오브젝트 감지를 위한 프로덕션 급 파이프라인 생성 방법
목차
- 소개 (또는 제목에 뭐가 있을까?)
- Ops 없는 MLOps의 현실
- 의존성 효율적으로 관리하기
- 프로덕션 플로우 디버깅하는 방법
- 골디락스 스텝 사이즈 찾는 방법
- 배운 점
- 참고문헌
관련 링크
- GitHub 저장소
- 이 프로젝트의 개발 버전에 대해 이전에 논의된 기사 링크
소개 (또는 제목에 있는 내용)
데이터 과학 분야의 직책 이름을 알아보는 일은 혼란스러울 수 있습니다. 최근 LinkedIn에서 본 일부 예시만 소개해드리겠습니다:
- 데이터 과학자
- 기계 학습 엔지니어
- ML Ops 엔지니어
- 데이터 과학자/기계 학습 엔지니어
- 기계 학습 성능 엔지니어
- ...
그리고 목록은 계속되어 갑니다. 두 가지 주요 역할에 초점을 맞춰 봅시다: 데이터 과학자와 기계 학습 엔지니어. Chip Huyen이 저서 "Introduction to Machine Learning Interviews" [1]에서 말한 바에 따르면:
알겠어요. 그래서 데이터 과학자는 통계를 알아야 하고, ML 엔지니어는 ML 알고리즘을 알아야 합니다. 그러나 데이터 과학의 목표는 비즈니스 통찰력을 생성하는 것이라면, 2024년에 가장 강력한 통찰력을 생성하는 알고리즘들은 주로 기계 학습(특히 딥 러닝)에서 나오는 경향이기 때문에 두 역할 간의 구분이 희미해집니다. 아마도 앞서 본 데이터 과학자/기계 학습 엔지니어 제목을 설명하는 이유일지도 모릅니다.
Huyen은 덧붙여 말합니다:
2020년에 작성된 글입니다. 2024년까지는 ML 엔지니어링과 데이터 과학 사이의 경계가 실제로 흐려지고 있습니다. 따라서 ML 모델을 구현하는 능력이 분리 선이 아니라면, 무엇이 분리 선인가요?
물론 실무자마다 그 선은 다릅니다. 오늘날, 전형적인 데이터 과학자와 ML 엔지니어의 차이는 다음과 같습니다:
- 데이터 과학자: 주피터 노트북에서 작업, Airflow에 대해 들어본 적이 없음, Kaggle 전문가, 코드 셀을 올바른 순서로 수동으로 실행하는 파이프라인, 하이퍼파라미터 튜닝에 능함, 도커? 여름에 좋은 신발! 개발 중심.
- 머신러닝 엔지니어: 파이썬 스크립트 작성, Airflow에 대해 들어봤지만 좋아하지 않음 (Prefect를 선호!), Kaggle 중급, 자동화된 파이프라인, 튜닝 작업은 데이터 과학자에게 맡김, 도커 애호가. 제품 중심.
대기업에서는 데이터 과학자가 비즈니스 문제를 해결하기 위해 머신러닝 모델을 개발한 다음 ML 엔지니어에게 전달합니다. 엔지니어들은 이러한 모델을 제품화하고 배포하여 확장성과 견고성을 보장합니다. 요약하자면: 현재 데이터 과학자와 머신러닝 엔지니어의 근본적인 차이는 머신러닝을 사용하는 사람이 누구인지가 아니라 개발 또는 제품에 초점을 맞추고 있는지에 있습니다.
하지만 대기업이 아닌 스타트업이나 소규모 기업이라면, 데이터 과학 팀을 고용할 예산이 한정되어 있을 수도 있습니다. 이럴 때는 데이터 과학자/머신러닝 엔지니어 하나 또는 몇 명을 고용하고자 할 것입니다! 신화적인 "풀 스택 데이터 과학자"가 되기 위해, 저는 이전 프로젝트 중 하나인 RetinaNet과 KerasCV를 사용한 객체 탐지 프로젝트를 제품화하기로 결심했습니다(관련 기사 및 코드 링크를 보려면 위 링크를 참조하십시오). 원래 Jupyter 노트북을 사용하여 수행된 원본 프로젝트에는 몇 가지 결점이 있었습니다:
- 모델 버전 관리, 데이터 버전 관리 또는 심지어 코드 버전 관리가 없었습니다. 특정 실행의 Jupyter 노트북이 작동했지만 그 다음에는 작동하지 않을 경우, 작동하던 스크립트/모델로 돌아가는 방법이 체계적으로 없었습니다(Ctrl + Z? Kaggle의 저장 노트북 옵션?).
