Python-oracledb 2.4에서 파이프라이닝 기능이 도입되어 Python 애플리케이션의 성능과 확장성이 향상되었습니다. 파이프라이닝은 python-oracledb에서 간단합니다: "파이프라인" 객체에 INSERT 및 SELECT 문과 같은 작업을 추가하여 이 객체를 데이터베이스로 보내고, 데이터베이스가 문을 처리한 후 모든 결과를 애플리케이션으로 반환합니다. API가 비동기식이므로 애플리케이션이 파이프라인을 제출한 후 데이터베이스가 처리하는 동안 다른 로컬 작업을 계속할 수 있습니다. 이를 통해 데이터베이스 서버와 애플리케이션이 계속 작업하도록 유지되어 효율성이 향상되며 서로 대기하지 않아도 문과 결과를 제출하거나 가져올 수 있습니다.
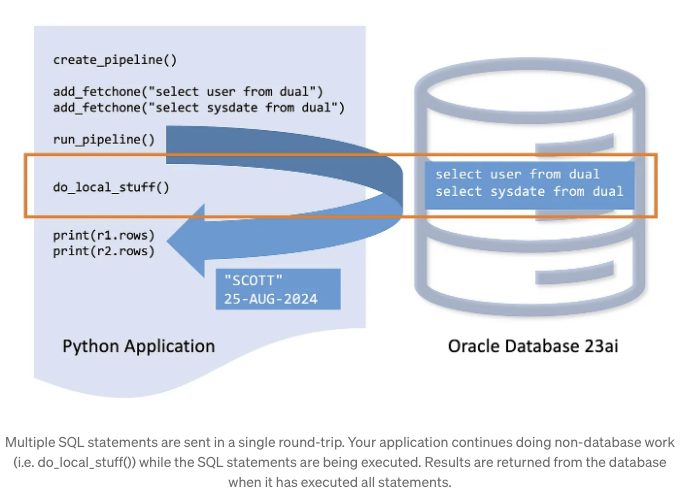
파이프라이닝 개요
파이프라이닝은 빠르게 연속적으로 많은 소규모 데이터베이스 작업이 필요한 경우 유용합니다. 이는 JDBC, Oracle Call Interface, ODP.NET 및 Python을 포함한 다양한 드라이버에서 지원됩니다.
오라클 데이터베이스 23ai 파이프라이닝의 장점:
- 데이터베이스가 문 처리를 하고 있는 동안 앱이 로컬 작업을 수행할 수 있습니다.
- 앱은 두 번째 문을 보내기 전에 한 번의 데이터베이스 응답을 기다릴 필요가 없습니다.
- 앱은 계속해서 바쁘게 유지됩니다.
- 데이터베이스가 한 문 처리를 마치고 나면 앱이 결과를 가져오고 두 번째 문을 보내기를 기다릴 필요가 없습니다.
- 데이터베이스 역시 계속해서 바쁘게 유지됩니다.
- 라운드트립 횟수 감소: 오라클 네트워크 리스너 호출 횟수 감소, 인터럽트 감소, 네트워크 사용 효율성 향상.
- 전체 시스템 확장성이 향상됩니다.
라운드트립 감소는 파이프라이닝의 성능 향상에 중요한 역할을 합니다. 하지만 고속 네트워크에서는 파이프라이닝의 성능 이점이 작을 수 있지만, 파이프라이닝의 데이터베이스 및 네트워크 효율성은 시스템 확장성에 도움을 줄 수 있습니다.
파이프라이닝은 파이썬에서 python-oracledb의 Async 클래스를 통해 사용할 수 있습니다. 이는 python-oracledb의 기본 Thin 모드를 사용하고 비동기 프로그래밍 스타일로 사용해야 함을 의미합니다. 파이프라이닝은 오라클 데이터베이스 23ai에서 작동합니다. (새로운 python-oracledb API를 구 버전 데이터베이스에 연결하여 사용할 수는 있지만, 내부 파이프라이닝 동작과 이점을 얻을 수는 없습니다. 이는 이주나 호환성 목적으로만 권장됩니다). Oracle Database 23ai를 Oracle Database Software Downloads에서 얻을 수 있습니다.
