
소개
동기
F1 트렌드 트윗 데이터셋을 작업하면서, 워드 클라우드 최적화에 대해 조금 더 심층적으로 알아볼 수 있는 기회를 발견했습니다. 명확하고 유익한 워드 클라우드를 만들기 위해서는 조심스럽게 조정하고 사용자화하는 것이 필요했습니다. 이 과정을 통해 얻은 인사이트를 공유하고, 다른 이들이 자신의 워드 클라우드 시각화를 향상시킬 수 있는 데 도움이 되기를 바랍니다.
이 게시물의 목표는 더 효과적인 워드 클라우드를 만드는 실용적인 팁과 기술을 제공하는 것입니다. 반복되는 단어, 색상 선택, 모양 사용자 정의와 같은 일반적인 문제에 대해 다루면서 데이터 분석 워크플로우를 실제로 향상시킬 수 있는 워드 클라우드 시각화를 만드는 데 도움을 주려고 노력합니다. 이제 다채로운 워드 클라우드로 더 이상 고생할 필요가 없습니다. 데이터 분석 과정에서 중요한 단계에 노력을 집중할 수 있습니다.
데이터 개요
이 프로젝트는 F1(Formula 1)과 관련된 트렌드 트윗 데이터셋을 기반으로 합니다. 이 데이터셋에는 다음과 같은 주요 정보가 포함되어 있습니다:
- 텍스트: 트윗의 내용
- 사용자 정보: 사용자 위치, 팔로워 수, 인증된 상태 등의 세부 정보
- 해시태그: #F1 해시태그와 관련 트렌드 키워드를 포함하는 트윗
- 날짜: 2022년 3월부터 2022년 7월까지 작성된 트윗으로, 2022년 레이싱 시즌의 첫 번째 반기를 다룹니다.
저는 이 트윗 데이터를 기반으로 워드 클라우드를 생성했습니다. 텍스트 정제, 불용어 처리, 그리고 사용자 정의 컬러맵을 활용했습니다. 이렇게 함으로써 시각화를 더욱 강조할 수 있었죠.
매핑 후 사용자 위치 분포
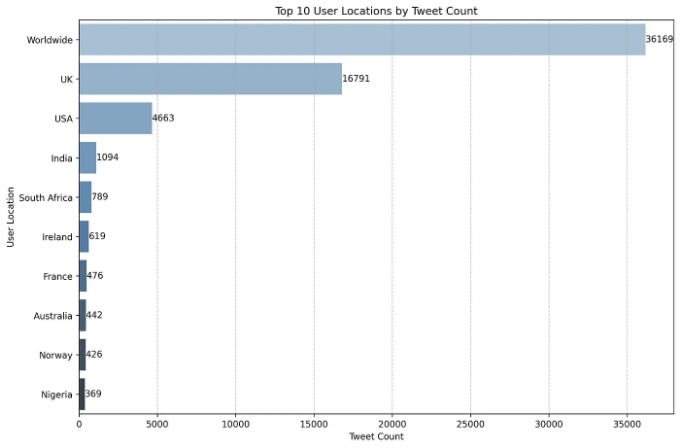
탐색적 데이터 분석(EDA) 단계에서 사용자 위치의 분포를 막대 차트로 시각화했습니다. F1이 강한 영국적 역사를 갖고 있기 때문에, "Worldwide"를 제외한 가장 많은 트윗이 영국에서 온 것은 예상한 대로입니다.
영국 트윗의 높은 양은 영국 GP, 영국 팀 및 영국 운전자에 대한 F1 콘텐츠에 대한 강한 관심을 보여줍니다. 이 지역의 강한 관심과 영향력을 F1 커뮤니티 내에서 강조합니다.
사용자 위치 데이터의 분석은 이 포스트의 나중에 제공될 워드 클라우드 인사이트를 이해하는 데 중요한 맥락을 제공합니다. F1 대화에서 영국의 중요성은 텍스트 분석에서 우리가 관측할 수 있는 일부 패턴을 설명하는 데 도움이 됩니다.
워드 클라우드 생성 과정

나의 F1 트윗 워드 클라우드 분석 세부 사항에 대해 파헤치기 전에, 워드 클라우드가 무엇이고 어떤 목적을 가지고 있는지 간단히 살펴보겠습니다.