- 모델 평가는 Matplotlib과 일부 KerasCV 플롯을 사용하여 비교적 간단히 이루어졌습니다. 평가 결과를 저장하는 기능이 없었습니다.
- 우리는 Kaggle GPU의 무료 20시간으로 컴퓨팅 자원이 제한되었습니다. 더 큰 컴퓨팅 인스턴스를 사용하거나 병렬로 여러 모델을 학습시키는 것이 불가능했습니다.
- 모델을 어떤 엔드포인트에도 배포하지 않았기 때문에 Jupyter 노트북 밖에서 예측을 얻을 수 없었습니다(비즈니스 가치가 없었습니다).
이 작업을 수행하기 위해 저는 Metaflow를 시도하기로 결정했습니다. Metaflow는 데이터 과학자가 ML 모델을 학습하고 배포하는 데 도움을 주기 위해 설계된 오픈 소스 ML 플랫폼입니다. Metaflow는 주로 두 가지 기능을 제공합니다:
- 워크플로 조정기. Metaflow는 워크플로를 단계별로 분해합니다. Python 함수를 Metaflow 단계로 변환하는 것은 함수 위에 @step 데코레이터를 추가하는 것만으로 간단합니다. Metaflow는 Airflow와 같은 워크플로 도구에서 제공하는 모든 기능을 가지고 있지는 않지만, 간단하고 Python 스타일이며 AWS Step Functions을 외부 조정자로 사용하도록 설정할 수 있습니다. 또한 Metaflow와 함께 Airflow나 Prefect와 같은 적절한 조정자를 함께 사용하는 것에는 아무 문제가 없습니다.
- 인프라 추상화 도구. 여기서 Metaflow가 정말 빛을 발합니다. 일반적으로 데이터 과학자는 자신의 노트북에서 AWS로 모델 훈련 작업을 보내기 위해 필요한 인프라를 수동으로 설정해야 합니다. 이를 위해서는 API 게이트웨이, 가상 사설망(VPC), Docker/Kubernetes, 서브넷 마스크 등 인프라에 대한 지식이 필요합니다. 이는 머신 러닝 엔지니어의 업무처럼 들립니다! 그러나 Cloud Formation 템플릿(인프라 코드 파일) 및 @batch Metaflow 데코레이터를 사용하여, 데이터 과학자는 간단하고 신뢰할 수 있는 방법으로 클라우드로 컴퓨팅 작업을 보낼 수 있습니다.
이 글은 Metaflow, AWS 및 Weights & Biases를 사용하여 객체 탐지 모델을 제품화하는 여정을 소개합니다. 이 과정에서 배운 네 가지 주요 교훈을 살펴볼 것입니다:
- "Ops 없는 MLOps"의 현실
- 효과적인 종속성 관리
- 제품화된 흐름에 대한 디버깅 전략
- 워크플로 구조 최적화
이러한 통찰을 공유함으로써, 개발자에서 제품 중심 업무로의 전환 과정에서 직업 소양자인 여러분을 인도하고, 도중에 마주친 어려움과 해결책을 강조하려 합니다.