파이프라인에 작업을 추가하는 데 다음 Python-oracledb 호출을 사용할 수 있어요:
- add_callfunc() - 저장된 PL/SQL 함수 호출하기
- add_callproc() - 저장된 PL/SQL 프로시저 호출하기
- add_commit() - 현재 연결의 트랜잭션 커밋하기
- add_execute() - 하나의 SQL 문 실행하기
- add_executemany() - 많은 바인드 값을 사용하여 하나의 SQL 문 실행하기
- add_fetchall() - 쿼리를 실행하고 모든 결과 가져오기
- add_fetchmany() - 쿼리를 실행하고 결과 세트를 가져오기
- add_fetchone() - 쿼리를 실행하고 하나의 행 가져오기
데이터베이스는 파이프라인 문을 순차적으로 처리합니다. 병렬성의 이점은 애플리케이션의 로컬 작업과 데이터베이스 작업 사이에 있어요.
한 작업에서 쿼리 결과 또는 OUT 바인드를 다른 작업에 전달할 수 없습니다. 파이프라인 작업의 결과를 후속 데이터베이스 단계에서 사용해야 한다면 여러 파이프라인을 사용할 수 있어요.
소셜 네트워크 예시
소셜 네트워킹 사이트의 사용 예시입니다. 로그인한 후, 홈페이지에는 다양한 소스에서 수집한 정보가 표시되어야 합니다. 친구 중 몇 명이 로그인한 상태인지를 보여줄 수 있습니다. 뉴스 피드에서는 하루 중 가장 인기 있는 뉴스 항목이 표시될 수 있습니다. 현재 및 예상 온도를 보여줄 수 있습니다. 이러한 데이터 중 일부는 데이터베이스에 저장될 수 있지만, 검색하려면 여러 개의 서로 다른 쿼리가 필요할 수 있습니다. 현재 온도를 찾기 위해서는 Python이 해당 데이터를 반환하기 위해 서비스를 호출할 수도 있습니다. 이는 Pipelining에 대한 훌륭한 사용 사례입니다: 서로 다른 쿼리를 처리하기 위해 파이프라인에 전송할 수 있으며, 원격 온도 센서 데이터는 동시에 수집될 수 있습니다.
이 간단한 예시 웹 앱의 전체 코드는 pipeline-blog-quart.py 파일에 있습니다.
앱은 비동기적으로 실행되어야 하므로 이를 지원하는 프레임워크가 필요합니다. 저는 Quart 미니 프레임워크를 선택했습니다. 이는 Flask와 관련이 있습니다. Flask의 비동기 지원은 완전히 비동기 애플리케이션에는 충분하지 않습니다.
app = Quart(__name__, )
# 사용자 홈페이지
@app.route("/homepage")
async def homepage():
r = await getdata() # 데이터베이스 및 원격 온도 센서를 호출함
return buildhtml(r) # 데이터를 HTML 페이지에 넣고 표시하기 위해 반환함
@app.before_serving
async def setup():
start_pool() # 연결 풀 시작
await create_schema() # 데모 테이블 생성
if __name__ == "__main__":
print(f"http://127.0.0.1:{PORT}/homepage을(를) 브라우저에서로드해 보세요.")
app.run(port=PORT)
실제 다중 사용자 앱에서 연결 풀링이 중요하므로 이를 어떻게 사용할 수 있는지 보여주기로 선택했습니다. 올바르게 구현하고 구성하는 데 주의를 기울여야 하는 사항입니다.
그런 다음 데모 목적으로 앱은 시작할 때 스키마를 생성하고 샘플 데이터를 로드합니다. (로딩 자체가 파이프라이닝의 또 다른 사용 사례이며 앱의 create_schema()에서 여러 SQL 문이 필요한 예제입니다).