워드 클라우드는 텍스트 데이터의 시각적 표현입니다. 단어의 크기와 중요도는 그 빈도를 반영합니다. 위의 예시는 한국어 워드 클라우드를 보여줍니다. 저는 이전 프로젝트에서 R의 'wordcloud' 라이브러리를 사용하여 만들었습니다.
워드 클라우드는 주제 요약 및 텍스트 데이터의 시각적 매력을 강화해주는 데 유용한 도구일 수 있습니다. 워드 클라우드의 가장 편리한 점 중 하나는 Python 및 R의 'wordcloud' 라이브러리와 다양한 온라인 도구를 통해 쉽게 만들 수 있다는 것입니다.
F1 트윗 분석을 위해, 나는 이러한 워드 클라우드 생성 기능을 활용하여 데이터 세트 내에서 가장 중요한 용어 및 주제에 관해 통찰을 얻었습니다. 그러나 진정으로 효과적이고 유익한 워드 클라우드를 얻기 위해서는 몇 가지 추가적인 사용자 정의 및 세부 조정이 필요하다는 것을 빨리 깨달았습니다.
다음 섹션에서는 F1 트윗 워드 클라우드의 명확성과 효과를 향상시키기 위해 취한 구체적인 단계를 공유할 것입니다. 이러한 학습은 텍스트 기반 데이터셋에 대해 더 효과적인 워드 클라우드 시각화를 만드는 데 도움이 될 수 있습니다.
다룰 주제:
- 기본 워드 클라우드 생성
- 고급 사용자 지정
- 시각화 및 미적 요소
기본 워드 클라우드 생성
'wordcloud' 라이브러리 사용하기:
설치: 필요한 라이브러리가 설치되어 있는지 확인하세요. 이미 설치되어 있지 않은 경우 pip를 사용하여 다음과 같이 설치할 수 있습니다:
pip install wordcloud matplotlib numpy pillow
라이브러리 가져오기: 워드 클라우드를 생성하고 시각화하기 위해 필요한 라이브러리를 가져옵니다:
from wordcloud import WordCloud, STOPWORDS
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from matplotlib.colors import LinearSegmentedColormap
import re
기본 매개변수: 워드 클라우드를 생성할 때 외형을 제어하는 여러 매개변수를 사용자 정의할 수 있습니다.
- 너비와 높이: 워드 클라우드의 크기를 정의합니다.
- background_color: 워드 클라우드의 배경색을 설정합니다.
- max_words: 표시되는 최대 단어 수를 제한합니다.
간단한 워드 클라우드 생성: 여기에서는 기본 설정을 사용하여 워드 클라우드를 생성하는 간단한 예제가 제공됩니다.
# 텍스트 데이터 정의
text = "여기에 샘플 텍스트 데이터를 입력하세요."
# 기본 워드 클라우드 생성
wordcloud = WordCloud(
width=800, # 워드 클라우드의 너비 설정
height=400, # 워드 클라우드의 높이 설정
background_color='white' # 배경색 설정
).generate(text)
# 워드 클라우드 표시
plt.figure(figsize=(10, 5)) # 그림 크기 조정
plt.imshow(wordcloud, interpolation='bilinear') # 부드러운 렌더링
plt.axis('off') # 축 숨김
plt.title('기본 워드 클라우드') # 제목 추가
plt.show() # 그래프 렌더링
설명:
- WordCloud 생성자: 지정된 크기와 배경색을 가진 WordCloud 객체를 생성합니다.
- generate(text): 텍스트를 처리하여 워드 클라우드를 생성합니다.
- imshow(): 워드 클라우드 이미지를 렌더링합니다.
- axis('off'): 더 깔끔한 모양을 위해 축을 숨깁니다.
- show(): 워드 클라우드를 표시합니다.

고급 사용자 정의
F1 트렌딩 트윗 데이터 집합에 더 큰 영향을 미치는 워드 클라우드를 생성하기 위해 적용한 고급 사용자 정의를 살펴봅시다.
