이 게시물에서는 생성적 AI 기술을 활용하여 가상의 경매 차량 손상 평가 및 가치 평가 애플리케이션을 개발할 것입니다. 차량 식별 번호(VIN)와 차량 손상을 보여주는 이미지를 기반으로하여 기계 학습 및 생성적 AI 기술을 사용하여 경매를 위한 차량 가치를 평가하고 자세한 차량 설명을 생성합니다. 주요 기술로는 OpenAI의 CLIP(대조 언어-이미지 사전 훈련)의 오픈 소스 구현인 OpenCLIP, Amazon이 최근에 발표한 Amazon OpenSearch Serverless(미리 보기)용 Vector Engine, 그리고 AI21 Labs의 Jurassic-2(J2) Ultra Foundation Model이 포함되며, 이는 Amazon Bedrock을 통해 액세스할 수 있습니다. 이 애플리케이션은 보험 청구, 운송 및 소매를 포함한 손상 비용을 평가해야 하는 다른 산업에도 쉽게 적용할 수 있습니다.
이 게시물은 최근 AWS 동료 Jigna Gandhi와 Chad Jodon과 함께 참가한 일련의 생성적 AI 해커톤에서 영감을 받아 작성되었습니다. 저희는 팀으로 차량 경매 업계를 위한 우승 솔루션을 개발했습니다.
비디오 데모
AI 기술을 활용한 차량 손상 평가기 UI의 간단한 비디오 데모를 YouTube에서 확인할 수 있습니다.
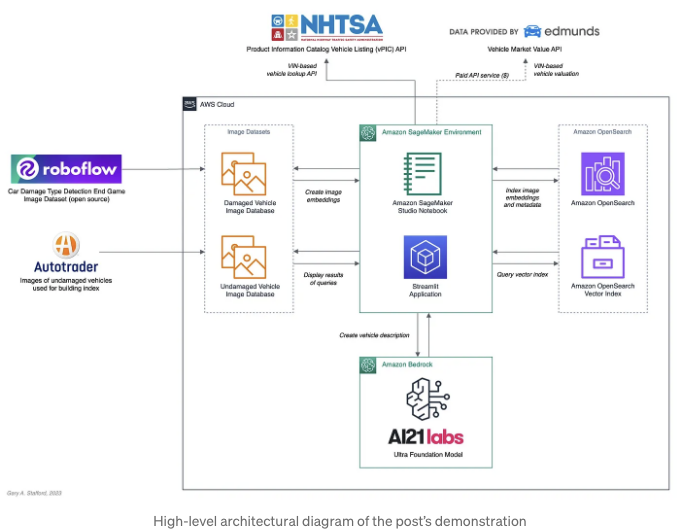
아키텍처
아래 아키텍처 다이어그램은 포스트에서 다루는 두 개의 별도 워크로드를 설명합니다. 처음으로, Amazon SageMaker Studio Notebook은 모든 차량 이미지의 OpenCLIP 벡터 임베딩을 생성하고, 새로운 Amazon OpenSearch Serverless 벡터 인덱스를 생성한 후, 차량 벡터 임베딩 및 다른 이미지 메타데이터를 포함하는 OpenSearch 문서를 새 벡터 인덱스에 색인화합니다. 둘째로, Python으로 작성된 Streamlit 애플리케이션은 사용자 인터페이스를 제공하여 차량 피해 평가를 수행하고 차량 경매 설명을 생성합니다.
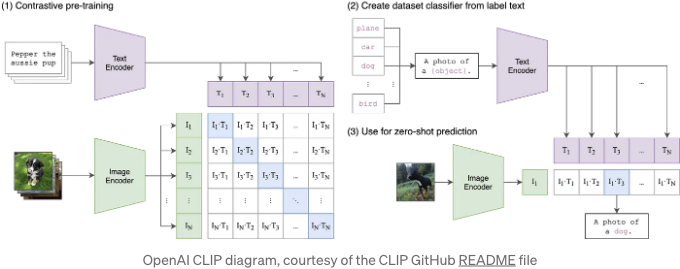
CLIP (대조적 언어-이미지 사전학습) 및 의미적 이미지 검색을 위한 밀집 벡터 임베딩이 처음이신가요? 그렇다면, 이전 포스트 "Amazon OpenSearch Serverless 벡터 검색 및 OpenAI CLIP 다중 모달 모델을 사용한 의미적 이미지 검색"을 읽어보시는 것을 추천드립니다.
