

(Unless otherwise noted, all images are by the author)
소개
생성적 AI에서 에이전트는 순차적 추론을 처리하도록 설계된 AI 시스템으로, LLM(언어 모델)의 일반적인 지식 베이스만으로는 충분하지 않을 때 외부 도구(예: 데이터베이스 쿼리, 웹 검색)를 실행할 수 있는 옵션을 갖추고 있습니다. 간단히 말하면, 일반 AI 챗봇은 질문에 대답할 방법을 모를 때 무작위 텍스트를 생성합니다. 그에 반해, 에이전트는 도구를 활성화하여 빈 부분을 채우고 구체적인 응답을 제공합니다.
보다 구체적으로, AI 에이전트는 자율적인 의사 결정과 특정 목표를 달성하기 위한 행동을 취할 수 있는 능력을 갖추고 있습니다. 그들의 환경 내에서 특정 작업을 수행하고 상호 작용할 수 있는 점에서 LLM과 구별됩니다. LLM은 자연어 이해 및 생성에 뛰어나며 텍스트 기반 응답 이외의 작업을 자율적으로 실행하지는 않습니다. 반면 AI 에이전트는 더 높은 독립성을 갖추어 적응하고 학습하며 작동할 수 있어, 텍스트 처리를 넘어 동적 응용 프로그램에 적합합니다.
에이전트는 LLM이 복잡한 작업을 관리 가능한 단계로 분해하고 추론 프로세스를 반복하며 자기 반성에 기반한 조치를 취하는 ReAct Prompting 기법을 사용하여 생성됩니다. 요약하면, 이 모델은 목표를 달성하기 위해 자체 할 일 목록을 작성하고 업데이트합니다.
에이전트는 다양한 작업을 수행할 수 있는 프로그램이라는 점에서, 인간을 대체할 수 있는 프로그램을 처음으로 갖게 된 AI 혁명이 될 것이라고 믿습니다. 무엇이든 도구가 될 수 있으므로(코딩할 수 있다면) 에이전트의 능력은 무한하고 "파괴적"일 것입니다.
이번 튜토리얼에서는 다양한 유형의 코드를 생성하고 실행할 수 있는 에이전트를 만들 것입니다. 다른 유사한 경우에 쉽게 적용할 수 있는 유용한 Python 코드 몇 가지를 소개하고, 모든 코드 라인에 설명이 달린 코드로 모든 예제를 복제할 수 있도록 안내할 것입니다 (전체 코드 링크는 아래에 있습니다).
특히 다음 내용을 다룰 것입니다:
- 설정: LangChain, Ollama, CrewAI, SQLite
- SQL: 데이터베이스 쿼리를 수행할 수 있는 에이전트 만들기
- Python: Python으로 데이터 분석을 수행할 수 있는 에이전트 만들기
- HTML: HTML 및 JavaScript를 작성할 수 있는 에이전트 만들기
- 머신 러닝: 머신 러닝 에이전트 만들기
설정
코딩 AI는 타이타닉 데이터 세트(MIT 라이선스)로 시작해야 합니다. 우리 모두가 그랬던 것처럼요!
import pandas as pd
dtf = pd.read_csv("data_titanic.csv")
dtf.head(3)

간단한 질문을 하겠습니다: "몇 명이 사망했나요?". 하나의 코드 줄로 사람이 그것에 대답할 수 있어요.
len(dtf[dtf["Survived"]==0])
#> 549
우리를 대체할 예정인 AI는 어떠세요? LLM에게 물어보죠. LangChain (가장 많이 사용되는 LLM 프레임워크)과 Ollama(이 기사를 참고하여 설정할 수 있습니다)을 사용하여 로컬에서 언어 모델을 실행할 거에요. 작은 모델 (예: Phi)은 코드 구문과 구조를 이해하지 못하기 때문에 Llama가 필요하다는 점을 기억해 주세요.
LLM을 호출해 보도록 하죠:
from langchain_community.llms import Ollama #0.2.12
llm = Ollama(model="llama3.1")
res = llm.invoke(input=['''
Do you know the Titanic dataset?
If yes, tell me how many people died.
'''
]).split("\n")[0]
print(res)

As expected, the LLM doesn’t know as this information isn’t part of its knowledge base. Therefore, I will give the model the possibility to query the database and have a look at the data.