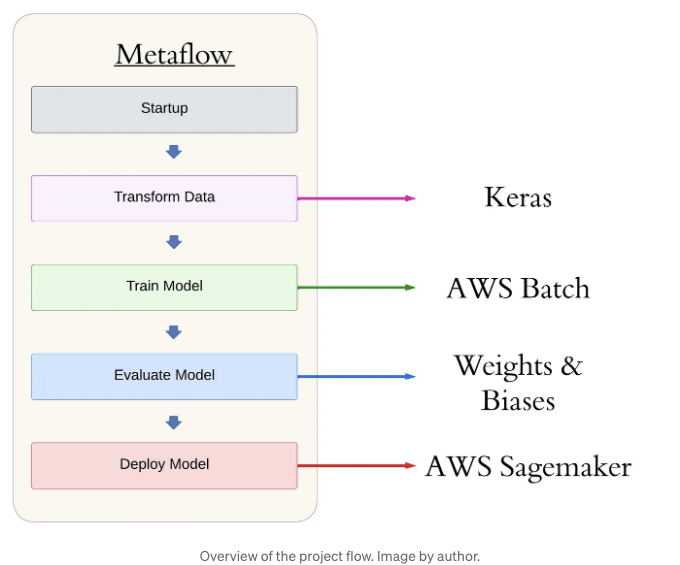
구체적인 내용에 대해 자세히 알아보기 전에, Metaflow 파이프라인의 고수준 구조를 살펴보겠습니다. 이를 통해 글 전반에 걸쳐 다룰 워크플로를 전체적으로 파악할 수 있을 것입니다:
from metaflow import FlowSpec, Parameter, step, current, batch, S3, environment
class main_flow(FlowSpec):
@step
def start(self):
"""
시작: 모든 것이 잘 작동하는지 확인하거나 빠르게 실패하십시오!
"""
self.next(self.augment_data_train_model)
@batch(gpu=1, memory=8192, image='docker.io/tensorflow/tensorflow:latest-gpu', queue="job-queue-gpu-metaflow")
@step
def augment_data_train_model(self):
"""
S3에서 데이터를 가져 와서 증강하고 모델을 훈련하는 코드.
"""
self.next(self.evaluate_model)
@step
def evaluate_model(self):
"""
Weights & Biases를 사용하여 우리의 탐지 모델을 평가하는 코드.
"""
self.next(self.deploy)
@step
def deploy(self):
"""
Sagemaker 엔드포인트로 우리의 탐지 모델을 배포하는 코드.
"""
self.next(self.end)
@step
def end(self):
"""
마지막 단계!
"""
print("모두 완료. \n\n 축하합니다! 전 세계의 식물들이 감사할 것입니다. \n")
return
if __name__ == '__main__':
main_flow()
이 구조는 제품 등급의 객체 탐지 파이프라인의 주축을 형성합니다. Metaflow는 파이프라인에서 함수를 스텝으로 나타내고, 의존성 관리를 처리하며, 계산을 클라우드로 이동하는 데 장식자를 사용하는 Pythonic한 도구입니다. 단계는 self.next() 명령을 통해 순차적으로 실행됩니다. Metaflow에 대해 더 자세히 알아보려면 설명서를 참조하세요.
Ops 없이 MLOps의 현실
Metaflow의 한 가지 장점은 데이터 과학자가 신경 써야 할 것에 초점을 맞출 수 있어야 한다는 것입니다. 일반적으로 모델 개발 및 피처 엔지니어링(카글 생각)과 같은 영역을 개인화하면서 계산이 실행되는 위치, 데이터가 저장되는 위치 등의 관심 없는 부분을 추상화합니다. 이러한 아이디어에는 "Ops 없는 MLOps"라는 문구가 있습니다. 이것을 의미하는 것으로는 MLOps 엔지니어의 작업을 추상화할 수 있을 것으로 생각했습니다. 하지만 도커, CloudFormation 템플릿, EC2 인스턴스 유형, AWS 서비스 할당량, Sagemaker 엔드포인트 및 AWS Batch 구성에 대해 배우거나 실제로 수행하지 않고도 MLOps 엔지니어의 작업을 추상화할 수 있을 것으로 생각했습니다.
안타깝게도, 이것은 순진했습니다. Metafow 튜토리얼에서 링크된 CloudFormation 템플릿이 AWS에서 GPU를 프로비저닝하는 방법을 제공하지 않는다는 사실을 깨달았어요(!). 클라우드에서 데이터 과학을 수행하는 데 있어서 이것은 근본적인 부분이기 때문에 이에 대한 문서가 없다는 것은 놀랍다는 점이죠. (이에 대한 문서의 부족에 대해 궁금해하는 첫 번째 사람은 아닙니다.)
