
소개
요즘 쿠버네티스에서 담당하고 있는 작업 중 하나는 교차 AZ 트래픽을 분석하여 AWS 청구서에 상당한 기여를 하는 부분을 식별하는 것이었습니다. 첫 번째 단계는 서비스 간에 트래픽이 어떻게 흐르는지 이해하고 일관되게 가용 영역 (AZs)을 가로질러 이동하는 부분을 파악하는 것이었습니다. 교차 AZ 트래픽을 최적화하기 위해 서비스에 대한 토폴로지 인식 라우팅을 사용할 가능성을 고려했습니다. 그러나 이 해결책을 구현하기 전에 AZ 수준에서 상호 포드 트래픽을 효과적으로 분석하는 방법이 필요했습니다.
이를 위해 포드 수준에서 네트워크 트래픽을 모니터링하는 것이 필요했습니다. 성능 부담이 적은 네트워크 상호 작용을 관찰할 수 있도록 eBPF(확장된 버클리 패킷 필터) 기술을 사용하기로 결정했습니다.
이 기사에서는 eBPF가 무엇인지 설명하고, 그를 사용하는 도구를 탐색하며, Retina, Kube State Metrics, Prometheus 및 Grafana를 사용하여 인터팟 트래픽 모니터링을 구현하는 단계별 안내서를 제공하겠습니다.
eBPF가 무엇인가요?
확장된 버클리 패킷 필터(eBPF)는 리눅스 커널에 내장된 강력하고 유연한 기술로, 개발자가 커널 공간 내에서 안전하고 효율적으로 사용자 정의 프로그램을 실행할 수 있도록 합니다. 패킷 필터링을 위해 설계된 eBPF는 모니터링, 추적, 프로파일링 및 응용 프로그램 안전 설정을 위한 다양한 기능을 제공하도록 발전했습니다.
쿠버네티스 환경에서 eBPF는 특히 인터팟 트래픽 모니터링에 유용합니다. 전통적이고 더 침입적일 수 있는 패킷 스니핑이나 응용 프로그램 수준 로깅과 같은 방법에 의존하지 않고 네트워크 동작에 대한 자세한 통찰력을 제공합니다. eBPF는 각각의 통신 패턴에 대한 전체적인 보기를 제공하여 팟으로 들어오고 나가는 모든 네트워크 패킷을 관찰할 수 있습니다.
Microsoft Retina란 무엇인가요?
Retina는 Kubernetes 환경을 위해 특별히 설계된 고급 네트워크 관측 도구입니다. eBPF의 기능을 활용하도록 구축된 Retina는 Kubernetes 클러스터 내에서 특히 교차-AZ 통신에 중점을 둔 포드 수준의 네트워크 트래픽과 상호 작용에 대한 깊은 통찰력을 제공합니다.
전체 클러스터에 대한 메트릭을 생성하지 않고도 Retina를 사용하여 이름 공간 또는 포드 수준에서 모니터링할 수 있어 구성이 쉽다는 점을 이유로 다른 네트워크 관측 도구에 비해 Retina를 선택하였습니다.
구현
우리의 목표를 달성하기 위해 다음 단계가 필요합니다:
- 감시를 위해 두 개의 서비스를 배포합니다: 서버: Pod의 가용 영역(AZ)을 응답으로 반환하는 단일 엔드포인트가 있는 간단한 Flask API입니다. 클라이언트: 이 서비스는 계속해서 서버의 엔드포인트로 요청을 보내고 자체 AZ를 서버의 응답과 함께 기록합니다. 이것은 단지 로깅 및 초기 테스트를 위해 교차 AZ 트래픽의 의미 있는 트래픽을 생성하기 위한 것입니다.
- Helm 차트를 통해 Retina를 설치하고 구성합니다.
- Prometheus를 구성하여 Retina에서 메트릭을 수집합니다.
- 메트릭을 분석하기 위한 Grafana 대시보드를 생성합니다.
서비스 배포
두 가지 간단한 서비스를 서로 다른 네임스페이스로 배포합니다. 소스 코드와 Kubernetes 매니페스트는 여기에서 찾을 수 있습니다. 결과적으로 우리는 다음을 갖게 될 것입니다:
- 서버 앱의 6개의 팟이 app-server 네임스페이스에 배포되었으며 서로 다른 가용 영역에 퍼져 있습니다. 이러한 팟들은 ClusterIP 유형의 Kubernetes 서비스를 사용하여 노출됩니다.
- 클라이언트 앱의 10개의 팟이 app-client 네임스페이스에 배포되었으며 서로 다른 가용 영역에 분산되어 있습니다.
두 네임스페이스는 네트워크 트래픽을 모니터링하기 위해 Retina를 활성화하기 위해 retina.sh=observe로 주석 처리되어 있습니다.
Retina 설치 및 구성
Retina를 설치하기 위해 공식 Helm 차트를 사용할 것입니다. 이 설정에서는 packetparser와 packetforward 두 개의 플러그인만 설치할 것입니다.