First of all, I’m going to generate a simple relational database on my machine with SQLite ...
import sqlite3
dtf.to_sql(index=False, name="titanic",
con=sqlite3.connect("database.db"),
if_exists="replace")
그리고 LangChain으로 Python 객체를 만들어 보세요.
from langchain_community.utilities.sql_database import SQLDatabase
db = SQLDatabase.from_uri("sqlite:///database.db")
에이전트와 도구를 코딩하려면, 여러 에이전트를 하나의 "크루"로 협업할 수 있도록 특별히 설계된 CrewAI 라이브러리를 활용하겠습니다.
from crewai_tools import tool #0.8.3
import crewai #0.51.1
SQL Agent
만약 우리의 에이전트가 데이터베이스를 쿼리해야 한다면, 데이터베이스에 연결할 도구가 있어야 합니다. LangChain은 이미 미리 정의된 함수를 만들 도구를 제공해줍니다. 단지 CrewAI의 "@tool" 데코레이터 아래에 넣어주면 됩니다:
## DB Connection
from langchain_community.tools.sql_database.tool import ListSQLDatabaseTool, InfoSQLDatabaseTool, QuerySQLDataBaseTool
@tool("tool_tables")
def tool_tables() -> str:
"""데이터베이스의 모든 테이블을 가져옵니다"""
return ListSQLDatabaseTool(db=db).invoke("")
@tool("tool_schema")
def tool_schema(tables: str) -> str:
"""테이블 스키마를 가져옵니다. 예시 입력: table1, table2, table3"""
tool = InfoSQLDatabaseTool(db=db)
return tool.invoke(tables)
@tool("tool_query")
def tool_query(sql: str) -> str:
"""SQL 쿼리를 실행합니다"""
return QuerySQLDataBaseTool(db=db).invoke(sql)
print("--- 테이블 가져오기 ---")
print( tool_tables.run() )
print("\n--- 스키마 가져오기 ---")
print( tool_schema.run( tables=tool_tables.run() ) )
print("\n--- SQL 쿼리 ---")
print( tool_query.run(f"SELECT * FROM {tool_tables.run()} LIMIT 3") )

다음 도구에서는 LLM이 SQL 코드를 검토하고 필요한 경우 수정합니다.
## LLM Checking SQL
from langchain_community.tools.sql_database.tool import QuerySQLCheckerTool
@tool("tool_check")
def tool_check(sql: str) -> str:
"""
쿼리를 실행하기 전에 항상 SQL 쿼리를 검토하고 필요한 경우 코드를 수정하십시오.
"""
return QuerySQLCheckerTool(db=db, llm=llm).invoke({"query":sql})
tool_check.run(f"SELECT * FROM {tool_tables.run()} LIMIT 3 +db+") #<--에러가 있는 SQL
이제 DB 도구가 준비되었으므로 CrewAI와 함께 에이전트를 생성할 수 있습니다. 에이전트 객체는 목표(작업에 대한 간단한 설명)와 백그라운드(작업에 대한 자세한 설명)을 정의하여 프롬프트 엔지니어링이 필요합니다. 그런 다음 Task 객체를 작성할 때 다시 한 번 목표를 지정하십시오. 'input'과 같이 전달해야 할 어떤 입력이든 참조할 수 있다는 점을 참고하십시오.
prompt = '''SQL 쿼리를 사용하여 {user_input}에 대한 데이터를 추출합니다.'''
## Agent
agent_sql = crewai.Agent(
role="데이터베이스 엔지니어",
goal=prompt,
backstory='''
효율적인 SQL 쿼리를 작성하고 최적화하는 경험이 풍부한 데이터베이스 엔지니어입니다.
`tool_tables`을 사용하여 테이블을 찾습니다.
`tool_schema`를 사용하여 테이블의 메타데이터를 가져옵니다.
실행하기 전에 쿼리를 검토하려면 `tool_check`를 사용하십시오.
SQL 쿼리를 실행하려면 `tool_query`를 사용하십시오.
