
데이터 시각화 라이브러리인 Matplotlib, Seaborn 및 Plotly와 같은 라이브러리를 사용하는 것은 매우 일반적입니다. 그러나 일일 단순 EDA 분석을 진행하면서 이러한 라이브러리를 사용할 필요가 없을 수도 있음을 발견했습니다. 사실, 판다스 라이브러리 자체로도 이러한 작업을 수행하기 충분할 수 있습니다.
이 기사에서는 Matplotlib 없이 일반적인 종류의 차트를 생성하는 방법을 소개하겠습니다. 사실, 판다스 플롯은 내부적으로 Matplotlib 객체를 활용합니다. 그러나 한 줄의 코드로 데이터프레임에서 아주 쉽게 플롯할 수 있다는 편의성이 있습니다.
물론 판다스 플롯을 사용한다면 많은 제약사항이 있습니다. 따라서 충분히 사용할 수 있는 경우에만 사용하는 것을 권장합니다. 마지막 섹션에서는 판다스 플롯으로는 도움을 줄 수 없는 몇 가지 시나리오도 알려드리겠습니다. 이 기사가 도움이 되기를 바랍니다.
1. 샘플 데이터셋

일반적으로, 제가 작성하는 글은 라이브러리 설치부터 시작합니다. 그러나 Pandas의 경우 너무 많이 사용되어 생략해도 됩니다. 게다가 대부분의 환경에서는 이미 Google Colab이나 Databricks와 같이 Pandas 라이브러리가 환경에 설치되어 있습니다.
이 튜토리얼 전반에서 사용할 수 있는 데모용 샘플 데이터셋을 만들어보겠습니다.
더 쉽게 하기 위해 Numpy를 사용하여 랜덤 숫자를 생성할 수 있어요. 실제 데이터 시각화 사용 사례에서는 Numpy조차 필요하지 않다는 것을 유의해 주세요.
import pandas as pd
import numpy as np
# 정확히 같은 결과를 재현하고 싶다면
np.random.seed(123)
# 샘플 데이터 생성
data = {
'날짜': pd.date_range(start='1/1/2024', periods=100),
'제품_A_판매량': np.random.randint(50, 200, 100),
'제품_B_판매량': np.random.randint(30, 150, 100),
'온도': np.round(np.random.normal(25, 5, 100), 2),
'도시': np.random.choice(['시드니', '멜버른', '애들레이드', '브리즈번', '퍼스'], 100),
'수익': np.random.randint(500, 1000, 100),
'이윤': np.random.randint(50, 200, 100)
}
df = pd.DataFrame(data)
# 샘플 데이터 표시
df.head()
seed(123)은 선택 사항이에요. 하지만 이 기사에서 제 모든 예시를 시도하고 같은 결과를 기대한다면 동일한 시드 번호를 사용해 주세요. 그러면 생성할 랜덤 숫자가 동일해질 거예요.
저희 데이터셋은 날짜별 제품 판매 통계 및 온도와 같은 다른 기능을 포함한 시뮬레이션된 와이드 테이블입니다.
2. Pandas로 플로팅하고, 팁들

데이터 시각화 튜토리얼은 대부분 라인 차트로 시작하는데, 이것이 가장 기본적인 타입이기 때문입니다. Pandas만 사용하여 라인 차트를 만드는 방법을 살펴봅시다.
우리가 Product A의 매출 트렌드를 시간에 따라 그래픽으로 표시하려면 다음과 같이 간단합니다.