홈페이지 URL이 호출될 때마다 getdata() 루틴이 호출됩니다. 여기서 파이프라이닝이 정말 빛을 발합니다. 이 메서드는 데이터베이스 쿼리를 수행하고 온도 센서에 동시에 액세스합니다. 모든 데이터가 수집되면 buildhtml()에 의해 HTML 페이지로 서식이 지정되고 Quart에 의해 표시됩니다. getdata() 메서드와 외부 센서 메서드인 get_current_temperature()은 다음과 같습니다:
async def get_current_temperature():
return randint(0, 50) # 온도계가 반환한 가짜 데이터 - 물론 섭씨로
async def getdata():
global pool
async with pool.acquire() as connection:
# 파이프라인 생성 및 작업 정의
pipeline = oracledb.create_pipeline()
pipeline.add_fetchone("select high from weather")
pipeline.add_fetchall("select name from friends where active = true")
pipeline.add_fetchall("select story from news order by popularity fetch next 5 rows only")
# 파이프라인 및 비데이터베이스 작업을 동시에 실행
current_temp, result_pl = await asyncio.gather(
get_current_temperature(),
connection.run_pipeline(pipeline)
)
# 데이터베이스 파이프라인 쿼리 결과 추출
t = result_pl[0].rows[0][0] # 최고 예상 온도
f = [n for n, in result_pl[1].rows] # 활성 친구 목록
n = [s for s, in result_pl[2].rows] # 상위 5개 뉴스 기사
return { "current": current_temp, "forecast": t, "friends": f, "news": n }
이 코드는 세 개의 SELECT 문을 사용하여 파이프라인을 생성합니다. asyncio.gather()를 사용하여 파이프라인이 get_current_temperature()을 호출하면서 병렬로 실행됩니다(외부 온도계를 읽는 가짜 작업). 모든 데이터가 준비되면 dict 형태로 반환됩니다.
앱을 시작하고 브라우저에서 홈페이지를 로드하면 다음과 같은 페이지가 표시됩니다:
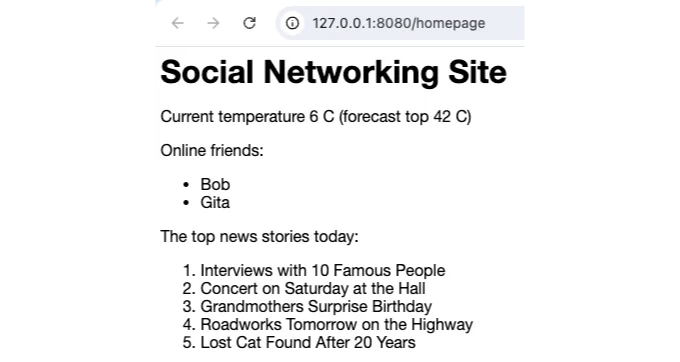
온도계의 읽기와 데이터베이스 작업이 동시에 실행됩니다: 응용 프로그램과 데이터베이스가 모두 바쁩니다. 응용 프로그램 응답 시간이 감소하여 사용자가 더 행복해집니다. 데이터베이스가 작업 중일 때 끊김이나 일시 중지가 적어져 더 효율적으로 작동합니다. 전반적인 시스템 확장성이 향상되었습니다.
성능 예시
다양한 작업을 수행하는 예시 파이프라인은 성능 이점을 더 잘 이해할 수 있게 해줍니다.
파이프라이닝을 사용하지 않는 프로그램으로 시작해보겠습니다 (pipeline-bm-non.py를 참조하십시오). 이 프로그램은 파이썬-oracledb의 기존 비동기 기능을 사용하지만 모든 문은 순차적으로 실행됩니다:
# 파이프라이닝 없음
for i in range(50):
await connection.execute("insert into TestTempTable values (:1, :2)", [i + 1, f"Value {i + 1}"])
await connection.execute("""
update TestTempTable set Description = Description || ' (modified)'
where mod(ID, 2) = 1""")
for i in range(50):
await connection.execute("insert into TestTempTable values (:1, :2)", [i + 51, f"Value {i + 51}"])
await connection.commit()
rows = await connection.fetchall("select * from TestTempTable")
데모에서 동일한 INSERT 문을 많이 실행한다는 점에 유의하십시오. 이것은 단순히 "큰" 파이프라인 길이를 보여주기 위한 것입니다. 프로덕션 환경에서는 파이프라이닝 및 파이프라이닝 코드를 사용할 때, 이러한 흐름에는 executemany()를 사용해야 합니다.
그러나, 이 주석은 떠나두고, 실행된 각 문마다 라운드트립이 필요합니다.
