파이썬에서 가장 빠른 구현🐍

DBSCAN이란 무엇인가요? 파이썬에서는 어떻게 구현할까요? 이 주제를 다룬 많은 기사들이 있지만, 알고리즘 자체가 너무 간단하고 직관적이라서 그 아이디어를 단 5분 안에 설명할 수 있다고 생각합니다. 그러니 한번 해보도록 합시다.
무슨 의미인가요?
- 알고리즘은 물체 간의 공간적 거리를 기반으로 데이터 내부 클러스터를 탐색합니다.
- 알고리즘은 이상치(노이즈)를 식별할 수 있습니다.
그럼 DBSCAN이 왜 필요할까요???
- 새로운 특징 추출. 다루고 있는 데이터셋이 큰 경우, 데이터 내부의 명백한 클러스터를 찾고 각 클러스터를 따로 처리하는 것이 도움이 될 수 있습니다(다른 클러스터에 대해 각각의 모델을 훈련시킵니다).
- 데이터 압축. 종종 수백만 개의 행을 다뤄야하는데, 계산 비용이 많이 들고 시간이 많이 소요됩니다. 데이터를 클러스터링한 다음 각 클러스터에서 X%만 유지하는 것은 데이터 과학 영혼을 구원할 수 있습니다. 따라서 데이터셋 내부의 균형은 유지하면서 크기를 줄일 수 있습니다.
- 신규성 탐지. DBSCAN은 노이즈를 감지한다고 언급되었지만, 이 노이즈는 데이터셋의 이전에 알려지지 않은 특징일 수 있으며, 이를 보존하고 모델링에 사용할 수 있습니다.
그런 다음 이렇게 말씀하실 수 있습니다: 하지만, 우수하고 효과적인 k-means 알고리즘이 있잖아요.
네, 하지만 DBSCAN의 가장 달콤한 부분은 k-평균의 단점을 극복하며 클러스터 수를 지정할 필요가 없다는 것입니다. DBSCAN은 대신 클러스터를 감지해줍니다!
DBSCAN에는 사용자에 의해 정의된 두 가지 구성 요소가 있습니다: 인근성 또는 반경 (𝜀) 및 이웃의 수(N).
일부 객체로 구성된 데이터셋의 경우, 이 알고리즘은 다음 아이디어에 기반합니다:
- 핵심 객체. 객체는 거리 𝜀 내에서 적어도 N개의 다른 객체를 가지고 있으면 핵심 객체라고합니다.
- 핵심 포인트의 𝜀-인근에 위치한 비-핵심 객체는 테두리 객체라고합니다.
- 핵심 객체는 인근의 모든 핵심 및 테두리 객체와 클러스터를 형성합니다.
- 객체가 핵심도 테두리도 아닌 경우 잡음 (이상치)이라고합니다. 그것은 어떤 클러스터에도 속해 있지 않습니다.
DBSCAN을 구현하려면 거리 함수를 생성해야 합니다. 이 글에서는 유클리드 거리를 사용할 것입니다:
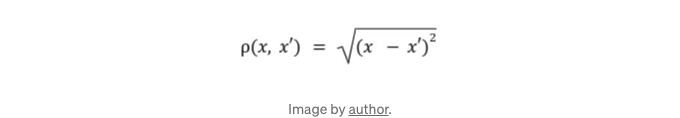
우리 알고리즘을 위한 의사코드는 다음과 같습니다:

