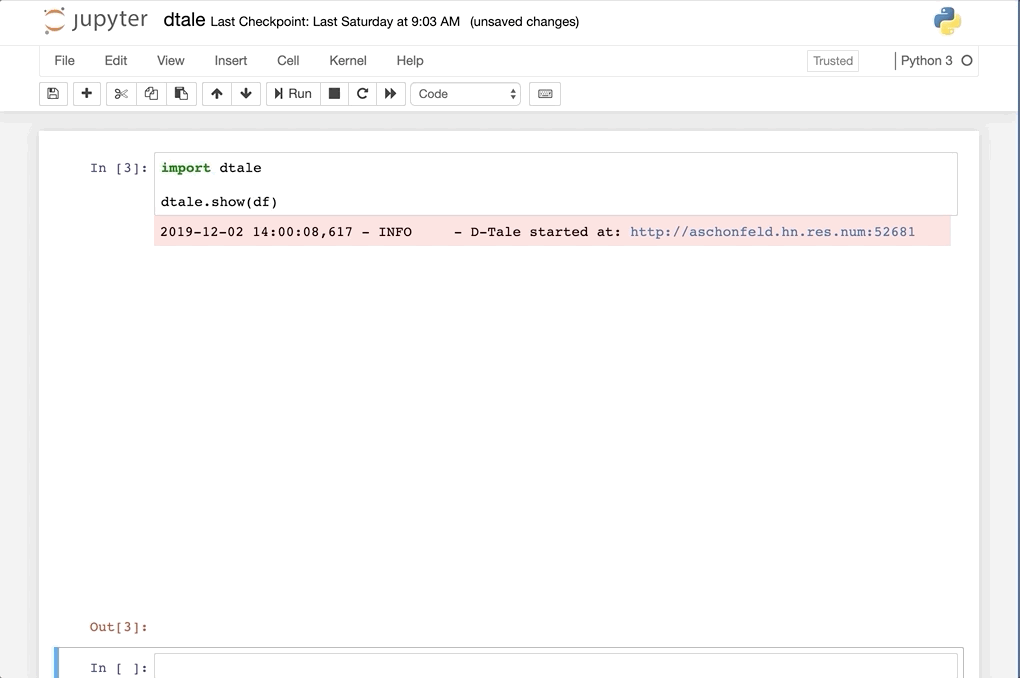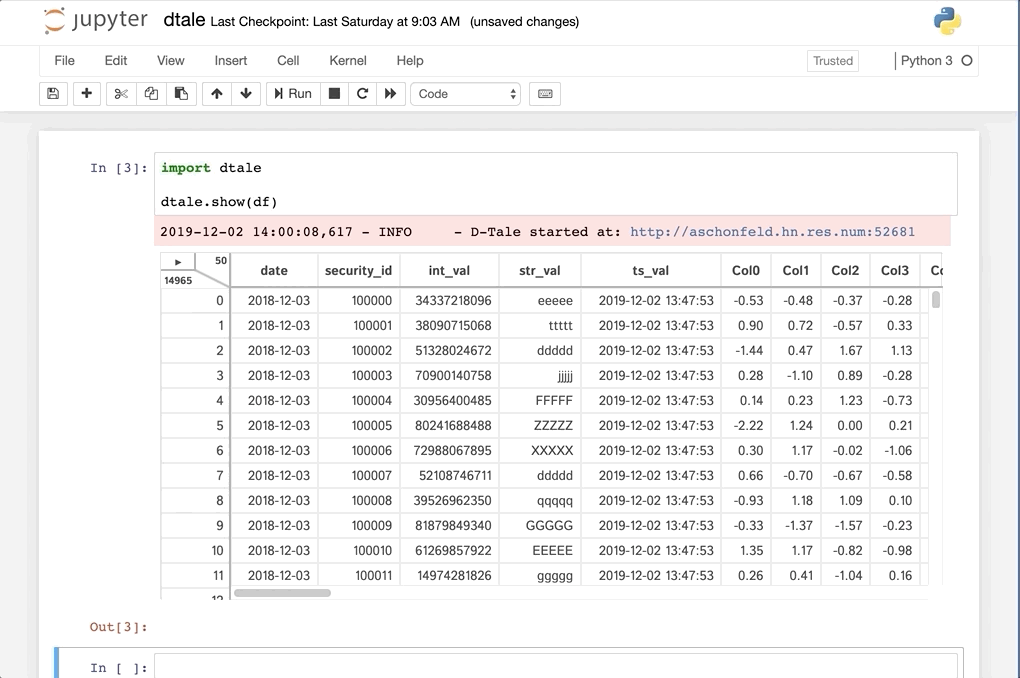
한 줄의 코드로 D-Tale은 데이터셋의 요약, 상관 관계, 차트 및 히트맵, 결측값 강조를 보여주는 보고서를 생성합니다. 또한 보고서의 각 차트에 대한 인터랙티브 분석을 제공합니다.
