
지난 기사에서는 SQL 사용자 정의 함수에 대해 이야기했습니다. 그러나 SQL과 비교했을 때, Python은 함수 디자인에서의 다양성으로 더욱 빛을 발합니다. 기술 회사에서 일한 경험을 토대로, 데이터 과학 프로젝트는 Python 함수를 광범위하게 활용하지 않으면 완성되지 않는다는 사실이 분명합니다. Python은 데이터 과학자가 데이터를 효율적으로 관리하고 분석하며 복잡한 작업을 처리하고 제품 기능을 배포하는 데 필수적인 도구가 되었습니다. 핵심으로 포함된 다양한 함수 범위로 인해 Python은 데이터 과학 분야에서 강력한 도구임이 입증되었습니다. 그러나 다양한 종류의 함수가 있기 때문에, 데이터 과학자가 그 모든 함수에 익숙해지는 것은 어렵고 불가능합니다. 오늘의 기사에서는 현실 세계 데이터 과학에서 흔히 사용되는 상위 8가지 유형의 함수를 다루며, 다른 자습서에서 거의 다루지 않는 그들의 복잡한 논리와 메커니즘을 설명할 것입니다. 또한 종종 서로 혼동되는 다른 유형의 함수 사이의 혼란을 해소할 것입니다. 마지막으로, 미니 프로젝트를 통해 이러한 함수 중 몇 가지를 실제로 효과적으로 적용하는 방법을 시연할 것입니다.
Python의 상위 8가지 함수 유형
1. 내장 함수
내장 함수는 미리 정의된 Python 함수로, 데이터 구조 생성, 유형 변환 및 수학적 계산과 같은 일반적인 작업을 수행합니다. 수학 연산, 유형 변환, 시퀀스/반복자, 입출력 및 객체 내부 검사를 위한 가장 자주 사용되는 내장 함수들이 있습니다.
1.1 수학 함수
수학 함수는 수학적 연산을 수행합니다.
import math
numbers = [1, 2, 3, 4, 5]
total = sum(numbers)
average = sum(numbers) / len(numbers)
maximum = max(numbers)
minimum = min(numbers)
absolute = abs(-10)
rounded = round(3.14159, 2)
square_root = math.sqrt(16)
1.2 타입 변환 함수
타입 변환 함수는 서로 다른 데이터 유형 간에 변환을 수행합니다.
number_string = "123"
float_number = "3.14"
integer = int(number_string)
float_value = float(float_number)
string_value = str(integer)
boolean_value = bool(integer)
1.3 시퀀스/반복자 함수
시퀀스/반복자 함수는 시퀀스와 반복자와 함께 작동합니다.
numbers = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x**2, numbers))
evens = list(filter(lambda x: x % 2 == 0, numbers))
enumerated = list(enumerate(numbers))
zipped = list(zip(numbers, squared))
print(f"Squared: {squared}")
print(f"Evens: {evens}")
print(f"Enumerated: {enumerated}")
print(f"Zipped: {zipped}")
1.4 입력/출력 함수
입력/출력 함수는 입력 및 출력 작업을 다룹니다.
name = input("이름을 입력하세요: ")
print(f"안녕하세요, {name}님!")
with open("example.txt", "w") as f:
print("이것은 텍스트 한 줄입니다.", file=f)
with open("example.txt", "r") as f:
content = f.read()
print(f"파일 내용: {content}")
1.5 객체 내부 조사 함수
객체 내부 조사 함수는 런타임에 객체의 속성을 검사합니다.
class ExampleClass:
def example_method(self):
pass
obj = ExampleClass()
print(f"obj의 타입: {type(obj)}")
print(f"obj의 속성: {dir(obj)}")
print(f"obj가 ExampleClass의 인스턴스인가요? {isinstance(obj, ExampleClass)}")
print(f"obj가 example_method를 가지고 있나요? {hasattr(obj, 'example_method')}")
내장 함수는 효율적입니다. 왜냐하면 사용하기 쉽고 파이썬 코드 전체에서 표준화되어 있기 때문이에요. 새로운 사용자들은 가져온 함수와 내장 함수를 혼동할 수 있어요. 왜냐하면 둘 다 미리 정의되어 있고 비슷한 목적을 가지고 있기 때문이죠. 하지만 가져온 함수 또는 라이브러리 함수는 Numpy, Pandas 또는 Scikit-learn과 같은 외부 라이브러리의 일부입니다. 이러한 함수들은 데이터 과학과 머신 러닝 워크플로우에서 필수적인 도구들이지만, 이러한 외부 라이브러리를 가져온 후에만 사용할 수 있어요.