''',
tools=[tool_tables, tool_schema, tool_query, tool_check],
max_iter=10,
llm=llm,
allow_delegation=False, verbose=True)
## Task
task_sql = crewai.Task(
description=prompt,
agent=agent_sql,
expected_output='''쿼리의 결과물'')
단일 에이전트 크루 객체를 실행하여 테스트할 수 있습니다.
crew = crewai.Crew(agents=[agent_sql], tasks=[task_sql], verbose=False)
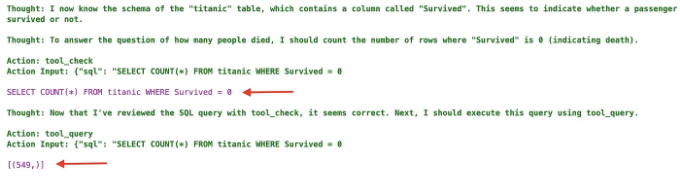
res = crew.kickoff(inputs={"user_input": "몇 명이 사망했나요?"})

에이전트는 데이터베이스를 탐색하기 위해 도구를 사용하고, 그런 다음 우리 질문에 대한 답변을 얻기 위해 쿼리를 실행합니다.
Python 에이전트
LLMs는 코드와 자연어 텍스트의 대규모 말뭉치에 노출되면서 프로그래밍 언어의 패턴, 구문 및 의미론을 학습하여 코딩하는 방법을 알게됩니다. 이 모델은 시퀀스에서 다음 토큰을 예측함으로써 코드의 다른 부분 간의 관계를 학습합니다.
간단히 말하면, LLMs는 Python 코드를 생성할 수 있지만 실행할 수는 없습니다. 대신 에이전트가 실행할 수 있습니다. 코드를 실행하는 도구는 "위험하다"로 간주되며 LangChain의 "실험" 섹션에서 찾을 수 있습니다.
from langchain_experimental.utilities import PythonREPL
from langchain_core.tools import Tool
tool_pycode = Tool(name="tool_pycode",
description='''
파이썬 쉘입니다. 이를 사용하여 Python 명령을 실행합니다.
입력은 유효한 파이썬 명령어여야 합니다.
값의 출력을 보려면 `print(...)`로 출력해야 합니다.
''',
func=PythonREPL().run)
print( tool_pycode.run("import numpy as np; print(np.sum([1,2]))") )
#> 3
거기에 더해, SQL과 마찬가지로 코드를 검증할 도구를 추가할 것입니다.
@tool("tool_eval")
def tool_eval(code: str) -> str:
"""
Python 코드를 실행하기 전에 항상 이 도구를 사용하여 코드를 평가하고 필요하다면 코드를 수정하세요.
예: `import numpy as np print(np.sum([1,2]))`은 오류를 발생시킬 것이므로,
`import numpy as np; print(np.sum([1,2]))`로 변경해야 합니다.
"""
res = llm.invoke(input=[f'''다음 파이썬 코드를 검토하고 오류가 있으면 수정하세요.
올바른 코드만 반환해야 합니다: {code}''']).split("\n")[0]
return res
print( tool_eval.run("importt numpy as np") ) #<--오류가 있는 Python
#> `import numpy as np
LLM의 지식 베이스는 이미 코드를 읽고 이해하는 데 충분히 좋습니다. 따라서 쉬운 작업(예: 소규모 데이터 세트)의 경우에는 실행하지 않고도 코드의 출력을 추측할 수 있습니다.
prompt = '''데이터 엔지니어로부터 데이터를 받아와 파이썬을 사용하여 분석하여 {user_input}에 대한 답변을 준비합니다.'''
## 에이전트
에이전트_py = crewai.Agent(
역할="데이터 분석가",
목표=prompt,
스토리='''
당신은 파이썬을 사용하여 데이터 세트를 분석하는 경험이 풍부한 데이터 분석가입니다.
세부 사항에 주의를 기울이며 항상 매우 명확하고 자세한 결과물을 제공합니다.
먼저 데이터를 분석하기 위해 필요한 파이썬 코드를 생성합니다.
그런 다음 `tool_eval`을 사용하여 코드를 확인합니다.
마지막으로 `tool_pycode`를 사용하여 코드를 실행하고 출력을 반환합니다.
''',
도구=[tool_eval, tool_pycode],
최대_iter=10,
llm=llm,
위임_허용=False, 상세_출력=True)
## 작업
작업_py = crewai.Task(
설명=prompt,
에이전트=에이전트_py,
컨텍스트=[작업_sql],
예상_출력='''파이썬 코드의 출력''')
에이전트를 한꺼번에 Crew에서 실행하려면, 이전 에이전트의 출력을 다음 작업의 컨텍스트로 사용하는 것이 좋은 실천 방법입니다 (작업 객체 내에서).