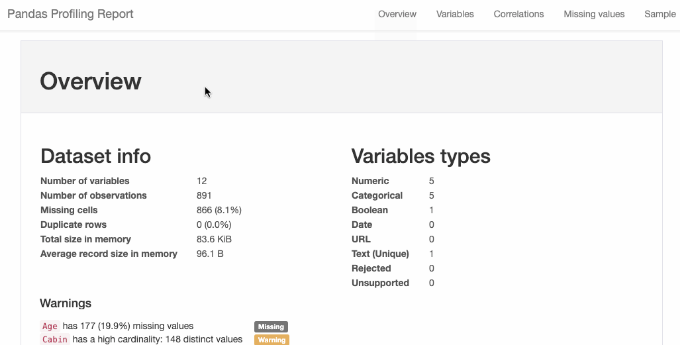
2. ydata-profiling
ydata-profiling은 Pandas DataFrame에 대한 요약 보고서를 생성합니다.
이는 대용량 데이터셋에서 효율적으로 작동하여 몇 초 안에 보고서를 생성하는 df.profile_report()를 Pandas DataFrame에 확장합니다.
# 가져오기 전에 아래 라이브러리를 설치하세요
import pandas as pd
from ydata_profiling import ProfileReport
# pandas-profiling을 사용한 탐색적 데이터 분석 (EDA)
profile = ProfileReport(pd.read_csv('titanic.csv'), explorative=True)
# 결과를 HTML 파일로 저장하기
profile.to_file("output.html")
3. Sweetviz

Sweetviz는 두 줄의 코드로 아름다운 시각화를 생성하는 오픈 소스 Python 라이브러리로, HTML 애플리케이션으로 EDA를 시작합니다.
이는 대상 값과 데이터셋 비교를 위해 빠르게 시각화할 수 있도록 만들어졌습니다.
import pandas as pd
import sweetviz as sv
# Autoviz를 사용한 탐색적 데이터 분석
sweet_report = sv.analyze(pd.read_csv("titanic.csv"))
# 결과를 HTML 파일로 저장
sweet_report.show_html('sweet_report.html')
Sweetviz 보고서는 데이터 세트, 상관 관계 및 범주 및 수치적 특성의 관계를 요약합니다.
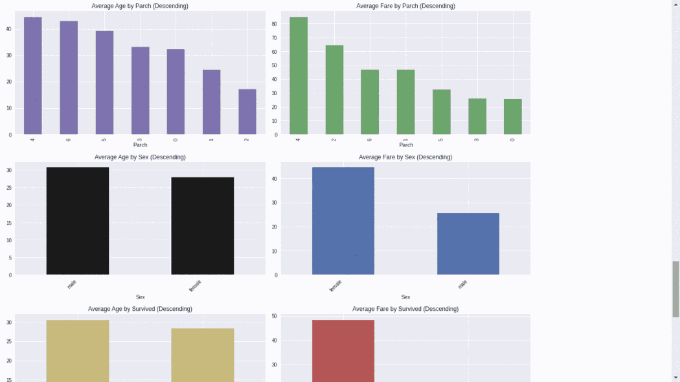
4. AutoViz
AutoViz은 단 한 줄의 코드로 어떤 크기의 데이터 세트든 자동으로 시각화해주며, HTML, Bokeh 등의 형식으로 보고서를 생성합니다.
AutoViz가 생성한 HTML 보고서와 상호 작용할 수 있습니다.
import pandas as pd
from autoviz.AutoViz_Class import AutoViz_Class
# Autoviz를 사용한 탐색적 데이터 분석
autoviz = AutoViz_Class().AutoViz('train.csv')
5. 데이터 준비
Dataprep은 데이터를 분석, 준비 및 처리하기 위한 오픈 소스 파이썬 패키지입니다.
Pandas와 Dask DataFrame 위에 구축된 Dataprep은 다른 파이썬 라이브러리와 쉽게 통합됩니다.