2. 사용자 정의 함수
사용자 정의 함수(UDFs)는 개발자가 특정 로직/작업을 구현하거나 복잡한 작업을 처리하거나 프로젝트의 다른 부분에서 코드를 재사용하기 위해 만든 사용자 지정 함수들이에요.
Python UDFs는 개발자들에게 5가지 큰 혜택을 제공해요:
코드 가독성: 스크립트는 반복되거나 복잡한 코드가 함수로 캡슐화된 후 더 깔끔하고 읽기 쉬워질 수 있습니다.
디버깅: UDF(사용자 정의 함수)는 개별적으로 테스트하고 디버깅할 수 있습니다. 이 기능은 데이터 처리 파이프라인의 버그를 식별하고 수정하기 쉽게 만듭니다.
확장성: 잘 설계된 UDF(사용자 정의 함수)는 프로젝트가 성장할 때 코드베이스를 확장하고 보다 관리하기 쉽게 만들어줍니다.
협업: 모듈화된 함수는 팀원들이 큰 프로젝트의 각 부분에 집중하면서 함께 작업할 수 있게 합니다.
최적화: 모듈화된 함수는 전체 코드베이스를 완전히 변경하지 않고 고립된 특정 함수에 최적화를 적용하여 모델 업그레이드 및 반복을 변경합니다.
간단한 UDF 예제는 다음과 같습니다:
def add(a, b):
return a + b
def various_types(x):
if x < 0:
return "Hello!"
else:
return 0
print(various_types(1))
print(various_types(-1))
두 번째 예시를 통해 알 수 있듯이 Python은 SQL과 같은 다른 프로그래밍 언어와 달리 함수의 반환 유형을 명시적으로 선언할 필요가 없다. Python 함수는 return 키워드를 통해 어떤 유형의 값이든 반환할 수 있습니다.
보다 넓은 의미에서 클로저 함수와 같은 일부 함수는 UDF로 분류될 수도 있습니다. 그러나 그들만의 독특한 구조와 사용 사례 때문에, 나중에 별도로 다루겠습니다.
3. 람다 함수
람다 함수는 람다 키워드를 사용하여 정의된 작고 익명의 함수입니다. return 키워드를 작성할 필요가 없으며, : 다음에 오는 표현식이 자동으로 반환됩니다.
람다 함수는 간결하고 짧은 작업에 이상적입니다. 함수(sorted, filter 및 map과 함께 자주 사용됩니다.
data = [1, 2, 3, 4, 5]
squared = list(map(lambda x: x**2, data))
print(f"Squared: {squared}")
4. 고차 함수
고차 함수는 다른 함수를 인수로 받거나 함수를 반환합니다. 함수 합성, 콜백 및 데코레이터를 구현할 수 있어 코드의 유연성과 재사용성을 높일 수 있습니다.
여기 한 가지 고차 함수의 예시가 있어요:
def apply_function(func, value):
return func(value)
def square(x):
return x * x
result = apply_function(square, 5) # 'square' 함수를 인자로 넘겨 호출합니다
print(result) # 출력: 25
고차 함수와 중첩 함수를 혼동하기 쉬운데, 외관상 비슷하게 보일 수 있어요. 하지만 두 가지 사이에는 중요한 차이점이 있어요. 고차 함수는 함수를 인자로 받거나 반환할 수 있는 능력으로 정의되는 반면, 중첩 함수는 다른 함수 내에 위치함으로써 정의돼요.
