
보통 상황에서 처방 약물 봉투의 라벨을 읽는 것은 어려운 작업이 아니어야 합니다. 대부분 중요한 지시사항인 용량은 보통 다른 것보다 더 크게 인쇄되어 있습니다.
그러나 시각적으로 장애가 있는 또는 노인 환자와 같은 비정상적인 상황을 고려해 보십시오. 그러한 환자는 도움 없이 자신의 처방전 라벨을 읽을 수 없습니다.
당신은 약국에서 데이터 과학자 또는 Python 개발자로써, 이 문제를 해결하는 데 도움을 줄 수 있습니다. 환자의 처방전 라벨에 맞춰 적응 가능한 프로그램을 작성함으로써 이 프로그램은 라벨을 읽고 음성으로 변환할 것입니다.
이 기사에서는 먼저 이미지를 컴퓨터 비전을 사용하여 정리한 다음, Tesseract-OCR (Optical Character Recognition) 및 정규 표현식(REGEX)을 적용하여 관련 텍스트를 추출하고, Google의 텍스트 음성 변환(Text-To-Speech)을 사용하여 텍스트를 음성으로 변환하는 방법을 안내하겠습니다. 이 음성은 MP3 파일로 저장될 것입니다.
이 튜토리얼은 다음과 같이 구성되어 있으며 쉽게 이해할 수 있도록 다음과 같은 부분으로 나뉘어 집니다:
- Google Cloud API의 자격 증명 획득
- 폴더 구조
- 필수 라이브러리 설치
- 도우미 함수 정의
- 도우미 함수를 추출기 코드로 통합
- Fast API와 Uvicorn을 사용하여 코드를 위한 서버 작성
- Postman을 사용하여 애플리케이션 테스트
작성할 코드는 다양한 건강 기관에서 얻은 다른 종류의 처방 레이블에 적응할 수 있어야 함을 유의해 주세요. 예를 들어 특정 약국을 위해 이 코드를 작성 중이라면 동일한 형식의 레이블만 다루게 될 것입니다. 저는 주변 약국에서 받는 레이블을 선택했습니다.
아래는 여기에서 사용할 예시 레이블입니다:

그리고 저는 VS Code를 코드 편집기로 사용하고 있습니다.
1. Google Cloud API를 위한 자격 증명 획득하기
Google Cloud의 Text-To-Speech는 사용자가 선택한 언어, 음성, 음조 또는 기타 사용자 정의 옵션에 따라 텍스트를 자연스러운 음성으로 변환하는 데 심층 학습 모델을 사용합니다. Google은 이 API를 공개로 제공하고 있습니다. 이를 이용하려면 Google Cloud 플랫폼의 API 자격 증명을 JSON 형식으로 얻기 위해 다음 단계를 따르세요.
- 이 링크를 사용하여 Google Cloud 콘솔로 이동합니다.
- 왼쪽 상단의 네비게이션 메뉴(햄버거 아이콘)를 열고 'IAM 및 관리자'를 선택하고 '서비스 계정'을 클릭합니다.
- 서비스 계정을 생성합니다. 서비스 계정에 이름과 설명을 지정한 후 생성합니다.
- 이로써 서비스 계정 목록으로 돌아갑니다. 새로 생성된 서비스 계정으로 이동하여 '작업' 아래의 3개 점을 클릭하고 '키 관리'를 클릭합니다.
- '키 추가'를 클릭하여 새 키를 생성하고, 키 유형으로 JSON을 선택한 후 생성합니다.
- 이렇게 하면 자격 증명 JSON 파일이 컴퓨터로 다운로드됩니다. 본문에서는 작업 디렉토리에 gcp_credentials.json으로 저장했습니다.
2. 폴더 구조
프로젝트 종료 시, 폴더 구조는 아래와 같이 보일 것입니다. 현재는 이야기에서 필요한 항목이 나올 때마다 처리하므로 디테일에 신경 쓸 필요는 없습니다.