오픈 소스 코드
이 게시물의 데모에 사용된 모든 소스 코드, Amazon SageMaker Studio 노트북 및 Streamlit 애플리케이션을 포함하여 GitHub에서 오픈 소스로 제공됩니다.
기술
OpenCLIP
OpenCLIP은 OpenAI의 CLIP의 오픈 소스 구현입니다. OpenAI는 CLIP을 이미지/텍스트 쌍으로 훈련된 신경망으로 정의합니다. 이를 자연어로 지시하여 직접적으로 작업에 최적화하지 않고 이미지를 주면 가장 관련 있는 텍스트 스니펫을 예측하도록 할 수 있습니다. CLIP에는 텍스트 엔코더와 이미지 엔코더가 모두 포함되어 있습니다. 이미지와 텍스트 토큰의 밀도 벡터 임베딩을 생성할 수 있습니다. CLIP은 시각적 분류 작업에 최적화되어 있습니다.
Amazon OpenSearch Serverless를 위한 벡터 엔진
2023년 7월 말, AWS는 Amazon OpenSearch Serverless (미리보기)를 위한 벡터 엔진을 발표했습니다. OpenSearch Serverless는 현재 세 가지 주요 컬렉션 유형을 지원합니다: 시계열, 검색 및 벡터 검색입니다. 벡터 검색은 벡터 임베딩에서 의미 검색을 허용하여 벡터 데이터 관리를 간소화하고 기계 학습(ML) 증강 검색 경험 및 생성적 AI 애플리케이션(챗봇, 개인 비서, 사기 탐지 등)을 제공합니다.
AI21 Labs의 Jurassic-2 (J2) Ultra Foundation Model
AI21 Labs는 AI 선구자 및 기술 베테랑인 Stanford, CrowdX 및 Mobileye 출신으로 2017년에 설립되었습니다. AI21 Labs는 Amazon Bedrock을 위한 AWS 런치 파트너로서 활동하며 현재 Jurassic-2 (J2) 시리즈의 차세대 Foundation 모델인 Ultra, Mid 및 Light를 포함한 최첨단 언어 모델을 구축하고 있습니다. AI21 Labs에 따르면 "Jurassic-2 Ultra는 복잡한 언어 생성 작업에 가장 크고 강력한 Foundation 모델이며, 어떤 언어 이해 또는 생성 작업에 대해서도 최고 품질을 제공합니다. HELM의 내부 평가에 따르면 Jurassic-2 Ultra는 86.8%의 승률을 기록하여 LLM 공간에서 선도적인 역할을 하고 있습니다. 이 역시 가장 비용이 많이 드는 언어 모델로서 가장 높은 대기 시간을 가지고 있지만, 복잡한 생성 및 이해 작업을 수행할 수 있는 능력이 있습니다." J2 Ultra는 글 요약에 뛰어나며, "일관적이고 완전하며 매력적인 제품 설명을 생성하면서 환각을 최소화"합니다. 저희 솔루션에 이상적인 선택입니다.
Amazon Bedrock
AWS는 2023년 9월 말에 Amazon Bedrock의 일반 가용성을 발표했습니다. 이전에 Bedrock은 여러 달 동안 미리보기로 고객에게 제공되었습니다. Amazon Bedrock은 Cohere, Anthropic, Stability AI, Meta 및 AI21 Labs와 같은 주요 AI 기업들의 Foundation 모델(FMs)을 API를 통해 사용할 수 있게 해주는 완전히 관리되는 서버리스 서비스입니다. AI21 Labs의 J2 Ultra Foundation 모델은 Boto3 SDK를 사용하여 이 게시물을 위해 Amazon Bedrock을 통해 접근되었습니다.
