당신의 LLM이 항상 정답을 아는 친구에게 전화할 수 있다면 어떨까요?
LLM들은 인상적인 답변을 생성할 수 있지만, 그들의 지식은 시간이 멈춰있고 마지막 훈련을 받은 날짜를 넘어설 수 없습니다. 새로운 데이터로부터 다시 훈련시킬 수는 있지만 비용과 시간이 많이 소요됩니다. 파인튜닝? 그건 시험을 위해 강제 공부하는 것과 비슷한데요. 이는 새로운 지식이 기존 지식을 밀어내면서 치명적인 잊혀짐을 초래할 수 있습니다. 여기에 검색 보강 생성(Retrieval-Augmented Generation, RAG)이라는 기술이 등장합니다. RAG를 사용하면 당신의 LLM에게 정확한 답변을 제공하기 위해 필요한 누락된 지식을 제공할 수 있습니다.
목차
- 검색 보강 생성(RAG) 이해
- 간단한 RAG 파이프라인 구축
- 데이터 수집
- 검색 메커니즘 설정
- LLM과 회수된 정보 통합
- 결론
- 향후 개선 사항
검색 증가 생성 이해
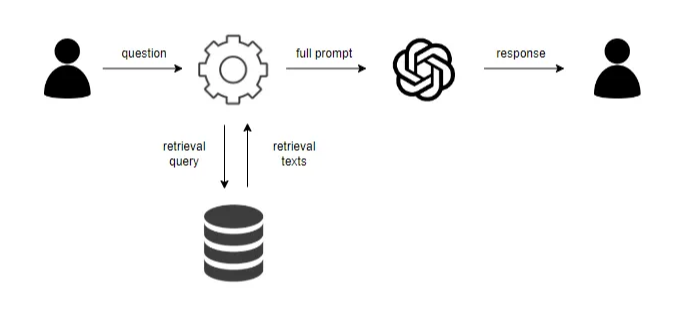
검색 증가 생성(Retrieval Augmented Generation, RAG)은 LLM(Large Language Models)의 능력을 향상시키는 기술로, 외부 정보에 액세스할 수 있게 함으로써 가능합니다. LLM이 이미 알고 있는 것에만 의존하는 대신(이는 오래되었거나 불완전할 수 있음), RAG는 모델이 "검색"추가 데이터를 찾아볼 수 있도록 합니다.
간단히 말하면, 질문을 하면, 시스템은 먼저 데이터베이스에서 관련 정보를 검색합니다. 이 정보는 그런 후 LLM의 자체 지식과 결합되어 더 정확한 응답을 생성합니다.
RAG의 주요 구성 요소
-
임베딩 모델 임베딩 모델은 데이터(예: 텍스트)를 숫자 벡터로 변환하여 내용의 의미론적 의미를 캡처합니다. 이를 통해 시스템은 사용자의 쿼리와 저장된 데이터 간 유사성을 측정하여 관련 정보를 찾고 비교할 수 있습니다.
-
벡터 데이터베이스 벡터 데이터베이스는 이러한 임베딩(데이터의 숫자적 표현)을 저장합니다. 쿼리를 제출하면 데이터베이스가 빠르게 해당 쿼리와 유사한 임베딩을 검색하여 가장 관련성 높은 정보를 검색합니다.
-
리트리버 리트리버는 벡터 데이터베이스를 검색하는 역할을 합니다. 사용자의 쿼리를 사용하여 가장 가까운 매칭 임베딩을 찾아 질문에 답할 수 있는 가장 관련성 있는 정보를 끌어냅니다.
-
LLM 관련 정보를 검색한 후, LLM은 해당 정보를 자체 내부 지식과 결합하여 응답 생성합니다. LLM은 검색된 데이터가 제공하는 컨텍스트를 활용하여 더 정확하고 정보를 가진 답변을 제공합니다.
간단한 RAG 파이프라인 구축
RAG의 기본 내용을 다룼었으니, 간단한 파이프라인을 구축해 보겠습니다. 데이터 준비부터 검색 시스템 설정 및 LLM과 통합까지 주요 단계를 설명하겠습니다. 최종적으로 정확하고 최신의 응답을 제공할 수 있는 기능적인 RAG 파이프라인을 보유하게 될 것입니다.