df.plot(kind='line', x='Date', y='Product_A_Sales', title='Product A Sales Over Time');
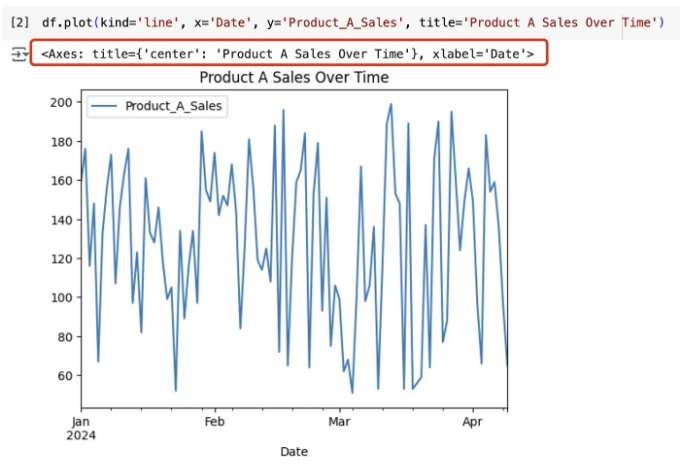
데이터프레임에서 plot() 메서드를 호출할 때, 우리는 line 차트를 kind='line'로 설정하고, x-축과 y-축을 지정하기만 하면 됩니다. 설명할 것이 많지 않습니다. 정말 쉽죠.
그런데 Axes:...라는 난창한 출력을 발견했나요? 이는 Pandas가 차트를 생성할 때 Matplotlib를 내부적으로 사용하기 때문입니다. Matplotlib를 직접 가져와 호출하지 않아도, 메소드 df.plot()은 여전히 Axes 객체를 생성합니다. 즉, Jupyter Notebook이나 iPython과 같은 환경에서 Matplotlib의 plt.show()를 호출하지 않으면 난창한 출력이 계속됩니다.
이게 사실인가요? 정확히는 :)
Jupyter Notebook 환경에서는 셀에서 객체의 출력을 억제하는 세미콜론 ;을 사용할 수 있습니다. 예를 들어, 아래와 같이 객체 값을 직접 출력할 수 있는 방법을 이미 알고 있을 것입니다.

그러나 세미콜론을 추가하면 객체가 출력되지 않습니다.

마찬가지로, Pandas 플롯의 지저분한 출력을 제거하는 데도이 트릭을 사용할 수 있습니다.
3. 판다스 플롯에서 무엇을 사용할 수 있나요?
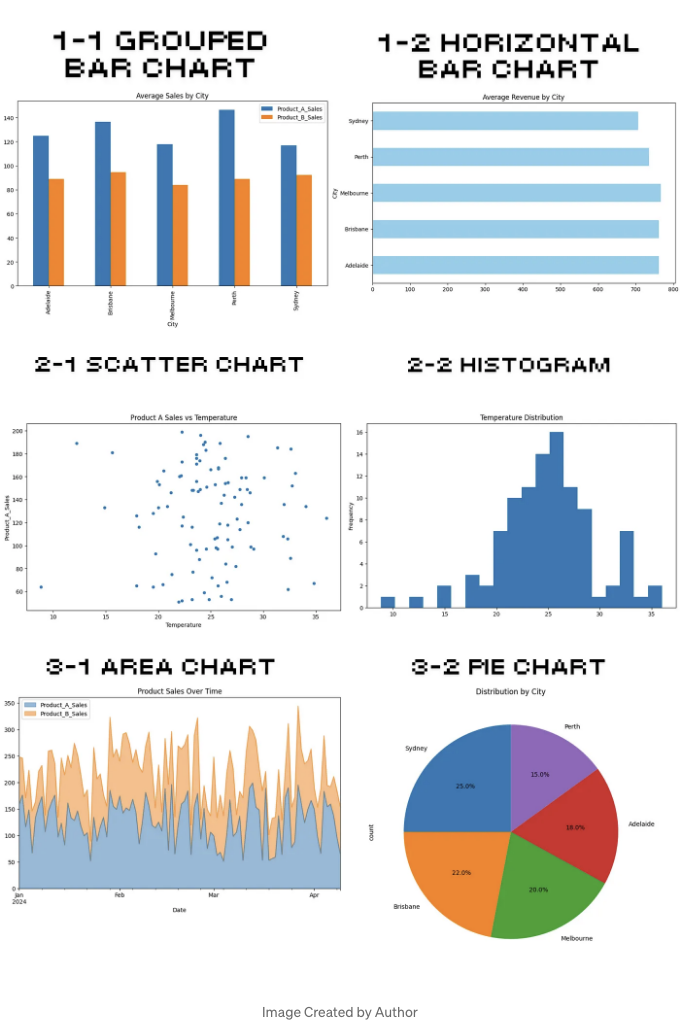
위에 표시된 선 그래프 외에도, 판다스 플롯은 대부분의 일반적인 차트 유형을 지원합니다. 아래에 코드와 샘플 차트를 제시하겠습니다.