프로젝트-폴더/
├── .venv/
├── xxxxx
├── xxxx
├── resources/
├── IMG-20231203-WA0010.jpg
├── src/
├── outils.py
├── parser_prescription.py
├── exception.py
├── extractor.py
├── loggings
├── __init__.py
├── logs/
├── running_logs.log
├── uploads/
├── 8a542768-2cfa-4291-a16f-9688ab4a4e22.jpg
├── xxx
├── main.py
├── gcp_credentials.json
├── output.mp3
└── requirements.txt
3. 환경 설정 및 라이브러리 설치
코드 편집기의 터미널에서 아래 라인을 사용해 Python 환경을 생성하고 활성화하세요:
python -m venv .venv
.venv\Scripts\activate
다음으로, 다음 라이브러리들을 입력할 requirements.txt라는 텍스트 파일을 생성한 후, 터미널(명령 프롬프트)로 돌아가 다음 명령을 실행하여 가상 환경에 라이브러리들을 설치해주세요.
pytesseract==0.3.10 opencv_python==4.7.0.68 Pillow[all] fastapi==0.103.2 google-cloud-texttospeech[all] uvicorn
python -m pip install -r requirements.txt
이 라이브러리들이 어떻게 사용될지는 다음과 같습니다:
팔로우 - 처방전 레이블 이미지 파일을 열고 저장하는 데 사용됩니다.
OpenCV - 이미지를 처리하는 컴퓨터 비전 작업에 사용됩니다.
Pytesseract - 레이블 이미지에서 텍스트를 추출하기 위해 광학 문자 인식을 사용하는 Python 라이브러리입니다.
Fast API는 이 백엔드 프로젝트를 위한 웹 개발 프레임워크로 사용됩니다.
Google-cloud-texttospeech - 텍스트를 음성으로 변환하는 데 사용됩니다.
Uvicorn은 Fast API 응용 프로그램을 실행하는 데 사용할 서버입니다.
4. 도우미 함수 정의
Outils
src 폴더 안에 outils.py라는 Python 파일을 만들어주세요. 이곳에서는 이후에 사용될 두 개의 함수를 정의할 것입니다.
먼저, 이미지를 더 잘 볼 수 있도록 전처리하는 함수를 정의합니다. 우리의 처방전 레이블은 .jpg 파일 형식으로 이 시스템에서 사용될 것입니다. 이미지 품질은 획득 방법에 따라 좋지 않을 수 있습니다. 여기서는 컴퓨터 비전의 적응 임계값 처리를 적용하여 그레이스케일 부분을 바이너리로 변환할 것입니다.
이러한 처리 후, 위의 예제 레이블 이미지는 다음과 같이 보일 것입니다:

두 번째 기능은 텍스트를 음성으로 변환하는 text2speech 기능입니다. 이 기능은 메시지 텍스트를 입력으로 받아 Google의 텍스트 음성 시스템을 적용하여 자연스러운 음성을 합성합니다. 이 음성은 MP3 형식의 출력 파일로 현재 디렉토리에 저장됩니다.
# 아래 코드를 outils.py에 입력하세요
import cv2
import numpy as np
import os
import google.cloud
from google.cloud import texttospeech
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "gcp_credentials.json"
def preprocess_image(img):
# 이미지 전처리 함수
gray = cv2.cvtColor(np.array(img), cv2.COLOR_BGR2GRAY)
resized = cv2.resize(gray, None, fx=2, fy=2, interpolation=cv2.INTER_LINEAR)
processed_img = cv2.adaptiveThreshold(resized, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 61, 11)
return processed_img
def text2speech(message_text):
# 텍스트를 음성으로 변환
client = texttospeech.TextToSpeechClient()
synthesis_input = texttospeech.SynthesisInput(text=message_text)
voice = texttospeech.VoiceSelectionParams(language_code='en-US',
name='en-US-wavenet-C',
ssml_gender=texttospeech.SsmlVoiceGender.FEMALE)
audio_config = texttospeech.AudioConfig(audio_encoding=texttospeech.AudioEncoding.MP3)
response = client.synthesize_speech(input=synthesis_input, voice=voice, audio_config=audio_config)
with open('output.mp3', 'wb') as out:
out.write(response.audio_content)
print('음성 콘텐츠가 "output.mp3" 출력 파일에 작성되었습니다.')
처방전 파싱기
src 폴더에 parser_prescription.py라는 파이썬 파일을 만들어 PrescriptionParser()라는 클래스를 포함해야 합니다. 이 클래스에는 2가지 함수가 있습니다:
get_field() 함수를 정의하며, 처방전 라벨 텍스트에서 정규 표현식을 사용하여 4가지 필드를 추출합니다. 이 필드에는 처방 이름, 용량, 재입고 횟수 및 처방의 만료 날짜가 포함됩니다.
이러한 필드는 parse() 함수에 입력되어 완전한 텍스트 메시지를 가져오고, 이 메시지에는 앞서 정의된 outils 모듈의 text2speech() 함수가 호출됩니다.