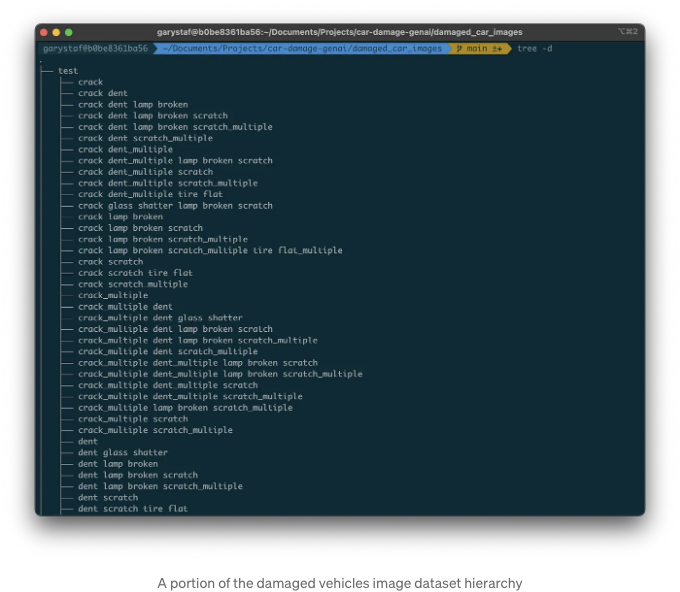
차량 이미지 데이터셋
우리는 손상된 차량과 손상되지 않은 차량을 위한 두 개의 차량 이미지 데이터셋을 사용할 것입니다. 손상된 차량 및 손상되지 않은 차량을 모두 포함하는 여러 차량 이미지 데이터베이스가 있습니다. 손상된 차량을 위해 Roboflow의 Car-Damage-Type-Detection-End-게임 컴퓨터 비전 프로젝트에서 데이터베이스를 사용할 것입니다. 데이터셋을 다운로드하고 압축을 해제해야 합니다. 데이터셋은 테스트, 훈련 및 유효성 검사 이미지 데이터셋으로 나뉘어 있습니다. 데이터셋은 균열, 찌그러짐, 긁힘, 펑크된 타이어 등과 같은 손상 유형별로 더 세분화되어 있습니다. 데이터셋에는 다양한 연식, 제조사 및 모델의 차량이 포함되어 있습니다.

여러 중고 자동차 재판매 웹 사이트에서 사용한 이미지로 사용자 지정 이미지 데이터 세트를 사전 빌드했습니다. 이 게시물에서는 간결함을 위해 최신 모델 3시리즈 BMW 자동차에 중저수준에 초점을 맞출 것입니다.
최상의 결과를 얻으려면 미손상 차량 이미지를 손상된 차량 이미지와 유사하게 자르는 것이 좋습니다.

The undamaged vehicle image dataset can be downloaded from Kaggle, Undamaged Vehicle Image Dataset. Many other vehicle datasets are available if you don’t want to build your own.
Getting Started
이 게시물에서는 Jupyter Notebook에서 개발된 코드를 실행하기 위해 Amazon SageMaker Studio를 사용할 것입니다. Amazon SageMaker Studio는 AWS의 기계 학습을 위한 완전히 통합된 개발 환경(IDE)입니다. GitHub 저장소에 있는 이 게시물의 Jupyter Notebook에는 다음과 같은 세 가지 기본 기능이 있습니다: 1) 모든 차량 이미지의 OpenCLIP 밀도 벡터 임베딩 생성, 2) 새로운 Amazon OpenSearch Serverless 벡터 인덱스 생성 및 3) 밀도 벡터 임베딩 및 관련 이미지 메타데이터를 포함하는 OpenSearch 문서를 새로운 벡터 인덱스로 색인화하기.