# 1-1 그룹화된 막대 차트
df.groupby('City')[['Product_A_Sales', 'Product_B_Sales']].mean().plot(kind='bar', title='도시별 평균 매출', figsize=(10, 6));
# 1-2 수평 막대 차트
df.groupby('City')['Revenue'].mean().plot(kind='barh', title='도시별 평균 수익', figsize=(10, 6), color='skyblue');
# 2-1 산점도
df.plot(kind='scatter', x='Temperature', y='Product_A_Sales', title='제품 A 매출 vs 온도', figsize=(10, 6));
# 2-2 히스토그램
df['Temperature'].plot(kind='hist', bins=20, title='온도 분포', figsize=(10, 6));
# 3-1 쌓인 영역 차트
df[['Product_A_Sales', 'Product_B_Sales']].plot(kind='area', title='시간에 따른 제품 매출', figsize=(10, 6), alpha=0.5);
# 3-2 파이 차트
df['City'].value_counts().plot(kind='pie', title='도시별 분포', figsize=(8, 8), autopct='%1.1f%%', startangle=90);
판다스 플롯에서 Matplotlib의 몇 가지 인수를 사용했다는 것을 알 수 있을 겁니다. 다시 말하지만, 판다스 플롯은 Matplotlib를 내부적으로 사용하므로 이러한 차트 유형과 구성은 모두 Matplotlib와 정확히 동일합니다.
예를 들어, figsize()를 사용하면 그림의 크기를 정의할 수 있고, color 인수를 사용하면 색상 코드를 사용자 정의할 수 있으며, autopct를 사용하면 파이 차트에서 백분율의 소수점을 표준화할 수 있습니다.
모든 것은 Matplotlib 문서에서 확인할 수 있으므로 이 글에서는 반복하지 않겠습니다.
4. 데이터 시각화를 위한 판다스의 한계
일반적인 EDA 활동 중에는 대부분의 시나리오에 대해 판다스 플롯 함수만으로 충분하다고 생각합니다. 그러나 그 한계에 도달하는 경우도 있습니다. 아래의 경우에는 Matplotlib 또는 다른 시각화 라이브러리를 사용해야 할 수도 있습니다.
고급 스타일링 및 서식 지정이 필요한 경우
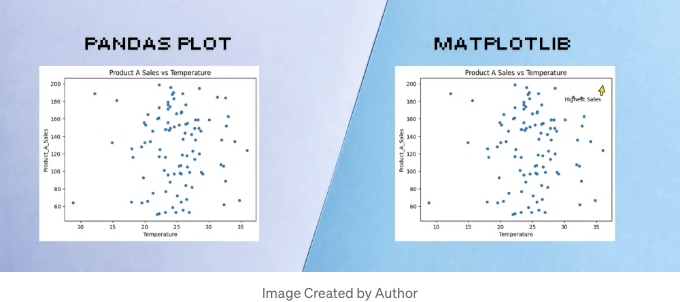
더욱 고급스러운 스타일링과 포맷팅이 필요할 때는 Pandas plot이 만족스럽지 못할 수도 있습니다. 예를 들어 산점도 차트에서 최대 판매액을 강조하는 등 차트에 어노테이션을 추가하고 싶은 경우를 가정해보죠.