Dataprep은 이러한 패키지 중 가장 빠르며, Pandas/Dask DataFrame에 대한 보고서를 몇 초 안에 생성합니다.
from dataprep.datasets import load_dataset
from dataprep.eda import create_report
df = load_dataset("titanic.csv")
create_report(df).show_browser()
6. Klib
Klib은 데이터 가져오기, 정리, 분석 및 전처리를 위한 Python 라이브러리입니다.
import klib
import pandas as pd
df = pd.read_csv('DATASET.csv')
klib.missingval_plot(df)
Klib은 많은 분석 기능을 제공하지만 각각은 수동 코딩이 필요하여 준자동화 되어 있습니다. 그러나 사용자 정의 분석을 위해 매우 편리합니다.
klib.missingval_plot(df) # DataFrame에서 누락된 값의 기본 표현, 다양한 설정이 가능합니다
![]()
klib.corr_plot(df, split='pos') # 양의 상관 관계만 표시, 다른 설정으로는 임계값, cmap 등이 있습니다...
klib.corr_plot(df, split='neg') # 음의 상관 관계만 표시
klib.corr_plot(df, target='wine') # 피처 열과의 상관 관계의 기본적인 표현
7. Dabl
Dabl은 개별 열 통계보다는 시각화 및 편리한 기계 학습 전처리와 모델 검색을 통해 빠른 개요를 제공하는 데 초점을 맞춥니다.
Dabl의 plot() 함수는 다음과 같은 다양한 그래프를 시각화합니다:
- 대상 분포 그래프
- 산점도
- 선형 판별 분석
import pandas as pd
import dabl
df = pd.read_csv("titanic.csv")
dabl.plot(df, target_col="Survived")
8. SpeedML
SpeedML은 머신 러닝 파이프라인을 빠르게 시작할 수 있는 파이썬 패키지입니다.
일반적인 ML 패키지인 Pandas, Numpy, Sklearn, Xgboost 및 Matplotlib을 통합하여 자동 EDA 이상의 기능을 제공합니다.
SpeedML의 개발자들에 따르면, SpeedML은 반복적 개발을 통해 코딩 시간을 70%로 줄일 수 있습니다.
from speedml import Speedml
sml = Speedml('../input/train.csv', '../input/test.csv',
target = 'Survived', uid = 'PassengerId')
sml.train.head()
![]()
9. DataTile
DataTile(이전 Pandas-Summary)은 데이터를 관리, 요약, 시각화하는 오픈 소스 Python 패키지입니다.
이는 Pandas DataFrame describe() 함수를 확장합니다.
import pandas as pd
from datatile.summary.df import DataFrameSummary
df = pd.read_csv('titanic.csv')
dfs = DataFrameSummary(df)
dfs.summary()
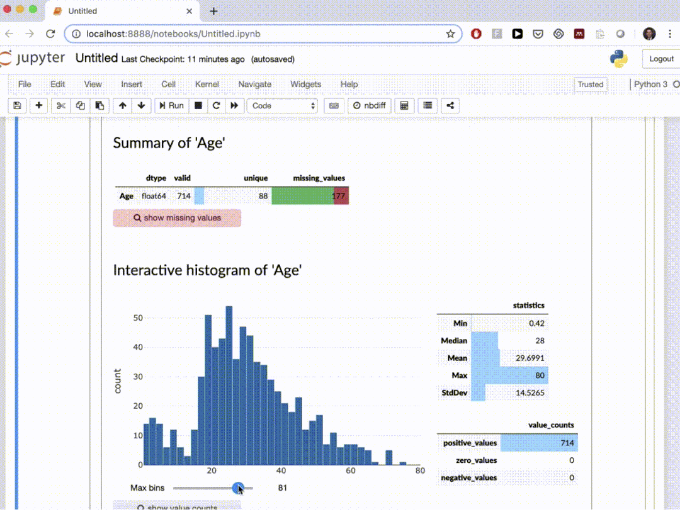
10. edaviz
Edaviz은 주피터 노트북 및 주피터 랩에서 데이터 탐색과 시각화를 위한 Python 라이브러리입니다. 이것은 매우 유용했지만 Databricks가 인수한 후 Bamboolib로 통합되었습니다.
결론
이 글에서는 몇 줄의 코드로 데이터 요약과 시각화를 생성하는 10가지 자동 EDA Python 패키지를 소개했습니다. 이 도구들은 자동화를 통해 상당한 시간을 절약해줍니다.
Dataprep는 제가 가장 자주 사용하는 EDA 패키지이며, AutoViz와 D-Tale도 훌륭한 선택지입니다. Klib는 사용자 정의 분석에 편리하며, SpeedML의 포괄적인 통합은 EDA에 단독으로는 적합하지 않습니다. 다른 패키지들은 개인 취향에 따라 선택할 수 있으며, edaviz는 더 이상 오픈 소스가 아닙니다.
최신 AI 이야기를 놓치지 않으려면 Substack에서 저희와 연락을 유지해주세요. 함께 AI의 미래를 함께 만들어가요!
Substack에서 우리와 연락을 유지하여 파이썬 이야기를 최신 상태로 유지하세요. 함께 파이썬을 배워봐요!