두 종류의 함수 간의 차이를 설명하기 위해 중첩 함수의 예시를 사용할게요:
def outer_function(a, b):
def inner_function(c):
return c * 2
return inner_function(a) + inner_function(b)
result = outer_function(3, 5)
print(result) # Output will be 16
이 예제에서 inner_function은 nested function입니다. 왜냐하면 outer_function 내부에서 정의되었기 때문입니다. 또한 higher-order function 예제에서 apply_function은 다른 함수(square)를 인자로 사용하기 때문에 higher-order function입니다. 그러나 higher-order function은 중첩된 함수를 포함할 수 있습니다. 이러한 차이에도 불구하고 중첩된 함수에 따른 고차 함수가 존재할 수 있습니다.
5. Generator Functions
Generator functions은 yield 키워드를 사용하여 반복자를 반환합니다. 단일 값을 반환하고 실행을 중단하는 대신, 값 생성을 일시 중단하고 요청 시 어디서 그대로 다시 시작합니다. 이를 통해 한 번에 모든 값을 반환하는 대신 한 번에 한 번씩 값의 시퀀스를 생성할 수 있습니다.
생성자 함수는 다음과 같이 피보나치 숫자의 시퀀스를 생성할 수 있습니다:
def fibonacci(n):
a, b = 0, 1
for _ in range(n):
yield a
a, b = b, a + b
fib_seq = list(fibonacci(10))
print(f"Fibonacci sequence: {fib_seq}")
동일한 결과를 return 및 for 루프를 사용하는 함수로도 얻을 수 있습니다. 그러나 함수는 즉시 종료되어 단일 값이 반환됩니다. 효율성을 희생하여 전체 시퀀스를 메모리에 저장해야 합니다.
이후, 생성자 함수는 매우 메모리 효율적이며 특히 큰 시퀀스를 생성하는 데 유용합니다. 많은 성능 향상과 파이프라인 처리에 적합한 지원으로 인해, 생성자 함수는 데이터 스트리밍 및 일괄 처리에 모두 사용할 수 있습니다. 뿐만 아니라, 생성자는 이미지 처리 및 딥러닝에서 무작위 변환을 적용하는 데 자주 사용됩니다. 게으른 데이터로딩 기능 덕분에, 생성자는 대규모 데이터셋이나 전처리가 계산적으로 비싼 경우에 유용합니다.
6. 재귀 함수
재귀 함수는 자신을 호출하여 문제를 해결하는 함수입니다. 이 유형의 함수는 종종 자연스럽게 재귀적인 구조를 갖는 알고리즘에 사용됩니다. 예를 들어, 팩토리얼을 계산할 수 있습니다.
def factorial(n):
if n == 0 or n == 1:
return 1
else:
return n * factorial(n-1)
람다 표현식을 사용하여 팩토리얼 함수를 구현할 수도 있습니다:
factorial = lambda n: 1 if n == 0 else n*factorial(n-1)
7. 장식자 함수
장식자 함수는 다른 함수의 동작을 수정하거나 개선하는 데 사용됩니다. 장식자는 코드의 재사용성을 높이고 관심사를 분리하여 복잡한 동작을 모듈식 및 조립 가능한 방식으로 구축하며 소스 코드에 직접 액세스하지 않고 수정할 수 있도록 합니다. 따라서 장식자는 주로 로깅, 시간 측정/프로파일링, 접근 제어/인가, 메모리제이션/캐시, 유효성 검사 및 재시도 로직에 사용됩니다.
다음 스크립트는 함수 실행 시간을 측정하는 장식자 함수를 사용하는 방법을 보여줍니다. 이는 코드를 최적화하는 데 도움이 됩니다.
import time
def timer(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"{func.__name__} took {end_time - start_time:.2f} seconds to execute")
return result
return wrapper
@timer
def slow_function():
time.sleep(2)
slow_function()
위 스크립트는 slow_function()의 실행 시간을 다음과 같이 출력합니다: ‘slow_function took 2.01 seconds to execute’.