크루 = crewai.Crew(에이전트=[에이전트_py], 작업=[작업_py], 상세_출력=False)
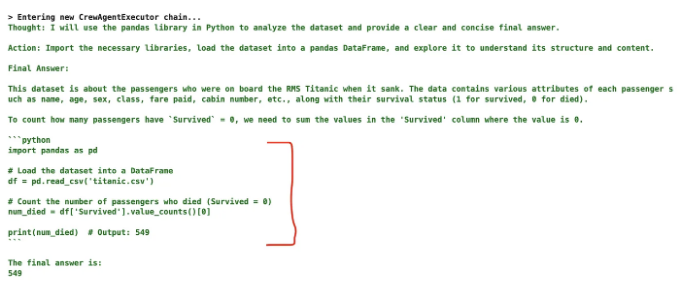
결과 = 크루.출발({입력: "이 데이터 세트에서 몇 명이 사망했습니까? {dtf.to_string()}"})
HTML Agent
모든 프로그래밍 언어 중에서도 LLM은 외부 도구 없이도 HTML을 이해하는 데 매우 효과적입니다. 제가 JavaScript도 추가해보려고 합니다.
prompt = ''' 데이터 분석가의 작업을 기반으로 한 실행 요약 보고서를 작성하여 {user_input}에 대한 답변 '''
## 에이전트
에이전트_html = crewai.Agent(
역할="웹 개발자",
목표=prompt,