불용어 및 필터링:
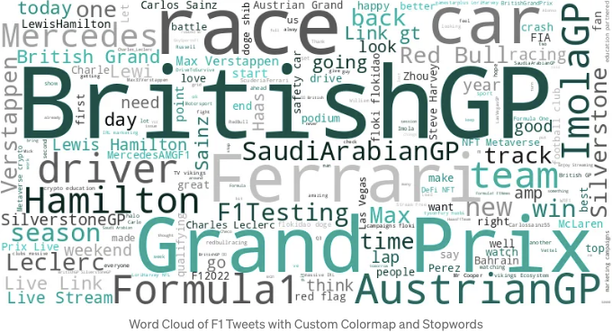
- 불용어 정의: 일반적이거나 관련성이 없는 단어를 필터링하는 데 필수적인 불용어 목록을 사용자 정의하는 것이 중요합니다. 이를 통해 가장 중요한 용어가 강조됩니다. 이 경우, 결과를 더 정제하기 위해 불용어 목록에 용어 "F1"을 포함했습니다. "F1"의 모든 변형을 re.sub를 사용하여 정규화하려는 노력에도 불구하고, 모든 트윗이 이미 F1 해시태그를 포함하고 있기 때문에 해당 용어를 완전히 제거하기로 결정했습니다. 이러한 접근 방식은 다른 주요 용어들을 더 잘 강조하는 데 도움이 됩니다.
- 텍스트 전처리: 텍스트 데이터를 정리하고 준비하는 것은 정확한 시각화를 생성하는 데 중요합니다. 이 단계에는 키워드의 다양한 변형을 정규화하고 "F1"을 일관된 형식으로 표준화하며 텍스트로부터 원치 않는 문자 또는 노이즈를 제거하는 것이 포함됩니다. 올바른 전처리는 최종 워드 클라우드가 주요 주제와 용어를 효과적으로 대표하도록 보장합니다.
다음은 이러한 단계를 보여주는 코드입니다:
# 사용자 지정 불용어 정의
custom_stopwords = set(STOPWORDS).union({
'RT', 'https', 'the', 'and', 'of', 'to', 'will', 'much', 'see', 'now', 'seen',
'come', 'know', 'haa', 'football club', 'even', 't', 'co', 'f1oki f1okidao',
'far', 'take', 'don', 'f1okidao', 'f1okidao doge', 'thing',
'got', 'really', 's', 'u', 'still', 'way', 'f1'
})
# 모든 텍스트 데이터를 대소문자를 변경하지 않고 단일 문자열로 결합합니다.
all_text = ' '.join(f1['text'].fillna(''))
# "F1"과 같은 용어를 불필요한 변형을 제거하고 정규화합니다.
all_text = re.sub(r'\bf1\b', 'F1', all_text, flags=re.IGNORECASE) # "f1"을 "F1"로 대체합니다.
all_text = re.sub(r'#f1\b', 'F1', all_text, flags=re.IGNORECASE) # #f1을 F1로 대체합니다.
all_text = re.sub(r'\bf1gp\b', 'F1', all_text, flags=re.IGNORECASE) # f1gp를 F1로 대체합니다.
# 사용자 지정 불용어와 컬러맵을 사용하여 워드 클라우드를 생성합니다.
wordcloud = WordCloud(
width=800,
height=400,
stopwords=custom_stopwords, # 사용자 지정 불용어 적용
background_color='white', # 대조를 위한 흰색 배경
colormap='viridis' # 사용자 정의 컬러맵
).generate(all_text)
# 워드 클라우드를 표시합니다.
plt.figure(figsize=(10, 6)) # 더 나은 표시를 위해 그림 크기 조정
plt.imshow(wordcloud, interpolation='bilinear') # 부드러운 렌더링
plt.axis('off') # 축 숨기기
plt.title('사용자 지정 불용어가 포함된 F1 트윗의 워드 클라우드') # 제목 추가
plt.show() # 플롯 렌더링

컬러맵 및 사용자 정의 색상:
다음으로, 미리 정의된 및 사용자 정의 색상지도를 활용하여 단어 구름의 시각적 매력을 높일 수 있는 방법을 살펴보겠습니다.
- 미리 정의된 색상지도: Matplotlib은 내장된 다양한 색상지도를 제공하여 단어 구름에 적용할 수 있습니다. 이러한 미리 정의된 색상지도는 다양한 색상 조합을 선택할 수 있도록 제공하며, 데이터에 가장 적합한 팔레트를 찾기 위해 실험할 수 있습니다.
- 사용자 정의 색상지도: 더 개인적인 터치를 더하기 위해, 특정 주제에 맞게 설계하고 적용할 수 있는 사용자 정의 색상지도를 생성할 수 있습니다. 예를 들어, 주제별 단어 구름을 위해 F1 팀에서 영감을 받은 색상을 사용할 수 있습니다.