노트북 환경 설정
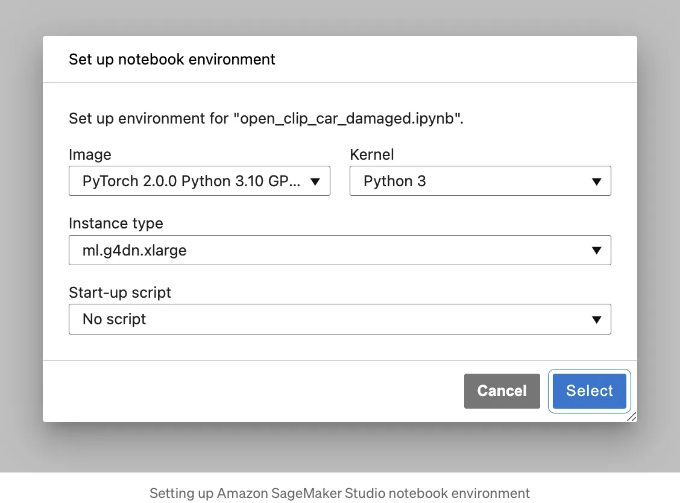
OpenCLIP은 PyTorch에 의존합니다. CPU 기반 인스턴스에서 노트북을 실행할 수 있지만, Amazon SageMaker Studio를 사용하고 있으므로 PyTorch 2.0.0 Python 3.10 GPU 최적화 SageMaker 노트북 이미지, Python 3 커널 및 ml.g4dn.xlarge 인스턴스 유형을 권장합니다. 문서에 따르면 AWS Deep Learning (DL) Containers에는 CUDA 11.8을 사용한 PyTorch 2.0.0용 컨테이너가 포함되어 있어 GPU에서 학습할 수 있습니다. 더 자세한 정보는 Deep Learning Containers의 릴리스 노트를 참조하세요. AWS 비용을 최소화하기 위해 작업을 마치면 커널 세션과 실행 중인 노트북을 종료하지 않도록 잊지 마세요.
벡터 임베딩 생성
먼저 OpenCLIP과 OpenSearch의 Python 클라이언트인 opensearch-py를 포함한 데모용 필수 Python 패키지를 설치해주세요.
%pip install boto3 open_clip_torch pillow opensearch-py -Uq
%pip list | grep 'open-clip-torch\|torch\|opensearch-py\|boto3'
그런 다음, 이 부분의 데모에 필요한 패키지를 가져와주세요.
import csv
import json
import os
import random
import open_clip
import torch
from PIL import Image
OpenCLIP은 80개 이상의 미리 학습된 ViT, ConvNeXt, EVA, ResNet 및 기타 CLIP 모델에 액세스할 수 있습니다. 모델은 open_clip.list_pretrained() 명령을 사용하여 나열할 수 있습니다. 자세한 OpenCLIP 모델 카드는 Hugging Face에서 찾을 수 있습니다.
[('RN50', 'openai'),
('RN50', 'yfcc15m'),
('RN50', 'cc12m'),
('RN50-quickgelu', 'openai'),
('RN50-quickgelu', 'yfcc15m'),
('RN50-quickgelu', 'cc12m'),
('RN101', 'openai'),
('RN101', 'yfcc15m'),
('RN101-quickgelu', 'openai'),
('RN101-quickgelu', 'yfcc15m'),
('RN50x4', 'openai'),
('RN50x16', 'openai'),
('RN50x64', 'openai'),
('ViT-B-32', 'openai'),
... 생략 ...
('EVA02-E-14-plus', 'laion2b_s9b_b144k')]
이미지 임베딩에 대해 우리는 ViT-L/14 — LAION-2B CLIP 모델을 사용할 것입니다. 이 모델은 20억 건의 영어 하위 집합인 LAION-5B를 사용하여 학습된 CLIP ViT L/14 모델입니다. 모델 이름에서 ViT는 Vision Transformer의 약자이며, L은 Large를 나타내고, 14는 14 x 14 입력 패치 크기를 의미합니다. 따라서, 224 x 224 픽셀 크기의 이미지 (이 CLIP 모델의 입력 크기) / 14 x 14 패치 크기 = 256개의 고정 크기 패치 x 3채널 (RGB). 모델은 768개의 임베딩 차원을 생성합니다 (Table 18: Common CLIP hyperparameters 참조). 우리는 또한 CLIP의 텍스트 토크나이제이션 부분에 ViT-L-14를 사용합니다. 이러한 모델이 어떻게 작동하는지에 대한 더 깊은 이해를 위해 이미지 인식을 위한 Transformer 논문 'An Image is Worth 16x16 Words'를 참조하십시오.