아래는 Metaflow에서 클라우드로 작업을 보내는 것이 어떻게 보이는지를 보여주는 코드 조각입니다:
@pip(libraries={'tensorflow': '2.15', 'keras-cv': '0.9.0', 'pycocotools': '2.0.7', 'wandb': '0.17.3'})
@batch(gpu=1, memory=8192, image='docker.io/tensorflow/tensorflow:latest-gpu', queue="job-queue-gpu-metaflow")
@environment(vars={
"S3_BUCKET_ADDRESS": os.getenv('S3_BUCKET_ADDRESS'),
'WANDB_API_KEY': os.getenv('WANDB_API_KEY'),
'WANDB_PROJECT': os.getenv('WANDB_PROJECT'),
'WANDB_ENTITY': os.getenv('WANDB_ENTITY')})
@step
def augment_data_train_model(self):
"""
Code to pull data from S3, augment it, and train our model.
"""
필요한 라이브러리를 명시하고 필요한 환경 변수를 지정하는 중요성에 유의해 보세요. 클라우드에서 컴퓨팅 작업을 실행하므로 로컬 컴퓨터의 가상 환경이나 .env 파일의 환경 변수에 액세스할 수 없다는 점이 중요합니다. 이 문제를 해결하기 위해 Metaflow 데코레이터를 사용하는 것은 우아하고 간단합니다.
AWS 전문가가 아니더라도 클라우드에서 컴퓨팅 작업을 실행할 수 있다는 사실이 맞지만, Metaflow를 설치하고 기본 CloudFormation 템플릿을 사용해서 성공을 기대하지는 마세요. Ops가 없는 MLOps는 사실이 좋다고 말하기 어렵습니다. 아마도 정말 Ops 없이 MLOps를 사용하기 전에 Ops를 조금 배우는 것이 좋겠죠.
종속성 효율적으로 관리하기
개발 프로젝트를 제품 프로젝트로 변환하려고 할 때 고려해야 할 가장 중요한 사항 중 하나는 종속성을 관리하는 방법입니다. 종속성은 TensorFlow, PyTorch, Keras, Matplotlib 등과 같은 Python 패키지를 의미합니다.
종속성 관리는 일정함을 보장하기 위해 레시피에서 재료를 관리하는 것과 유사합니다. 레시피에는 "소금 한 숟가락 넣기"라고 쓰여 있을 수 있습니다. 이는 어느 정도 복제 가능하지만, 알고 있는 독자는 "Diamond Crystal인지 Morton인지?" 물을 수 있습니다. 사용한 소금의 정확한 브랜드를 지정함으로써 레시피의 재현성을 극대화할 수 있습니다.
비슷한 방식으로, 머신러닝의 의존성 관리에는 수준이 있습니다:
- requirements.txt 파일을 사용합니다. 이 간단한 옵션은 모든 파이썬 패키지를 고정된 버전으로 나열합니다. 이 방법은 꽤 잘 작동하지만 제한 사항이 있습니다: 이 높은 수준의 의존성을 고정할 수는 있지만, 간접 의존성(의존성의 의존성)은 고정할 수 없습니다. 이로 인해 재현 가능한 환경을 만드는 것이 매우 어려워지고, 패키지를 다운로드하고 설치하는 과정이 느려집니다. 예를 들어:
pinecone==4.0.0
langchain==0.2.7
python-dotenv==1.0.1
pandas==2.2.2
streamlit==1.36.0
iso-639==0.4.5
prefect==2.19.7
langchain-community==0.2.7
langchain-openai==0.1.14
langchain-pinecone==0.1.1
이 방법은 꽤 잘 작동하지만 제한 사항이 있습니다: 높은 수준의 의존성을 고정할 수는 있지만, 간접 의존성(의존성의 의존성)을 고정할 수 없습니다. 이로 인해 재현 가능한 환경을 만드는 것이 매우 어렵고, 패키지를 다운로드하고 설치하는 과정이 느려집니다.
- 도커 컨테이너를 사용해보세요. 이 것이 골드 표준입니다. 이는 운영 체제, 라이브러리, 의존성 및 구성 파일을 포함한 전체 환경을 캡슐화하여 매우 일관된 환경을 만들어냅니다. 안타깝게도, Docker 컨테이너를 사용하는 것은 다소 번거롭고 어렵습니다. 특히 데이터 과학자가 플랫폼에 대한 이전 경험이 없는 경우 더 그렇습니다.