요구 사항
따라가기 위해 다음 사항이 필요합니다:
- Vector DB 인스턴스 (Milvus를 사용할 예정입니다)
- LLM 채팅 API (OpenAI를 사용할 예정입니다)
1. 데이터 적재
이 섹션에서는 PDF를 관리 가능한 청크로 분할하고 내장 모델을 사용하여 임베딩한 후 Milvus에 저장하는 방법을 보여드리겠습니다. 예시로 'Attention is all you need'를 사용하지만 LangChain에 사용 가능한 적절한 로더와 스플리터를 사용하여 .md, .doc 등과 같은 다른 파일 유형을 사용할 수 있습니다. 또는 기본 Python 논리를 사용하여 청크를 생성할 수도 있지만, 이 튜토리얼에서는 LangChain을 사용하겠습니다.
필요한 라이브러리를 가져오기
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Milvus
from langchain.embeddings import HuggingFaceEmbeddings
메모리에 임베딩 모델 로드하기
model_name = "sentence-transformers/all-mpnet-base-v2"
hf = HuggingFaceEmbeddings(model_name=model_name)
텍스트 데이터를 포함하기 위해서는 LangChain의 HuggingFaceEmbeddings 클래스를 사용할 것입니다. 이 튜토리얼에서는 sentence-transformers/all-mpnet-base-v2 모델을 사용하고 있습니다. 이 모델은 가벼우면서 품질 좋은 임베딩을 생성하는 데 적합합니다.
Milvus 자격 증명 정의하기
MILVUS_HOST = "10.192.111.152"
MILVUS_PORT = "19530"
MILVUS_COLLECTION = "basic_rag_collection"
MILVUS_DB = "basic_rag_db"
Milvus 인스턴스에 연결하기 위한 필요한 자격 증명을 정의합니다. 호스트, 포트, 컬렉션 이름 및 데이터베이스 이름이 포함됩니다. 이러한 정보는 Milvus에 문서 조각을 저장하고 관리하는 데 사용될 것입니다.
파일 로딩
loader = PyPDFDirectoryLoader(path)
docs = loader.load()
특정 디렉토리(path)에서 모든 PDF 파일을 로드하는 것으로 시작합니다. PyPDFDirectoryLoader는 디렉토리의 각 PDF 파일을 읽는 데 사용되며, loader.load()는 문서를 더 처리할 수 있는 객체 목록으로 반환합니다.
텍스트를 청크로 분할하기
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2048,
chunk_overlap=300,
length_function=len,
)
chunks = text_splitter.split_documents(docs)
문서를 로드한 후에는 처리와 검색을 쉽게하기 위해 더 작고 관리하기 쉬운 청크로 나눠야 합니다. 여기서는 RecursiveCharacterTextSplitter를 사용하여 문서를 2048자씩의 청크로 나누는데, 청크 간에 300자의 오버랩을 두었습니다. 이 오버랩은 각 청크 사이에 중요한 맥락이 유실되지 않도록 보장합니다. 두 값을 조정하여 사용자에게 가장 적합한 값을 찾을 수 있습니다.
Milvus에 청크 저장하기
Milvus.from_documents(
chunks,
hf,
collection_name=MILVUS_COLLECTION,
connection_args={"host": MILVUS_HOST, "port": MILVUS_PORT, "db_name": MILVUS_DB},
)
마지막으로, 우리는 Milvus에 청크를 저장하여 효율적인 벡터 기반 검색을 수행합니다. 우리는 Milvus.from_documents를 사용하여 앞에서 정의한 Milvus 컬렉션에 청크를 넣어줍니다. 청크와 임베딩 모델(hf)을 전달하며, connection_args는 Milvus 호스트, 포트 및 데이터베이스 이름을 지정하여 데이터가 올바른 위치에 저장되도록 합니다.