device = "cuda" if torch.cuda.is_available() else "cpu"
# reference: https://huggingface.co/laion/CLIP-ViT-L-14-laion2B-s32B-b82K
model, _, preprocess = open_clip.create_model_and_transforms(
model_name="ViT-L-14",
pretrained="laion2b_s32b_b82k",
device=device,
)
tokenizer = open_clip.get_tokenizer("ViT-L-14")
아래 함수를 사용하여 이미지 임베딩을 만듭니다. 이 함수는 model.encode_image를 호출하며, 이미지 경로를 문자열로 받아들이고 임베딩을 반환합니다:
# open clip를 사용하여 이미지 임베딩 생성
def create_image_embedding(image_path, device):
image = preprocess(Image.open(image_path)).unsqueeze(0)
image = image.to(device)
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.encode_image(image)
return image_features.tolist()[0]
이 어플리케이션의 기능은 아니지만, 시맨틱 유사성 검색을 위해 이미지의 벡터 임베딩을 만드는 것 외에도 OpenCLIP를 사용하여 텍스트 임베딩을 만들 수 있습니다. 이때는 model.encode_text를 호출하면 됩니다:
# 오픈 클립을 사용하여 텍스트 임베딩 생성
def create_text_embedding(text):
text = tokenizer(text)
text = text.to(device)
with torch.no_grad(), torch.cuda.amp.autocast():
text_features = model.encode_text(text)
return text_features.tolist()[0]
우리는 나중에 손상으로 인한 차량 가치 하락을 계산하기 위해 시맨틱 유사성 검색을 사용하여 각 이미지에 심각도 수준을 할당해야 합니다. 데모를 위해 4,000개의 이미지를 수동으로 모두 레이블 지정하는 데 시간이 너무 오래 걸리므로 각 차량 사진에 세 가지 중 하나의 심각도 수준을 무작위로 할당하겠습니다:
# 손상된 차량 이미지에 무작위 심각도 할당
def random_severity():
damage_severity_list = ["경미한", "보통", "심각한"]
severity = random.choice(damage_severity_list)
return severity
벡터 임베딩과 해당 오픈서치 문서의 수량과 크기를 고려하여, 문서를 메모리가 아닌 CSV 파일에 영구적으로 저장한 후 별도로 색인화하기로 했습니다. 이는 필요할 때마다 오픈서치 벡터 색인을 다시 만들어야 할 때 매번 임베딩을 다시 계산하지 않고도 테스트 중에 빠르게 재생성할 수 있도록 했지만, 필수적인 과정은 아닙니다.
index_name = "open-clip-car-damage-index"
# create vector embeddings and corresponding opensearch documents for image
def create_documents_with_embeddings_to_csv(document_path, image_directory, damage):
embedding_request_body = ""
row_count = 0
header = ["document"]
ext = [".png", ".jpeg", ".jpg"]
with open(document_path, "w", encoding="UTF8", newline="") as f:
writer = csv.writer(f)
writer.writerow(header)
for dir_path, dir_names, filenames in os.walk(image_directory):
for filename in filenames:
if filename.lower().endswith(tuple(ext)):
description = dir_path.split("/")[-1]
file_path = os.path.join(dir_path, filename)
try:
embedding = create_image_embedding(file_path, device)
embedding_request_body = json.dumps(
{
"image_vector": embedding,
"name": filename,
"file_path": file_path,
"description": description,
"severity": random_severity() if damage else "none",
}
)
writer.writerow([embedding_request_body])
print(f"Creating document: {row_count}", end="\r")
row_count += 1
except Exception as ex:
print(ex)
create_documents_with_embeddings_to_csv(
"embeddings/open_clip_embeddings_undamaged.csv",
"undamaged_car_images/",
False
)
create_documents_with_embeddings_to_csv(
"embeddings/open_clip_embeddings_damaged.csv",
"damaged_car_images/",
True
)
각 OpenSearch 문서는 다음 샘플과 유사합니다 (768 차원의 축약된 벡터 임베딩):
{
"image_vector": [
-0.550208568572998,
-0.1505182534456253,
0.21037432551383972,
-1.4110479354858398,
...