왕복 횟수를 줄이기 위해 스크립트를 파이프라인 방식으로 변환할 수 있습니다 (pipeline-bm.py 참조):
# Oracle Database 23ai와 함께 파이프라인
pipeline = oracledb.create_pipeline()
for i in range(50):
pipeline.add_execute("insert into TestTempTable values (:1, :2)", [i + 1, f"Value {i + 1}"])
pipeline.add_execute("""
update TestTempTable set
Description = Description || ' (modified)'
where mod(ID, 2) = 1""")
for i in range(50):
pipeline.add_execute("insert into TestTempTable values (:1, :2)", [i + 51, f"Value {i + 51}"])
pipeline.add_commit()
pipeline.add_fetchall("select * from TestTempTable")
result = await connection.run_pipeline(pipeline)
이렇게 하면 run_pipeline()이 호출될 때 한 번의 왕복만 필요합니다.
제 노트북에서는 로컬에서 실행되는 데이터베이스가 에뮬레이트된 컨테이너 환경에서 일반적인 종단 간 시간 결과를 보았습니다.
$ python3 pipeline-bm.py; python3 pipeline-bm-non.py
파이프라이닝: 0.34 초
파이프라이닝 없음: 0.46 초
이 특별한 결과는 응용 프로그램의 데이터베이스 작업에 대한 종단 간 시간 26% 감소입니다. 여러분의 결과는 다를 수 있습니다. 파이프라인 응용 프로그램은 훨씬 효율적이었습니다. 또한 데이터베이스가 문을 처리하는 동안 응용 프로그램이 동시에 다른 작업을 계속할 수 있도록 병렬 처리를 사용하여 전체 응용 프로그램 성능을 더욱 향상시킬 수 있었습니다. (소셜 네트워킹 예제에서 보여줌)
결론
오라클 데이터베이스 23ai의 파이프라이닝은 데이터베이스가 작업 중일 때 응용 프로그램이 로컬 작업을 동시에 계속할 수 있도록 하여 응용 프로그램 성능과 시스템 확장성을 개선하는 기술입니다. 파이프라이닝은 python-oracledb, JDBC, ODP.Net 및 Oracle Call Interface를 사용하는 응용 프로그램에서 사용할 수 있습니다.
파이프라인은 연속적으로 많은 작은 데이터베이스 작업을 수행해야 할 때 유용합니다. 네트워크 비용이 높을 때 가장 효과적입니다. 그러나 빠른 네트워크에서나 작은 작업의 경우에도 파이프라인은 시스템 이점을 제공합니다.
파이썬 오라클DB 2.4의 새로운 파이프라인 지원은 asyncio를 기존 지원에 추가합니다. 새로운 파이프라인 클래스를 통해 Thin 모드로 사용할 수 있습니다. 이 릴리스에서는 API를 최종화하기 전에 작은 또는 큰 변경 사항을 테스트하고 제안할 시간을 주기 위해 '실험적'으로 표시되었습니다. 우리는 asyncio로 테스트했습니다. uvloop와 같은 기타 대안과의 동작에 대한 피드백은 매우 소중합니다.
파이프라인 참고 자료
- 파이썬 오라클DB 문서: 데이터베이스 작업 파이프라인
- 블로그: 오라클 데이터베이스 23ai용 파이프라인 및 비동기 프로그래밍 소개
- 오라클 Call Interface 문서: OCI 파이프라인
- 블로그: 자바 개발자를 위한 '오라클 DB 23c 무료 개발자 릴리스'의 새로운 기능
- JDBC 문서: 파이프라인 데이터베이스 작업 지원
- 블로그: 비동기 ODP.NET 및 파이프라인: 지연 시간 감소로 성능 향상
python-oracledb 설치 또는 업그레이드
다음을 실행하여 python-oracledb를 설치 또는 업그레이드할 수 있습니다:
python -m pip install oracledb --upgrade
일부 환경에서 유용할 수 있는 pip 옵션인 --proxy 및 --user은 python-oracledb 설치 세부 정보에서 확인할 수 있습니다.
Python-oracledb 참조 자료
홈페이지: oracle.github.io/python-oracledb/index.html
설치 안내: python-oracledb.readthedocs.io/en/latest/installation.html
문서: python-oracledb.readthedocs.io/en/latest/index.html