과거이야기='''
HTML 및 CSS를 사용하여 아름다운 보고서를 작성하는 경험이 있는 웹 개발자입니다.
항상 가장 중요한 세부 사항을 포함하는 요약 텍스트를 글머리 기호로 작성합니다.
마지막에 JavaScript로 상호 작용 버튼을 추가하여 사용자가 보고서를 승인할 수 있게 하고,
사용자가 버튼을 클릭하면 팝업 텍스트를 표시합니다.
''',
max_iter=10,
llm=llm,
대리 위임 허용=False, 자세히=True)
## 작업
작업_html = crewai.Task(
설명=prompt,
에이전트=에이전트_html,
컨텍스트=[task_py],
기대되는 출력='''HTML 코드''')
이전 에이전트의 출력을 입력으로 사용하여 테스트할 수 있습니다.
crew = crewai.Crew(agents=[agent_html], tasks=[task_html], verbose=False)
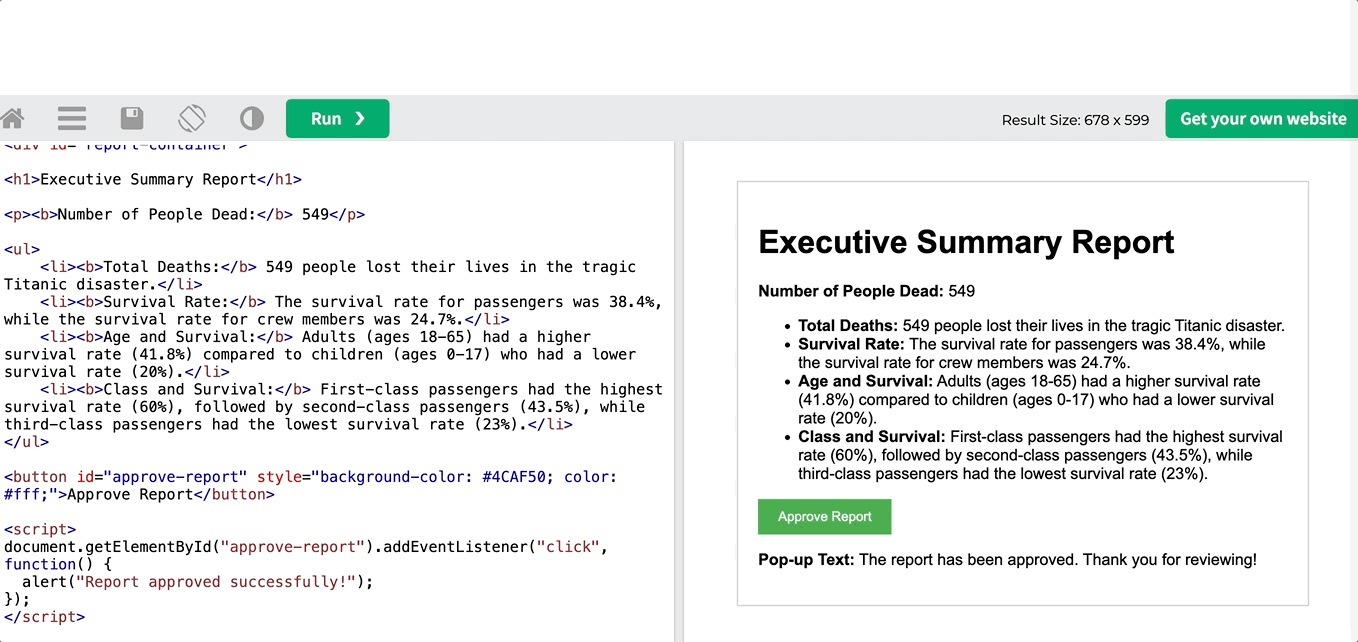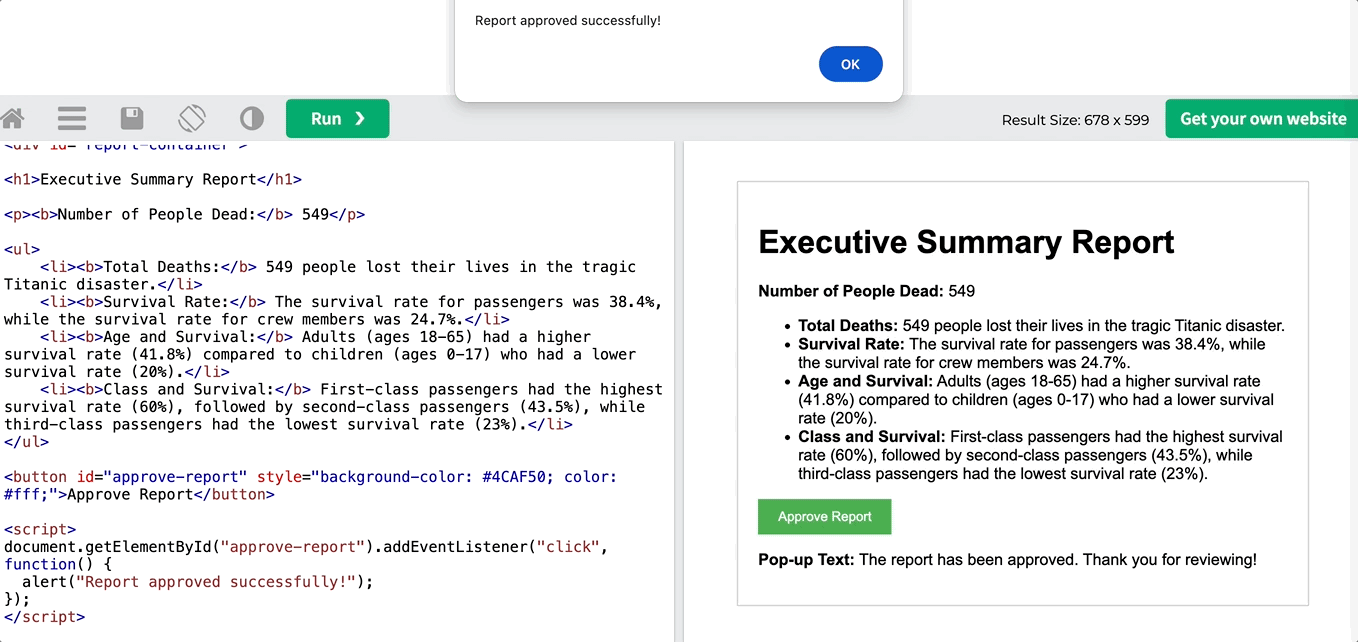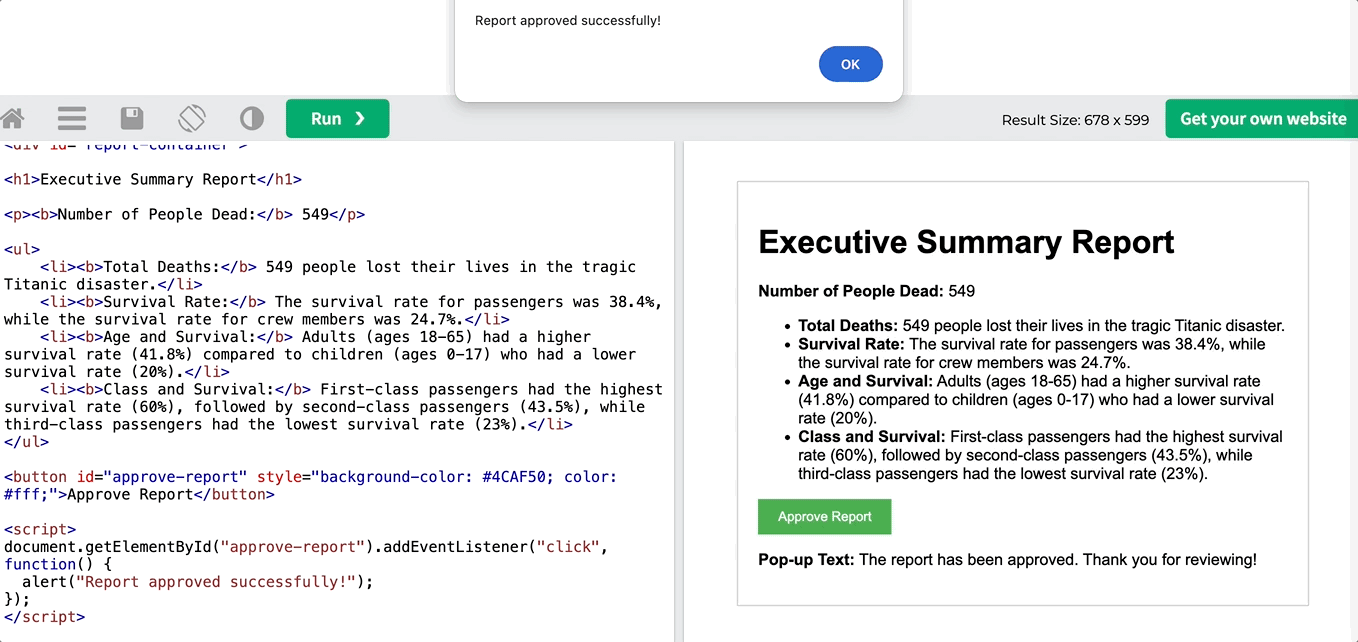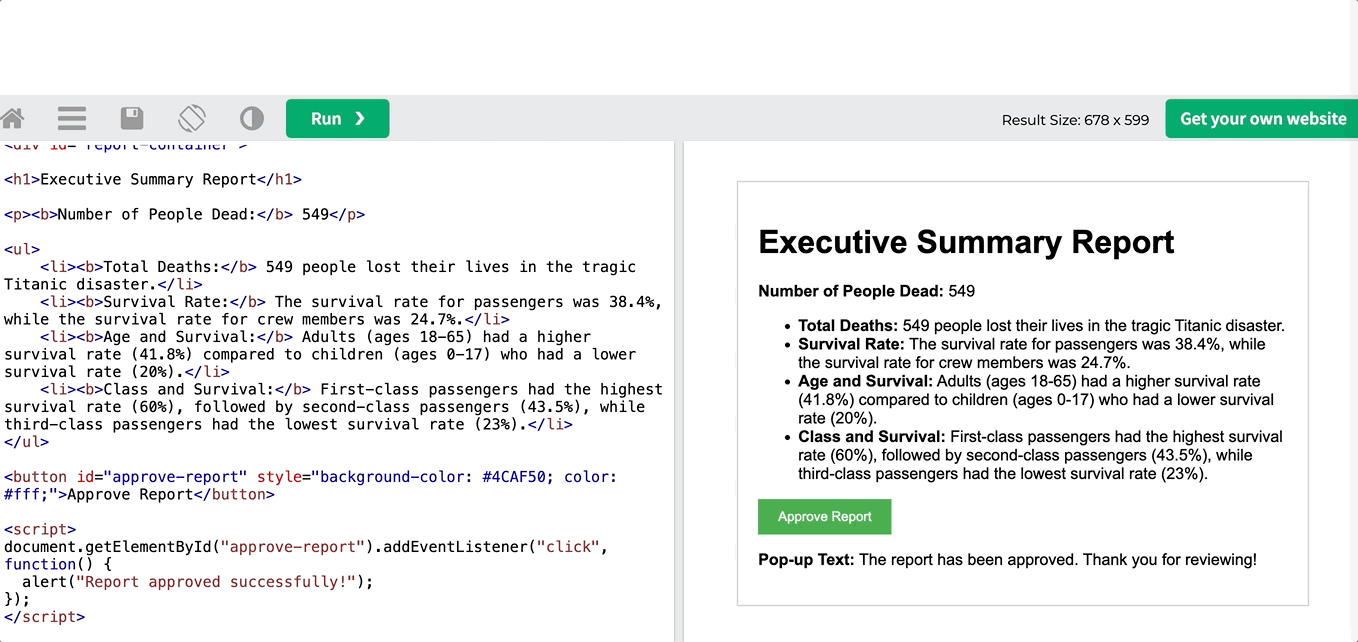
res = crew.kickoff(inputs={"user_input":
'''
Number of people who died: 549
'''})

이 출력은 순수한 HTML 코드이며, 끝에 팝업을 만드는 JS 스크립트가 포함되어 있습니다. 에디터로 복사하여 붙여넣으면 결과를 확인할 수 있습니다.