다음으로 MetricsConfiguration CRD를 설치해야 합니다.
apiVersion: retina.sh/v1alpha1
kind: MetricsConfiguration
metadata:
name: metricsconfigcrd
spec:
contextOptions:
- metricName: drop_count
sourceLabels:
- ip
- podname
- port
additionalLabels:
- direction
- metricName: forward_count
sourceLabels:
- ip
- podname
- port
destinationLabels:
- ip
- podname
- port
additionalLabels:
- direction
namespaces:
include:
- app-server
- app-client
Prometheus 구성하기
이 설정의 마지막 단계로, 프로메테우스를 구성하여 Retina에서 이러한 지표를 수집하도록 설정해야 합니다. Retina 문서에 따르면, 다음 스크랩 구성이 프로메테우스에 추가되어야 합니다:
- job_name: "retina-pods"
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_container_name]
action: keep
regex: retina(.*)
- source_labels:
[__address__, __meta_kubernetes_pod_annotation_prometheus_io_port]
separator: ":"
regex: ([^:]+)(?::\d+)?
target_label: __address__
replacement: ${1}:${2}
action: replace
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: instance
metric_relabel_configs:
- source_labels: [__name__]
action: keep
regex: (.*)
결과와 분석
구성이 완료되면, 메트릭은 프로메테우스에서 다음과 같이 사용할 수 있습니다:
| 예시 | 설명 |
|---|---|
| retina | networkobservability_adv_forward_bytes 메트릭 |
| podname, namespace, workload_kind | 출발지 및 목적지 팟을 식별하기 위한 레이블 |
| direction | 목적지 팟 관점에서의 트래픽 방향을 나타내는 레이블 |
이 팟들의 가용 영역을 결정하려면 먼저 노드를 식별하고 노드의 가용 영역을 찾아야 합니다. 모든 노드에는 topology.kubernetes.io/zone 레이블이 지정되어 있으므로 Kubernetes 상태 메트릭인 kube_pod_info 및 kube_node_labels을 사용할 수 있습니다.
이 모든 정보를 사용하여 다음과 같은 PromQL 쿼리를 작성할 수 있습니다:
sum(
ceil(
(
sum(
rate(networkobservability_adv_forward_bytes{
source_namespace="app-client",
source_workload_name=~"client-(.*)",
destination_namespace="app-server",
destination_workload_name=~"server-(.*)"
}[$__rate_interval])
* on (source_podname) group_left(source_node)
label_replace(
label_replace(kube_pod_info{
namespace="app-client",
created_by_name=~"client-(.*)"
}, "source_podname", "$1", "pod", "(.*)"),
"source_node", "$1", "node", "(.*)"
)
* on (source_node) group_left(zone)
label_replace(
label_replace(
sum by (node, label_topology_kubernetes_io_zone) (kube_node_labels),
"source_node", "$1", "node", "(.*)"
),
"zone", "$1", "label_topology_kubernetes_io_zone", "(.*)"
)
) by (destination_podname, source_podname, zone)
+ on (destination_podname, source_podname, zone) group_left()
(
sum(
rate(networkobservability_adv_forward_bytes{
source_namespace="app-client",
source_workload_name=~"client-(.*)",
destination_namespace="app-server",
destination_workload_name=~"server-(.*)"
}[$__rate_interval])
* on (destination_podname) group_left(destination_node)
label_replace(
label_replace(kube_pod_info{
namespace="app-server",
created_by_name=~"server-(.*)"
}, "destination_podname", "$1", "pod", "(.*)"),
"destination_node", "$1", "node", "(.*)"
)
* on (destination_node) group_left(zone)
label_replace(
label_replace(
sum by (node, label_topology_kubernetes_io_zone) (kube_node_labels),
"destination_node", "$1", "node", "(.*)"
),
"zone", "$1", "label_topology_kubernetes_io_zone", "(.*)"
)
) by (destination_podname, source_podname, zone)
)
) / 2
)
여기에서는 이러한 워크로드 간에 흐르는 트래픽 양을 가져오는 중이며, 트래픽 속도를 집계하고 pod를 노드와 존에 매핑한 다음 소스와 대상의 값에 대한 평균을 계산합니다. on() 함수를 사용하여 소스와 대상 존의 교차점을 찾아 동일한 AZ 트래픽을 나타냅니다.
명백히, 이 쿼리에 포함되지 않는 바이트 남은 양은 교차 AZ 트래픽으로 간주됩니다.
다음과 같은 Grafana 대시보드를 만들어 이 트래픽을 다양한 관점에서 분석했습니다:
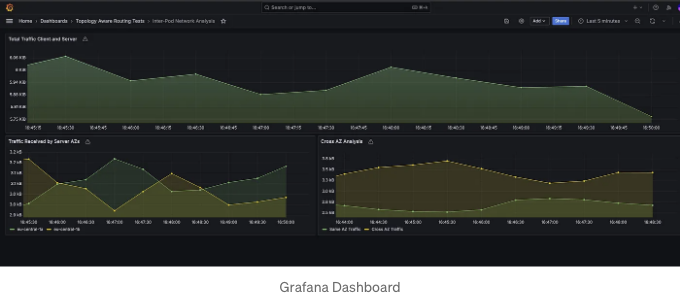
제 GitHub 저장소에서 관련된 모든 코드를 찾을 수 있어요.
요약
이 글에서는 쿠버네티스에서 인터파드 트래픽을 분석하는 방법을 살펴보았어요. 특히 교차 AZ 통신과 AWS 비용에 미치는 영향을 중점적으로 다뤘어요. 효율적인 네트워크 모니터링을 위해 eBPF 기술을 활용하고 Retina, Prometheus, Grafana와 같은 도구들을 활용했어요. 이 안내서는 이러한 도구들의 설정과 구성 방법을 다뤘고 트래픽 메트릭을 캡처하고 분석하는 방법을 설명했어요. 샘플 환경을 배포하고 수집된 데이터를 분석함으로써 트래픽 패턴을 파악하고 교차 AZ 통신을 최적화하며 쿠버네티스 클러스터에서의 네트워크 성능을 효율적으로 관리하는 방법을 시연했어요.
참고 자료
- eBPF란 무엇인가요?
- Topology Aware Routing
- [영상] Retina: Kubernetes를 위한 eBPF 분산 네트워킹 감시 도구
- Retina 소개
- Kubernetes 객체 상태 지표