0.13773436844348907,
0.035001739859580994,
-0.28702571988105774,
0.018512779846787453
],
"name": "000650_jpg.rf.e856c0bd9939e82862ce22b1b0e0e30f.jpg",
"file_path": "damaged_car_images/test/scratch/000650_jpg.rf.e856c0bd9939e82862ce22b1b0e0e30f.jpg",
"description": "scratch",
"severity": "moderate"
}
벡터 인덱스 생성
이전 게시물에서는 Amazon OpenSearch 서버리스 벡터 검색 및 OpenAI CLIP 다중 모달 모델을 사용한 의미론적 이미지 검색에 대해 설명했습니다. Amazon OpenSearch 도메인 및 관련 AWS IAM 역할 및 필요한 OpenSearch 정책을 생성하는 방법을 자세히 설명했죠. 자세한 내용은 게시물을 확인해주세요. 이제 이러한 리소스가 이미 있는 것으로 가정하고 벡터 검색 콜렉션 및 해당 벡터 인덱스를 생성하는 것부터 시작해보겠습니다. 먼저 Amazon OpenSearch에 연결하기 위해 OpenSearch 서버리스 클라이언트를 인스턴스화하세요:
# opensearch 서버리스 클라이언트 생성
from opensearchpy import OpenSearch, RequestsHttpConnection, AWSV4SignerAuth, helpers
import boto3
client = boto3.client("opensearchserverless")
그런 다음, 아래와 같이 새로운 OpenSearch 콜렉션을 생성하세요. 타입은 VECTORSEARCH여야 합니다:
# 벡터 검색 콜렉션 생성
try:
response = client.create_collection(
description="OpenCLIP car damage collection",
name="open-clip-car-damage-collection",
type="VECTORSEARCH"
)
print(json.dumps(response, indent=2))
except Exception as ex:
print(ex)
컬렉션이 생성되면 새로운 벡터 검색 컬렉션의 OpenSearch 엔드포인트를 제공하여 OpenSearch Serverless 연결을 다시 설정하세요. 이 엔드포인트는 OpenSearch 콘솔에서 찾을 수 있거나 AWS CLI 또는 Boto3 SDK를 사용하여 확인할 수 있습니다.
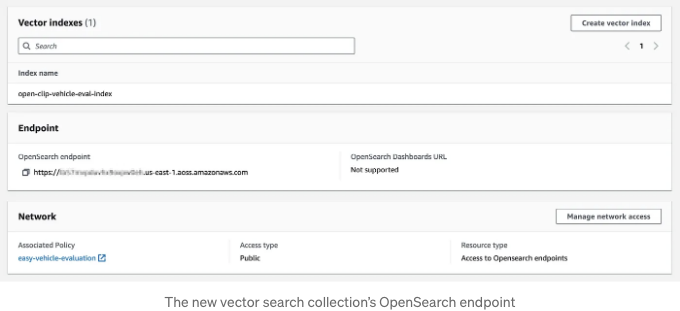
환경에 따라 호스트와 엔드포인트를 업데이트하세요. 호스트 값에 https://를 포함하지 마세요.
# 오픈서치 서버리스 클라이언트 생성
host = "<귀하의_고유한_호스트_이름>.<귀하의_리전>.aoss.amazonaws.com"
region = "<귀하의_리전>"
service = "aoss"
credentials = boto3.Session().get_credentials()
auth = AWSV4SignerAuth(credentials, region, service)
client = OpenSearch(
hosts = [{"host": host, "port": 443}],
http_auth = auth,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection,
pool_maxsize = 20
)
새로운 벡터 검색 컬렉션 내에서, 다음으로 indices.create()를 사용하여 새로운 벡터 인덱스를 만들 것입니다. 인덱스 내 각 문서에는 이름, 파일 경로, 설명, 심각도 및 이미지 벡터와 같은 다섯 가지 속성이 포함될 것입니다. 이미지 벡터를 제외한 나머지 네 가지 속성 값은 정보성이 있습니다. 나중에 해당 속성 값을 어떻게 활용할 수 있는지 포스팅에서 살펴보겠습니다.