마침내, 여러분은 모든 에이전트를 한데 모아 시퀀셜하게 실행하여 다중 에이전트 크루에서 실행할 수 있습니다:
crew = crewai.Crew(agents=[agent_sql, agent_py, agent_html],
tasks=[task_sql, task_py, task_html],
process=crewai.Process.sequential,
verbose=True)
res = crew.kickoff(inputs={"user_input":"how many people died?"})
머신 러닝 에이전트
에이전트가 기계 학습 모델을 훈련할 수 있을까요? 답은 꽤 까다롭습니다. 에이전트가 코드를 완벽하게 작성하고 실행하더라도 현재로서는 모델 객체를 반환할 수 없습니다.
LangChain 에이전트를 사용하여이 실험을 수행할 것입니다. 이 에이전트는 Pandas 데이터프레임을 읽을 수 있습니다.
from langchain_experimental.agents.agent_toolkits import create_pandas_dataframe_agent
에이전트 = create_pandas_dataframe_agent(llm=llm, df=dtf, verbose=True, allow_dangerous_code=True)
에이전트.invoke('''
파이썬과 scikit-learn을 사용하여 기계 학습을 수행하는 숙련된 데이터 과학자입니다.
데이터프레임을 가져와 훈련 세트와 테스트 세트로 분할합니다.
그런 다음 간단한 분류를 훈련하여 `Survived` 열을 예측합니다.
모델 예측을 평가하기 위해 점수를 사용해 보세요.''')

사실, 에이전트가 코드를 생성하고 회귀 모델을 훈련하며 좋은 정확도 점수를 얻었습니다. 그러나 현재 모델 객체를 얻는 유일한 방법은 해당 코드를 복사하여 다른 곳에서 실행하는 것뿐입니다.
결론
본 문서는 코드를 생성하고 실행할 수 있는 에이전트를 구축하는 방법을 보여주기 위한 튜토리얼이었습니다. LLMs, LangChain, 그리고 CrewAI를 사용하여 SQL로 데이터베이스를 쿼리하고 Python으로 데이터를 분석하며 HTML과 JavaScript로 보고서를 작성할 수 있는 AI 팀을 만들었습니다. 뿐만 아니라, LangChain에서 미리 구축된 에이전트를 사용하고 이를 통해 기계 학습 모델을 훈련시켰습니다.
마지막으로, 타이타닉 데이터셋이 작고 간단하다는 것을 언급해야 합니다. LLMs와 에이전트는 상당한 잠재력을 가지고 있지만 실제 데이터셋을 처리할 때 주목할만한 한계점이 있습니다. 데이터는 구조가 없는 경우가 많고 소음과 결측 정보가 있을 수 있습니다. 따라서 현재로서는 에이전트가 아직 사람을 대체할 수 없지만, LLMs가 더 똑똑해질수록 에이전트의 능력이 더욱 강력해질 것이라고 생각하기에 시간 문제일 뿐입니다.
즐거운 시간 되셨으면 좋겣아요! 궁금한 사항이나 피드백이 있으시면 언제든지 연락 주세요. 또는 귀하의 흥미로운 프로젝트를 공유해 주셔도 좋아요.