# 파서_처방전.py 파일에 아래 코드를 입력하세요
import re
import src.outils
class PrescriptionParser():
def __init__(self, text):
self.text = text
# 음성으로 변환
def parse(self):
prescription_name = self.get_field('prescription_name')
dosage = (self.get_field('dosage').replace("GIVE", "TAKE")).lower().replace('\n\n', '')
refills = self.get_field('refills')
expirydate = self.get_field('expirydate')
message_text = f'안녕하세요, {prescription_name} 의약품 처방에 대해, {dosage}입니다. {refills}번 재입고 가능하며, 만료일은 {expirydate} 이전까지입니다.'
speech = src.outil.text2speech(message_text)
return speech
# 필드 가져오기
def get_field(self, field_name):
pattern = ''
flags = 0
pattern_dict = {
'prescription_name' : {'pattern': '(.*)Drug', 'flags' : 0},
'dosage' : {'pattern': 'Netcare[^\n]*(.*)All', 'flags' : re.DOTALL},
'refills' : {'pattern': 'Refilis:(.*)', 'flags' : 0},
'expirydate' : {'pattern': 'Refills.Expire:(.*)', 'flags' : 0}
}
pattern_object = pattern_dict.get(field_name)
if pattern_object:
matches = re.findall(pattern_object['pattern'], self.text, flags=pattern_object['flags'])
if len(matches) > 0:
return matches[0].strip()
5. 통합 추출 함수 정의
다음으로, 동일한 src 폴더에 extractor.py 파일을 작성합니다. 해당 파일에서는 outils 모듈의 preprocess_image() 함수를 사용하여 라벨 이미지 파일 경로를 입력으로 하는 extract() 함수를 정의합니다. 그 후 Pytesseract를 사용해 이미지를 텍스트로 변환합니다.
그 텍스트는 이전의 PrescriptionParser 클래스의 parse() 메서드로 전달되어 라벨을 읽는 음성이 .mp3 파일로 출력됩니다.
Pytesseract를 사용하려면 이 링크에서 Tesseract-OCR 실행 파일을 다운로드하고 설치해야 합니다. 반드시 Tesseract 설치 디렉토리가 시스템 환경 변수 경로에 추가되어 있는지 확인하세요. 그렇지 않으면 아래의 코드와 같이 경로를 코드에 포함시켜야 합니다.
# extractor.py에 아래 코드를 입력하세요
from PIL import Image
import pytesseract
import src.outils
from src.loggings import logger
from src.parser_prescription import PrescriptionParser
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def extract(file_path):
# 이미지에서 텍스트 추출
if file_path.endswith('.jpg'):
img = Image.open(file_path)
processed_image = src.outil.preprocess_image(img)
text = pytesseract.image_to_string(processed_image, lang='eng')
logger.info("텍스트 메시지 생성 완료")
# 텍스트에서 필드 추출하여 음성 변환
output_voice = PrescriptionParser(text).parse()
logger.info("음성 메시지 생성 및 파일로 저장 완료")
else:
raise Exception(f"올바르지 않은 파일 형식")
return output_voice
저희 코드에 소개할 가치가 있는 새로운 기능이 도입되었습니다.
로깅
추출기.py에 로깅이 통합되어 응용프로그램이 실행되는 동안 'logs'라는 폴더에서 이벤트를 추적합니다.
그래서 우리는 'logging'이라는 폴더를 만들어서, 여러 모듈에서 반복되는 로깅 설정을 피하기 위해 init.py 파일에 로깅 코드를 중앙 집중화했습니다.
# loggings 디렉토리의 __init__.py 파일에 이 코드를 입력하세요
import os
import sys
import logging
logging_str = "[%(asctime)s]: %(levelname)s: %(module)s: %(message)s]"
log_dir = "logs"
log_filepath = os.path.join(log_dir, "running_logs.log")
os.makedirs(log_dir, exist_ok=True)
logging.basicConfig(
level=logging.INFO,
format=logging_str,
handlers=[
logging.FileHandler(log_filepath),
logging.StreamHandler(sys.stdout)
]
)
logger = logging.getLogger("labelreaderLogger")
6. Fast API 서버 작성하기
이제 작업 디렉토리에 'uploads'라는 임시 폴더를 만드세요.
현재 프로젝트에서 이미지 파일을 전달해야 하므로 브라우저에서는 어려울 수 있습니다. 이에 대한 테스트 툴로 Postman을 사용할 것입니다. Postman이 없는 경우 Google에서 다운로드할 수 있습니다.