거리 함수부터 시작해봅시다:
def distances(object, data):
euclidean = []
for row in data: # 데이터 세트의 모든 객체를 반복
d = 0
for i in range(data.shape[1]): # 모든 좌표의 제곱 잔차 합계 계산
d += (row[i] - object[i])**2
euclidean.append(d**0.5) # 제곱근 취하기
return np.array(euclidean)
이제 알고리즘의 본문을 만들어 봅시다:
def DBSCAN(data, epsilon=0.5, N=3):
visited, noise = [], [] # 방문한 점과 이상점을 수집하는 리스트
clusters = [] # 클러스터를 수집하는 리스트
for i in range(data.shape[0]): # 모든 점을 반복
if i not in visited: # 방문하지 않은 경우에 들어갑니다
visited.append(i)
d = distances(data[i], data) # 다른 모든 점으로부터의 거리 가져오기
neighbors = list(np.where((d <= epsilon) & (d != 0))[0]) # 입실론 주변의 이웃 목록 가져오기 및 거리 = 0(본인) 제거
if len(neighbors) < N: # 객체 수가 N보다 작으면 이상점입니다
noise.append(i)
else:
cluster = [i] # 그렇지 않으면 새 클러스터 형성
for neighbor in neighbors: # 점 i의 모든 이웃을 반복
if neighbor not in visited: # 이웃을 방문하지 않은 경우
visited.append(neighbor)
d = distances(data[neighbor], data) # 이웃으로부터의 다른 객체로의 거리 가져오기
neighbors_idx = list(np.where((d <= epsilon) & (d != 0))[0]) # 이웃의 이웃 가져오기
if len(neighbors_idx) >= N: # 이웃이 N개 이상의 이웃을 가지고 있으면 코어 포인트입니다
neighbors += neighbors_idx # 이웃의 이웃을 i번째 객체의 이웃에 추가합니다.
if not any(neighbor in cluster for cluster in clusters):
cluster.append(neighbor) # 이웃이 클러스터에 없으면 추가합니다.
clusters.append(cluster) # 클러스터를 클러스터 리스트에 넣습니다.
return clusters, noise
완료!
우리의 구현물의 정확성을 확인하고 sklearn과 비교해봅시다.
일부 합성 데이터를 생성해 봅시다:
X1 = [[x,y] for x, y in zip(np.random.normal(6,1, 2000), np.random.normal(0,0.5, 2000))]
X2 = [[x,y] for x, y in zip(np.random.normal(10,2, 2000), np.random.normal(6,1, 2000))]
X3 = [[x,y] for x, y in zip(np.random.normal(-2,1, 2000), np.random.normal(4,2.5, 2000))]
fig, ax = plt.subplots()
ax.scatter([x[0] for x in X1], [y[1] for y in X1], s=40, c='#00b8ff', edgecolors='#133e7c', linewidth=0.5, alpha=0.8)
ax.scatter([x[0] for x in X2], [y[1] for y in X2], s=40, c='#00ff9f', edgecolors='#0abdc6', linewidth=0.5, alpha=0.8)
ax.scatter([x[0] for x in X3], [y[1] for y in X3], s=40, c='#d600ff', edgecolors='#ea00d9', linewidth=0.5, alpha=0.8)
ax.spines[['right', 'top', 'bottom', 'left']].set_visible(False)
ax.set_xticks([])
ax.set_yticks([])
ax.set_facecolor('black')
ax.patch.set_alpha(0.7)
아래는 마크다운 형식의 코드입니다.

Implement and visualize the results as follows:

We obtained the same clusters using the sklearn implementation:

그렇죠, 둘이 완전 똑같죠요. 5분이면 끝이에요! DBSCAN을 직접 해보실 때는 epsilon과 이웃의 수를 조절하는 것을 잊지 말아주세요. 이 두 가지가 최종 결과에 큰 영향을 미치거든요.
===========================================
참고:
[1] 에스터, 엠., 크리겔, 에이치.피., 산더, 제이., & 쉬, 엑스. (1996년 8월). 소음과 함께하는 응용 프로그램의 밀도 기반 공간 클러스터링. 지식 발견과 데이터 마이닝 국제 학회 (Vol. 240, №6).
[2] 양양 등. "반대 기반 학습을 활용한 산술 최적화 알고리즘에 의해 최적화된 효율적인 DBSCAN." 초고속 컴퓨팅 학술지 78.18 (2022): 19566-19604.
===========================================
제가 Medium에 게시한 모든 출판물은 무료이며 공개 접근이 가능합니다. 그래서 여기서 저를 팔로우해 주시면 정말 감사하겠습니다!
P.s. 저는 (지오)데이터 과학, 기계 학습/인공 지능 및 기후 변화에 대해 열정적입니다. 따라서 어떤 프로젝트에서 함께 일하고 싶다면 LinkedIn에서 저에게 연락해주세요.
🛰️더 많은 정보를 원하시면 팔로우해주세요🛰️