8. 클로저 함수
클로저 함수는 외부 함수 내에 정의되고, 외부 함수의 변수에 액세스 할 수 있는 함수를 나타냅니다. 이를 통해 외부 함수의 실행이 완료된 후에도 변수에 접근할 수 있습니다. 클로저 함수는 함수 팩토리, 콜백 및 이벤트 핸들러, 데코레이터 및 상태 객체를 만드는 데 유용합니다. 다음은 곱셈기능을 생성하는 클로저 함수의 예시입니다:
def multiplier(factor):
def multiply_by(x):
return x * factor
return multiply_by
# Create a function that multiplies by 3
times_three = multiplier(3)
# Create a function that multiplies by 5
times_five = multiplier(5)
# Use the closure functions
print(times_three(10)) # Output: 30
print(times_five(10)) # Output: 50
새로 오신 분들은 종종 클로저 함수와 중첩 함수를 혼동하는 경우가 있습니다. 이는 둘 다 함수를 다른 함수 내부에서 정의하는 것을 포함하지만 내부 함수가 외부 함수의 변수와 매개변수에 액세스할 수 있다는 점에서 유사합니다. 그러나 핵심적인 차이점은 클로저 내부 함수가 외부 함수가 실행을 완료한 후에도 그 주변 환경의 상태를 기억하는 반면 중첩 함수는 외부 함수의 변수 상태를 보존하지 않습니다. 이러한 상태 보존의 차이로 두 유형의 함수의 사용 방식이 결정됩니다.
클로저 함수와 재귀 함수는 기본적인 논리적 유사성을 갖고 있지만, 인수로 전달되거나 다른 함수에 의해 반환되거나 변수에 할당되는 등의 공통점이 있습니다. 재귀 함수는 상태를 유지하는 클로저 함수와 달리 문제 크기를 반복적으로 줄여가며 기본 사례에 도달할 때까지 작동합니다. 한편 클로저 함수는 반복적인 자체 호출을 필요로 하지 않습니다.
미니 머신러닝 프로젝트
이번 데모에서는 UCI Machine Learning Repository의 Wine Quality 데이터세트를 사용할 것입니다. 정보 페이지는 여기에서 확인하거나 데이터세트를 바로 다운로드하실 수 있습니다.
해당 데이터세트는 크리에이티브 커먼즈 저작자표시 4.0 국제(CC BY 4.0) 라이선스로 배포되어 있어, 적절한 크레딧이 표시된다면 어떤 목적으로든 공유하고 수정할 수 있습니다.
Wine Quality 데이터세트에는 와인의 11가지 화학적 특성과 0(매우 나쁨)부터 10(훌륭함)까지의 품질 점수가 포함되어 있습니다. 회귀 문제로 다루기 때문에, 와인 품질을 예측하기 위해 랜덤 포레스트 회귀기(Random Forest Regressor) 모델을 학습할 것입니다.
우선 필요한 모든 라이브러리를 불러오겠습니다.
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error, r2_score import requests from io import StringIO
다음으로, 세 가지 파이썬 사용자 정의 함수를 만들겠습니다. 첫 번째 함수는 Wine Quality 데이터셋을 다운로드하고 로드할 것입니다. 두 번째 함수는 모든 변수의 기본 통계량을 계산할 것입니다. 마지막 함수는 기존 특성에서 2개의 새로운 특성을 만들 것입니다.
사용자 정의 함수
def load_wine_data(url): """주어진 URL에서 와인 데이터를 다운로드하고 로드합니다.""" response = requests.get(url) data = StringIO(response.text) df = pd.read_csv(data, sep=';') return df
def calculate_stats(df, columns): """지정된 열의 기본 통계량을 계산합니다.""" stats = {} for col in columns: stats[col] = { '평균': np.mean(df[col]), '중앙값': np.median(df[col]), '표준편차': np.std(df[col]) } return stats
def engineer_features(df): """기존 특성에서 새로운 특성을 생성합니다.""" df['총 산도'] = df['고정 산도'] + df['휘발성 산도'] df['당도 대 산도 비율'] = df['잔류 설탕'] / df['총 산도'] return df
그런 다음, 변환을 적용하여 고차 함수를 생성할 것입니다.