이제 Uvicorn을 사용하여 로컬 서버에서 실행되도록 Fast API 애플리케이션을 설계해 보겠습니다:
# main.py 파일에 다음 내용을 입력하세요
from src.loggings import logger
from fastapi import FastAPI, Form, UploadFile, File
import uvicorn
from src.extractor import extract
import uuid
import os
import sys
from src.exception import CustomException
from PIL import Image
app = FastAPI()
@app.post("/speech_from_doc")
def speech_from_doc(file: UploadFile):
contents = file.file.read()
file_path = "uploads/" + str(uuid.uuid4()) + ".jpg"
with open(file_path, "wb") as f:
f.write(contents)
try:
data = extract(file_path)
except Exception as e:
raise CustomException(e, sys)
if os.path.exists(file_path):
os.remove(file_path)
logger.info("음성 메시지가 생성되어 파일에 저장됨")
return data
if __name__ == "__main__":
uvicorn.run(app, host="127.0.0.1", port=8000)
위 코드는 전체 실행을 다룹니다. 이는 Postman에서 파일을 업로드하고, 임시 위치인 uploads 폴더에 저장하며, 이를 기반으로 텍스트를 추출하기 위해 이전 섹션에서 정의된 사용자 정의 extract() 함수를 처리하고, API 응답으로 음성 메시지를 출력하며, 그 후 임시 파일을 uploads 폴더에서 삭제하는 정리 작업을 수행합니다.
코드에 새로운 기능이 소개되었음을 알아채셨을 것입니다. 이는 언급할 가치가 있는 부분입니다.
사용자 정의 예외
일반적인 예외가 아닌 특정 오류를 잡기 위해 오류 클래스를 만들 수 있도록 포함했습니다.
'exceptions.py' 파일에 다음 코드를 작성하세요:
# exceptions.py에 다음을 입력하세요
import sys
def error_message_detail(error, error_detail: sys):
_, _, exc_tb = error_detail.exc_info() # error_detail.exc_info()는 3가지 출력이 있지만, 오류의 세부 정보를 포함하는 3번째 출력만 필요합니다
file_name = exc_tb.tb_frame.f_code.co_filename # exc_tb에서 파일 이름을 가져옵니다
error_message = "파이썬 스크립트 이름 [{0}]의 {1}번 라인에서 오류가 발생했습니다. 오류 메시지: {2}".format(
file_name, exc_tb.tb_lineno, str(error)
)
return error_message
class CustomException(Exception):
def __init__(self, error_message, error_detail: sys):
super().__init__(error_message)
self.error_message = error_message_detail(error_message, error_detail=error_detail)
def __str__(self):
return self.error_message
7. Postman을 사용한 테스트
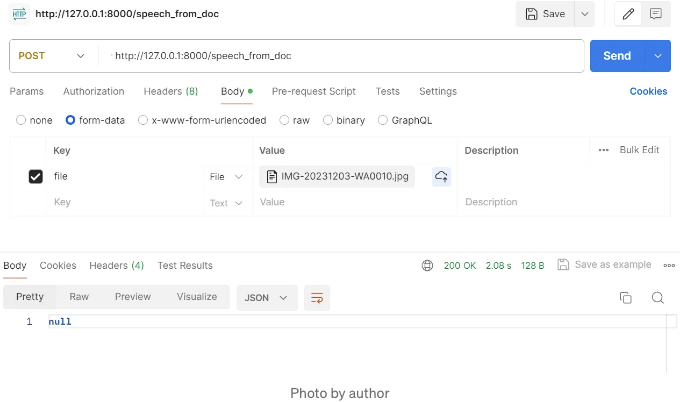
코드 편집기의 터미널에서 main.py를 실행하세요. Uvicorn 서버 URL을 얻고, Postman에서 main.py 코드에 정의된 /speech-from-doc의 POST 엔드포인트에 연결해보세요. 아래 사진 참고해주세요.
Postman에서 prescription label 이미지를 'Body' 및 'form-data' 탭에 업로드한 후 'Send'를 클릭하세요. 아래 사진과 같이요:
<table> 태그를 Markdown 형식으로 변환해주세요.
OCR 및 컴퓨터 비전을 활용하면 처방전 라벨을 쉽게 접근 가능한 음성 메시지로 변환할 수 있습니다.
디지턷 솔루션을 도입하는 의료 분야에서, 이는 가장 필요한 사람들을 지원하는 의미 있는 방법입니다.
잊지 말고
만약 당신이 방금 읽은 내용을 좋아한다면, 제 '팔로우' 버튼을 눌러줄 수 있을까요? 저는 미디엄이나 링크드인에서요. 박수를 몇 번 치거나, 주목한 부분을 강조하거나, 그보다는 댓글을 달아주시겠어요? 이 중 한 가지든 혹은 모두를 해 주신다면 정말 감사하겠습니다.