Metaflow의 @pypi/@conda 데코레이터는 두 가지 옵션 사이의 절충안 역할을 하며 데이터 과학자가 사용하기에 가벼우면서도 단순하며, requirements.txt 파일보다 더 견고하고 재현 가능합니다. 이러한 데코레이터는 기본적으로 다음을 수행합니다:
- 플로우의 각 단계에 대해 격리된 가상 환경을 생성합니다.
- 요구사항.txt 파일만큼 간단하지만 파이썬 인터프리터 버전을 결정합니다.
- 각 단계의 전체 종속성 그래프를 해결하고 안정성과 재현성을 위해 잠급니다. 이 잠긴 그래프는 메타데이터로 저장되어 간편한 감사 및 일관된 환경 재생성이 가능합니다.
- 클라이언트와 다른 운영 체제 및 CPU 아키텍처를 가진 원격 환경에서도 원격 실행을 위해 지역적으로 해결된 환경을 제공합니다.
이는 단순히 requirements.txt 파일을 사용하는 것보다 훨씬 나은 방법이며, 데이터 과학자가 추가로 학습할 필요가 없습니다.
테이블 태그를 마크다운 형식으로 변경해보세요:
| 라이브러리 | 버전 |
|---|---|
| tensorflow | 2.15 |
| keras-cv | 0.9.0 |
| pycocotools | 2.0.7 |
| wandb | 0.17.3 |
기억해 두었던 열차 단계를 다시 확인해 보러 가봅시다. 외부 라이브러리와 버전만 명시하면 Metaflow가 나머지를 처리해 줍니다.
안타깝게도 제 개인 노트북은 맥이지만, AWS Batch의 컴퓨팅 인스턴스는 Linux 아키텍처를 사용합니다. 따라서 Linux 기기용으로 격리된 가상 환경을 만들어야 합니다. 이 작업은 크로스 컴파일링이라고도 합니다. .whl(바이너리) 패키지로 작업할 때만 크로스 컴파일을 사용할 수 있습니다. .tar.gz나 기타 소스 배포 파일을 크로스 컴파일하려고 하면 문제가 발생합니다. 이는 Metaflow의 문제가 아닌 pip의 기능입니다. @conda 데코레이터를 사용하면 (conda는 pip이 해결하지 못하는 것을 해결해 주는 것으로 보입니다.) 문제가 해결됩니다. 그러나 컴퓨팅에 GPU를 사용하려면 conda에서 tensorflow-gpu 패키지를 사용해야 하며 여러 문제가 발생합니다. 해결 방법은 있지만, 이것들은 단순한 강의로 유지하려는 티테리얼에 너무 복잡함을 추가합니다. 결과적으로, requirements.txt를 사용하여 pip install -r을 하려고 했지만 (사용자 지정 Python @pip 데코레이터를 사용했습니다.) 그래도 작동했습니다. 그렇죠?
프로덕션 플로우의 디버깅 방법
초반에는 Metaflow를 사용하는 것이 느꼈습니다. 각 단계가 실패할 때마다 print 문을 추가하고 전체 플로우를 다시 실행해야 했기 때문에 시간이 많이 걸리고 비용이 많이 들었습니다. 특히 연산 집약적인 단계에서는 그랬습니다.
플로우 변수를 아티팩트로 저장하고 나중에 Jupyter 노트북에서 이러한 아티팩트의 값에 액세스할 수 있다는 것을 발견하고 나서 반복 속도가 급격히 향상되었습니다. 예를 들어, model.predict 호출의 출력 작업 중에는 디버깅을 위해 변수를 아티팩트로 저장했습니다. 다음은 그 방법입니다:
image = example["images"]
self.image = tf.expand_dims(image, axis=0) # Shape: (1, 416, 416, 3)
y_pred = model.predict(self.image)
confidence = y_pred['confidence'][0]
self.confidence = [conf for conf in confidence if conf != -1]
self.y_pred = bounding_box.to_ragged(y_pred)
여기서 model은 내가 완전히 훈련시킨 객체 탐지 모델이고, image는 샘플 이미지입니다. 이 스크립트 작업 중에 model.predict 호출의 출력과 작업하는 데 문제가 있었습니다. 출력물의 유형은 무엇이었습니까? 출력물의 구조는 어떠했습니까? 예제 이미지를 끌어오는 코드에 문제가 있었습니까?