다음은 사용자 정의 색상지도를 생성하고 적용하는 방법입니다:
# F1 팀 관련 색상을 영감을 받아 사용자 정의 색상지도 정의
f1_theme_cmap = LinearSegmentedColormap.from_list('f1_theme', ['#00D2BE', '#FFFFFF', '#000000'])
# 사용자 정의 색상지도와 불용어를 사용하여 단어 구름 생성
wordcloud = WordCloud(
width=800,
height=400,
stopwords=custom_stopwords, # 사용자 정의 불용어 적용
background_color='white', # 대비를 위한 흰 배경
colormap=f1_theme_cmap # 사용자 정의 색상지도 사용
).generate(all_text)
# 단어 구름 표시
plt.figure(figsize=(10, 5)) # 더 나은 표시를 위한 그림 크기 조정
plt.imshow(wordcloud, interpolation='bilinear') # 부드러운 렌더링
plt.axis('off') # 축 숨기기
plt.title('칼럼바와 불용어를 사용한 F1 트윗 단어 구름') # 제목 추가
plt.show() # 플롯 렌더링
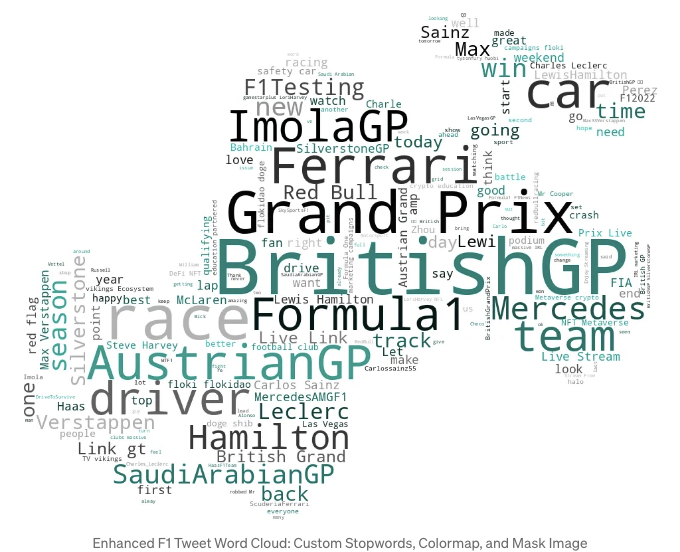
모양 및 마스크 이미지:
우리가 알아볼 최종 고급 맞춤 기술은 특정 모양의 워드 클라우드를 만들기 위해 마스크 이미지를 사용하는 것입니다.
- 마스크된 워드 클라우드 생성: 이미지 마스크를 사용하여 워드 클라우드를 다양한 모양으로 사용자 정의할 수 있습니다. 예를 들어, F1 테마 워드 클라우드에 레이싱 카 모양을 사용할 수 있습니다. 마스크는 단어 클라우드의 주제적 연관성을 향상시키는 창의적 시각화를 가능하게 합니다. 마스크 이미지를 선택할 때는 배경에 대비가 높고, 복잡하지 않은 간단한 이미지를 선택하는 것이 중요합니다. 이 접근 방식은 텍스트가 마스크 모양 내에서 명확하게 표시되어 시각적으로 강조된 워드 클라우드를 보장합니다.
- 크기 조정과 스케일링: 이미지 크기와 해상도를 올바르게 처리하는 것은 명확성과 영향력을 보장하기 위해 중요합니다. 워드 클라우드의 치수는 마스크 이미지의 것과 일치해야 시각적 무결성을 유지할 수 있습니다.