전체 삽입 기능은 아래와 같이 정의할 수 있습니다.
def ingest_files(path):
loader = PyPDFDirectoryLoader(path)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2048,
chunk_overlap=300,
length_function=len,
)
chunks = text_splitter.split_documents(docs)
Milvus.from_documents(
chunks,
hf,
collection_name=MILVUS_COLLECTION,
connection_args={"host": MILVUS_HOST, "port": MILVUS_PORT,"db_name":MILVUS_DB},
)
ingest_files('./pdfs')
2. 검색 메커니즘 설정
이 섹션에서는 주어진 쿼리를 기반으로 Milvus에서 관련 정보를 가져오는 검색 메커니즘을 설정할 것입니다.
vector_db = Milvus(
hf,
connection_args={"host": MILVUS_HOST, "port": MILVUS_PORT, "db_name": MILVUS_DB},
collection_name=MILVUS_COLLECTION,
)
우선, 문서 청크가 저장된 Milvus 컬렉션에 대한 연결을 초기화합니다.
def get_relevant_context(question, k=3):
retriever = vector_db.as_retriever(search_kwargs={"k": k})
context = retriever.invoke(question)
return context
그 다음으로, 사용자의 질문을 기반으로 가장 관련 있는 문서 조각을 검색하는 get_relevant_context 함수를 정의합니다.
질문과 함께 함수가 호출되면, 검색기는 Milvus 컬렉션에서 가장 관련 있는 조각을 찾습니다. invoke 메서드는 쿼리를 실행하고, 함수는 k개의 관련 조각을 반환합니다.
3. LLM과 검색된 정보 통합
이 섹션에서는 Milvus로부터 검색된 컨텍스트를 LLM과 결합하여 응답을 생성할 것입니다.
from openai import OpenAI
client = OpenAI(api_key="sk-zZ...agB")
첫 번째로, 언어 모델과 상호 작용하기 위해 API 키를 사용하여 OpenAI 클라이언트를 설정합니다.
def generate_prompt_template(context, question):
return f"""Context: {context}
Question: {question}
"""
다음으로는 사용자의 질문과 함께 검색한 콘텍스트를 서식화하여 LLM이 이해할 수 있는 프롬프트 템플릿으로 구성하는 generate_prompt_template 함수를 정의합니다.
SYSTEM_PROMPT = """도움이 되는 어시스턴트입니다. 일련의 맥락과 질문이 제공됩니다. 제시된 맥락을 사용하여 질문에 답하십시오.
주어진 맥락을 사용하여 질문에 답할 수 없는 경우에는 단순히 '주어진 맥락에 대한 답변이 없습니다.' 라고만 말하고 다른 내용은 말하지 말아야 합니다.
제공된 맥락에 정보가 없는 경우에는 답변을 만들 수 없거나 자신의 지식을 사용해서는 안 됩니다."""
SYSTEM_PROMPT은 LLM이 제공된 맥락을 엄격히 기반으로 답변하도록 안내하여 정확하고 맥락 중심의 응답을 보증합니다.
def llm(system_prompt, question, model):
context = get_relevant_context(question)
user_prompt = generate_prompt_template(context, question)
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
completion = client.chat.completions.create(
model=model,
messages=messages
)
response = completion.choices[0].message.content
return response
llm 함수는 먼저 Milvus로부터 관련 맥락을 검색하고 이를 user_prompt 템플릿에 추가하여 LLM에 전달합니다. LLM은 입력을 처리하고 응답을 생성한 후 반환합니다.
question = "인코더와 디코더에 대해 설명해줘"
llm_answer = llm(SYSTEM_PROMPT, question, 'gpt-4o')
마지막으로, 우리는 Milvus로부터 가져온 컨텍스트를 기반으로 LLM에게 질문을 하고 답변을 받습니다.

결론
이 튜토리얼에서는 검색 메커니즘과 LLM을 결합하여 정확하고 맥락 기반의 답변을 생성할 수 있는 시스템을 만들었습니다. 이러한 방식을 사용하면 저장된 문서에 효율적으로 접근하고 필요할 때 relevant한 정보를 얻을 수 있습니다. 이 설정은 복잡한 쿼리를 처리하고 AI 응답을 신뢰할 수 있고 실제 데이터에 기반하도록 유지하는 실용적인 방법을 제공합니다.
미래 향상
이 시스템은 견고한 기반을 제공합니다. 그러나 성장할 여지가 많습니다. 미래의 향상은 의미 캐싱, 프롬프트 라우팅, 의미적 라우팅, 평가, 재랭킹, HYDE 및 수정 RAG 등의 기능을 포함할 수 있습니다. 이러한 추가 기능 각각은 검색 증강 생성 프로세스의 효율성과 정확성을 더욱 향상시킬 수 있습니다. 이러한 고급 기술에 대해 후속 튜토리얼에서 자세히 살펴볼 예정이니 더 많은 정보를 기대해 주세요.