이러한 변수를 검사하려면 self._ 표기법을 사용하여 아티팩트로 저장했습니다. 피클링할 수 있는 모든 객체는 Metaflow 아티팩트로 저장할 수 있습니다. 내 튜토리얼을 따르면 이러한 아티팩트는 차후에 참조하기 위해 Amazon S3 버킷에 저장됩니다. 예제 이미지가 올바르게 로드되는지 확인하려면 로컬 컴퓨터의 같은 저장소에서 Jupyter 노트북을 열고 다음 코드를 사용하여 이미지에 액세스할 수 있습니다:
import matplotlib.pyplot as plt
latest_run = Flow('main_flow').latest_run
step = latest_run['evaluate_model']
sample_image = step.task.data.image
sample_image = sample_image[0,:, :, :]
one_image_normalized = sample_image / 255
# matplotlib를 사용하여 이미지 표시
plt.imshow(one_image_normalized)
plt.axis('off') # 축 숨김
plt.show()
여기서 flow의 최신 실행을 가져와 Flow 호출에서 main_flow를 지정하여 flow 정보를 가져올 수 있는지 확인합니다. 내가 저장한 아티팩트는 evaluate_model 단계에서 왔기 때문에 이 단계를 지정합니다. .data.image를 호출하여 이미지 데이터 자체를 가져옵니다. 마지막으로 이미지를 플롯하여 테스트 이미지가 유효한지 또는 파이프라인 어디선가 문제가 있는지 확인할 수 있습니다.
Markdown 형식으로 테이블 태그를 변경해 드리겠습니다.
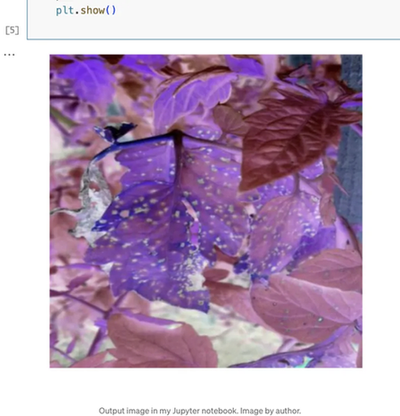
좋아요, 이 이미지는 PlantDoc 데이터셋에서 다운로드한 원본 이미지와 일치합니다 (색상이 조금 이상하게 보일 수 있어요.) 객체 탐지 모델의 예측 결과를 확인하려면 다음 코드를 사용할 수 있습니다:
latest_run = Flow('main_flow').latest_run
step = latest_run['evaluate_model']
y_pred = step.task.data.y_pred
print(y_pred)

이 이미지에서 예측된 경계 상자가 없다는 결과가 나타납니다. 흥미로운 사실이며, 왜 일부 단계가 이상하게 동작하거나 중단되는지를 알 수 있을 것입니다.
이 모든 작업은 모든 데이터 과학자들이 편안하게 사용할 수 있는 간단한 Jupyter 노트북에서 처리됩니다. 그렇다면 Metaflow에서 언제 변수를 아티팩트로 저장해야 할까요? Ville Tuulos의 제언을 따르면 다음과 같습니다:
만약 Metaflow를 사용 중이라면 제 경험을 참고하세요: 아티팩트와 Jupyter 노트북을 최대한 활용하여 프로덕션 수준 프로젝트에서 디버깅을 쉽게 할 수 있습니다.
또한 디버깅과 관련하여 한 가지 더 알아둘 점은 특정 단계에서 플로우가 실패하면 해당 실패한 단계부터 플로우를 다시 실행하려면 Metaflow의 resume 명령을 사용하면 됩니다. 이렇게 하면 이전 단계의 모든 관련 출력물을 로드하여 이전 작업을 다시 실행하는 데 시간을 낭비하지 않습니다. Prefect를 사용해보니 이것의 간편함을 이해하지 못했었는데, 똑같이 수행할 수 있는 쉬운 방법이 없다는 것을 알게 되었습니다.
골디락스 스텝 크기 찾기
한 걸음의 적당한 크기는 무엇일까요? 이론적으로는 전체 스크립트를 하나의 거대한 단일 단계로 채울 수 있지만, 이것은 권장되지 않습니다. 이 흐름 중 일부가 실패하면 전체 흐름을 다시 실행하지 않고 이어서 진행하기 어렵습니다.