마스크 이미지를 사용하여 워드 클라우드를 생성하는 방법의 예시입니다:
# 마스크 이미지의 경로를 정의합니다
mask_path = 'path/to/your/mask_image.png' # 이 경로를 사용자의 마스크 이미지 위치에 맞게 업데이트해주세요
# 마스크 이미지를 불러옵니다
mask_image = np.array(Image.open(mask_path))
# 마스크 이미지와 사용자 지정 설정을 활용하여 워드 클라우드를 생성합니다
wordcloud = WordCloud(
width=mask_image.shape[1], # 마스크 이미지의 너비와 일치시킵니다
height=mask_image.shape[0], # 마스크 이미지의 높이와 일치시킵니다
background_color='white', # 대비를 위한 밝은 배경색
colormap=f1_theme_cmap, # 미리 정의된 컬러맵 객체 사용
stopwords=custom_stopwords, # 사용자 지정 불용어 적용
mask=mask_image # 마스크 이미지 적용
).generate(all_text)
# 워드 클라우드를 표시합니다
plt.figure(figsize=(11.25, 6.25)) # 더 나은 표시를 위한 그림 크기 조정
plt.imshow(wordcloud, interpolation='bilinear') # 부드러운 렌더링
plt.axis('off') # 축 숨기기
plt.title('향상된 F1 트윗 워드 클라우드: 사용자 지정 불용어, 컬러맵, 마스크 이미지 적용') # 제목 추가
plt.show() # 플롯 렌더링
시각화 및 미학
지금까지 다룬 고급 사용자 정의 사항들은 워드 클라우드의 정보 가치를 향상시키는 데 중요하지만, 최종 결과물의 시각적 매력과 가독성을 고려하는 것도 중요합니다. 워드 클라우드 시각화의 전체적인 미적 요소를 향상시키는 중요 기법 몇 가지를 살펴보겠습니다.
가독성 향상: 텍스트의 명확한 가시성은 강렬한 영향력 있는 워드 클라우드를 만드는 데 핵심적입니다. 시각화에서 사용되는 글꼴 크기, 간격 및 색상을 신중하게 조정하여 이를 구현할 수 있습니다.
배경과 대조: 배경색 선택과 텍스트와 배경 간 대비는 워드 클라우드의 전반적인 가독성에 중요한 역할을 합니다. 적절한 배경을 선택하고 충분한 대조를 보장하면 단어가 돋보이고 시청자의 주의를 효과적으로 끌 수 있습니다.
이러한 시각적 섬세함에 초점을 맞추면 유용한 통찰력을 제공하는 것뿐만 아니라 정돈되고 전문적인 외관을 가진 워드 클라우드 시각화를 만들 수 있습니다. 이러한 미학적 고려 사항은 데이터 분석 자산의 영향력과 사용 용이성을 크게 향상시킬 수 있습니다.
결론
이 게시물에서는 보다 효과적이고 파급력 있는 단어 구름을 만들기 위한 다양한 기술을 살펴보았습니다. 기초부터 시작하여 고급 사용자 정의까지 진행했습니다. 우리는 사용자 정의 불용어를 적용하여 관련 없는 용어를 걸러내는 방법, 사전 정의 및 사용자 정의 컬러맵을 활용하여 시각적 매력을 높이는 방법, 그리고 마스크 이미지를 활용하여 특정 모양의 단어 구름을 생성하는 방법을 다뤘습니다. 이러한 고급 기술을 사용하면 정보를 전달할 뿐만 아니라 시각적으로 돋보이는 단어 구름을 만들 수 있습니다.
이 안내서가 단어 구름 작업의 능력과 세세한 부분을 더 잘 이해하는 데 도움이 되었으면 좋겠습니다. 우리가 다룬 Python 및 R 라이브러리가 견고한 기반을 제공하지만 시각성과 사용자 정의 옵션에 제한이 있을 수 있습니다. 단어 구름이 프로젝트에서 중요한 역할을 하는 경우 또는 탐색적 데이터 분석의 상당 부분을 차지하는 경우 Word Cloud Plus, Josh Davies 및 Word Art와 같은 전문 온라인 도구를 탐색할 수 있는지 고려해 보십시오.
Python에서 사용하는 'wordcloud' 라이브러리에 대한 자세한 내용은 해당 공식 PyPI 페이지를 방문해주세요.
이 보다 더 효과적인 워드 클라우드 시각화를 만들어가는 이 여정을 따라주셔서 감사합니다. 여기서 공유된 기술과 통찰력이 데이터 분석과 이야기 전달 노력을 더 높은 수준으로 끌어올리는 데 도움이 되기를 바랍니다.
출처
- 데이터: Kaggle의 Formula 1 (F1) 트렌딩 트윗 데이터셋, CC0 1.0 라이선스에 따라 공개 도메인입니다.
- 이미지: Iconduck의 레이싱 카 이모지, CC BY 4.0 라이선스로 사용되었습니다.