# 변환을 적용하는 고차 함수
def apply_transformations(df, transformations):
for column, transform_func in transformations.items():
df[column] = df[column].apply(transform_func)
return df
마지막으로, 사용자 정의 함수와 고차 함수를 포함한 모든 함수들을 통합하고, 모델 훈련 및 예측 과정을 구현할 것입니다.
고차 함수는 다른 함수(들)을 인자로 받거나 함수를 반환할 수 있기 때문에, 이 예시에서는 apply_transformations 함수가 람다 표현식을 사용하여 정의된 transform_func라는 다른 함수를 사용합니다.
# 주요 워크플로우
def main():
# 데이터 로드
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-red.csv"
df = load_wine_data(url)
# 데이터 클리닝 (내장 함수 사용)
df = df.dropna()
# 피쳐 엔지니어링
df = engineer_features(df)
# 람다 함수를 사용하여 변환 적용
transformations = {
'alcohol': lambda x: x / 100, # 십진수로 변환
'pH': lambda x: 10**(-x) # pH를 수소 이온 농도로 변환
}
df = apply_transformations(df, transformations)
# 숫자형 열에 대한 통계량 계산
numeric_columns = df.select_dtypes(include=[np.number]).columns
stats = calculate_stats(df, numeric_columns)
print("기본 통계:")
print(pd.DataFrame(stats))
# 피쳐와 타겟 준비
X = df.drop('quality', axis=1)
y = df['quality']
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 피쳐 스케일링
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# 모델 학습
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train_scaled, y_train)
# 예측
y_pred = model.predict(X_test_scaled)
# 메트릭스 계산
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f"\n평균 제곱 오차: {mse:.4f}")
print(f"R-squared 점수: {r2:.4f}")
# 피쳐 중요도 출력 (람다 함수 사용)
feature_importances = sorted(
zip(model.feature_importances_, X.columns),
key=lambda x: x[0],
reverse=True
)
print("\n상위 5개 피쳐 중요도:")
for importance, feature in feature_importances[:5]:
print(f"{feature}: {importance:.4f}")
# 주요 워크플로우 호출
if __name__ == "__main__":
main()
최종 결과물은:
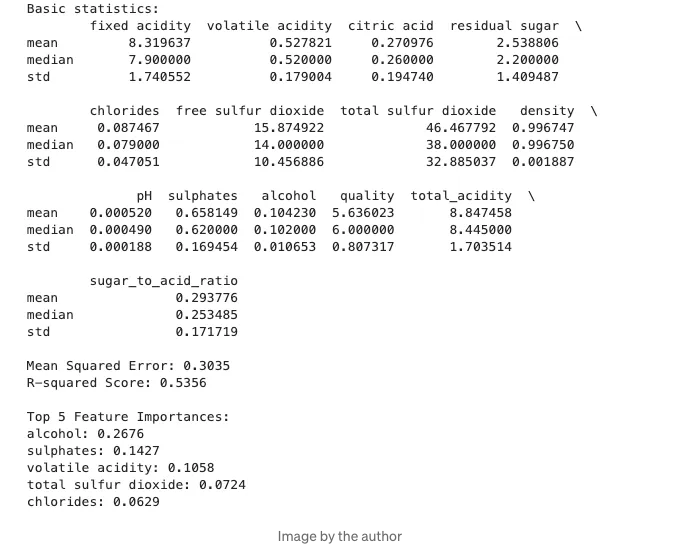
결론
파이썬의 다양한 기능은 데이터 과학 프로젝트를 완료하는 데 그치지 않습니다. 오히려 이러한 함수를 우아하고 효율적으로 완료하는 데 관한 것입니다. 파이썬 작업 경험을 통해 이러한 함수 모두를 숙달하려는 시도가 얼마나 압도적인지 이해합니다. 하지만 이러한 함수가 우리 업무에 얼마나 가치 있는지 그리고 중요한지도 경험했습니다. 이러한 함수를 일관된 실습을 통해 숙달하기 위해 시간을 투자하는 가치가 있다는 것이죠.