# Pandas Plot Scatter
df.plot(kind='scatter', x='Temperature', y='Product_A_Sales', title='Product A Sales vs Temperature');
# Annotation으로 Matplotlib 사용
import matplotlib.pyplot as plt
ax = df.plot(kind='scatter', x='Temperature', y='Product_A_Sales', title='Product A Sales vs Temperature')
ax.annotate('최고 매출', xy=(df['Temperature'].max(), df['Product_A_Sales'].max()), xytext=(30, 180),
arrowprops=dict(facecolor='gold', shrink=0.05))
plt.show()
특별한 차트 유형
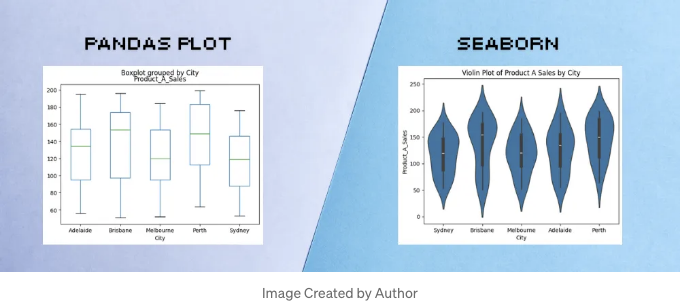
특별한 종류의 차트가 필요할 때, Pandas plot은 모든 흔한 종류의 차트를 제공하지는 못할 수 있어요. 예를 들어, Pandas plot은 판매 분포를 보여주는 상자 차트를 생성할 수 있지만, 분포를 더 잘 보여주는 바이올린 차트도 있어요. 후자는 Seaborn 라이브러리에서 바로 사용할 수 있어요.
# Pandas Plot 상자 차트
df.boxplot(column='Product_A_Sales', by='City', grid=False);
# Seaborn 바이올린 차트
import seaborn as sns
import matplotlib.pyplot as plt
sns.violinplot(x='City', y='Product_A_Sales', data=df)
plt.title('도시별 제품 A 매출의 바이올린 차트')
plt.show()
상호 작용성
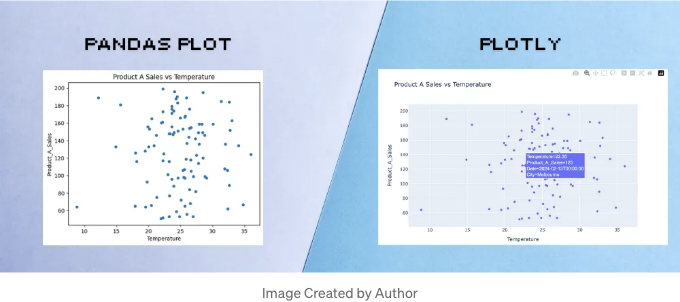
판다 플롯은 정적입니다. 이는 시각화를 좀 더 상호 작용적으로 만들고 싶을 때 마우스 호버 팁이나 팬 제스처와 같은 대안을 찾아야 한다는 것을 의미합니다. Plotly는 상호 작용형 데이터 시각화를 생성하는 데 가장 좋아하는 라이브러리 중 하나입니다.
import plotly.express as px
fig = px.scatter(df, x='Temperature', y='Product_A_Sales', title='Product A Sales vs Temperature', hover_data=['Date', 'City'])
fig.show()
결론

요약하면, Pandas가 우리의 데이터를 아주 쉽게 그래프로 나타낼 수 있다는 것을 알아두는 것이 좋습니다. 따라서 대부분의 경우 Matplotlib을 포함한 다른 라이브러리를 사용할 필요가 없을 수도 있습니다. 이는 루틴 EDA 작업을 훨씬 쉽게 만들어 줄 것입니다. 한 줄의 코드만으로도 충분할 수 있기 때문이죠. 물론, Pandas Plot로 해결할 수 없는 많은 것들도 있으며, 해당 내용은 이 글에서 자세히 다루고 있습니다. 이 글이 도움이 되길 바랍니다.
즐거운 코딩 되세요!