반대로 스크립트를 100개의 작은 마이크로 단계로 나눠 놓는 것도 가능하지만, 이것 또한 권장되지 않습니다. 아티팩트를 저장하고 단계를 관리하는 것이 약간의 오버헤드를 초래하며, 100개의 단계가 실행 시간을 지배할 것입니다. 골디락스 스텝의 크기를 찾기 위해 Tuulos는 다음과 같이 말합니다:
초기에 내가 따른 스텝 구조는 다음과 같습니다:
- 데이터 확장
- 모델 훈련
- 모델 평가
- 모델 배포
데이터를 확장한 후, S3 버킷에 데이터를 업로드하고, 강화된 데이터를 모델 훈련 단계에서 모델 훈련을 위해 다운로드해야 했습니다. 그 이유는 두 가지입니다:
- 데이터 확장 단계는 로컬 노트북에서 이루어지는 반면, 훈련 단계는 클라우드의 GPU 인스턴스로 전송될 예정이었습니다.
- Metaflow의 아티팩트는 일반적으로 단계 간 데이터 전달에 사용되지만, TensorFlow Dataset 객체를 처리할 수 없어서 TFRecords로 변환한 후 S3에 업로드해야 했습니다.
이 업로드/다운로드 프로세스에 많은 시간이 걸렸습니다. 그래서 데이터 확장과 훈련 단계를 결합했습니다. 이렇게 하면 프로세스의 실행 시간과 복잡성이 줄어듭니다. 궁금하다면 GitHub 레포지토리에서 separated_augement_train 브랜치를 확인해보세요.
포인트
이 글에서는 객체 감지 프로젝트를 제작할 때 경험한 좋은 일과 나쁜 일에 대해 이야기했습니다. 간단히 정리하면 다음과 같습니다:
- MLOps로 가기 위해 일부 작업을 배워야 할 필요가 있습니다. 일부 기본적인 설정을 학습한 후에는 Python 데코레이터만 사용하여 AWS로 컴퓨팅 작업을 손쉽게 전송할 수 있습니다. 본 글에 첨부된 리포지토리는 AWS에서 GPU를 프로비저닝하는 방법을 다루고 있으니, 이를 꼼꼼히 학습하시기 바랍니다.
- 의존성 관리는 제작 단계에서 매우 중요합니다. requirements.txt 파일은 최소한의 필수 요소이며, Docker는 최고의 표준이며, Metaflow는 많은 프로젝트에서 사용할 수 있는 가운데 길이를 갖춘 방법을 제공합니다. 단, 이 프로젝트에서는 사용할 수 없습니다.
- Metaflow에서 쉬운 디버깅을 위해 아티팩트와 Jupyter 노트북을 사용합니다. 다시 실행을 피하기 위해 resume를 사용합니다.
- Metaflow 플로에 스크립트를 단계별로 분해할 때, 합리적인 크기의 단계로 분할하고, 가능한 한 작은 단계를 선택하는 것이 좋습니다. 그러나 오버헤드가 너무 크다면 단계를 결합하는 것을 두려워하지 마세요.
이 프로젝트를 계속 발전시키고 싶은 측면이 여전히 있습니다. 하나는 더 많은 종류의 식물에 대한 질병 감지를 할 수 있도록 데이터를 추가하는 것입니다. 또 다른 하나는 프로젝트에 프론트 엔드를 추가하고 사용자가 이미지를 업로드하고 필요에 따라 객체 감지를 받을 수 있도록 하는 것입니다. 이에는 Streamlit과 같은 라이브러리가 잘 작동할 것입니다. 마지막으로 최종 모델의 성능을 최첨단 수준으로 만들고 싶습니다. Metaflow는 동시에 여러 모델을 병렬로 학습시킬 수 있는 능력을 가지고 있어 이 목표를 달성하는 데 도움이 될 것입니다. 안타깝게도 이 작업에는 많은 컴퓨팅 자원과 비용이 필요하지만, 최첨단 모델을 만드는 데는 필수적입니다.
참고 자료
[1] C. Huyen, Introduction to Machine Learning Interviews (2021), 자체 출판
[2] V. Tuulos, Effective Data Science Infrastructure (2022), Manning Publications Co.