OpenCLIP 모델에 의해 이미지에서 생성된 밀도 벡터 임베딩은 768차원을 가집니다. 이러한 벡터를 쿼리하기 위해, 인덱스는 Non-Metric Space Library (nmslib)를 사용하도록 구성되어 있으며, Hierarchical Navigable Small Worlds 알고리즘 (HNSW) 및 코사인 유사도 (cosinesimil)를 사용합니다. OpenSearch의 k-NN 인덱스 문서와 AWS 블로그 게시물 "Choose the k-NN algorithm for your billion-scale use case with OpenSearch"을 참고하여 사용 가능한 검색 옵션에 대해 자세히 알아보시기를 권장합니다.
# 새로운 인덱스 생성
index_body = {
"mappings": {
"properties": {
"description": {
"type": "text"
},
"file_path": {
"type": "text"
},
"image_vector": {
"type": "knn_vector",
"dimension": 768,
"method": {
"engine": "nmslib",
"space_type": "cosinesimil",
"name": "hnsw",
"parameters": {
"ef_construction": 768,
"m": 16
}
}
},
"severity": {
"type": "text"
},
"name": {
"type": "text"
}
}
},
"settings": {
"index": {
"number_of_shards": 2,
"knn.algo_param": {
"ef_search": 768
},
"knn": True,
}
}
}
try:
response = client.indices.create(index_name, body=index_body)
print(json.dumps(response, indent=2))
except Exception as ex:
print(ex)
만들어진 새 벡터 인덱스의 설명을 가져오기 위해 indices.get()를 사용하여 생성 여부를 확인할 수 있습니다:
# 새로운 벡터 인덱스 설명
try:
response = client.indices.get(index_name)
print(json.dumps(response, indent=2))
except Exception as ex:
print(ex.error)
예시 출력:
{
"open-clip-car-damage-index": {
"aliases": {},
"mappings": {
"properties": {
"description": {
"type": "text"
},
"file_path": {
"type": "text"
},
"image_vector": {
"type": "knn_vector",
"dimension": 768,
"method": {
"engine": "nmslib",
"space_type": "cosinesimil",
"name": "hnsw",
"parameters": {
"ef_construction": 768,
"m": 16
}
}
},
"name": {
"type": "text"
},
"severity": {
"type": "text"
}
}
},
"settings": {
"index": {
"number_of_shards": "2",
"knn.algo_param": {
"ef_search": "768"
},
"provided_name": "open-clip-car-damage-index",
"knn": "true",
"creation_date": "169...169",
"number_of_replicas": "0",
"uuid": "m4Y4...981E",
"version": {
"created": "135...827"
}
}
}
}
}
문서 색인하기
만들어진 벡터 인덱스로 손상된 차량 문서와 손상되지 않은 차량 문서를 모두 Amazon OpenSearch에 인덱싱할 수 있습니다.
# csv 파일에서 문서 로드 및 opensearch로 색인
def index_documents(document_path):
with open(document_path) as f:
row_count = sum(1 for _ in f) - 1
f.seek(0)
reader = csv.reader(f)
next(reader)
for index, row in enumerate(reader):
try:
document = eval(row[0])
client.index(
index=index_name,
body=document,
)
print(f"문서 색인 중: {index+1}/{row_count}", end="\r")
except Exception as ex:
print(ex)
index_documents("embeddings/open_clip_embeddings_damaged.csv")
index_documents("embeddings/open_clip_embeddings_undamaged.csv")
문서를 색인하는 데는 bulk() 작업을 사용하는 것이 더 빠릅니다. 유감스럽게도, 인덱스 할당 시 벡터 인덱스와 검색 인덱스를 비교했을 때 몇 가지 제한 사항을 만났습니다 (Document ID is not supported in create/index operation request error).
벡터 인덱스 테스트
인덱스가 작동하는지 테스트하려면 샘플 이미지의 벡터 임베딩을 생성하고, 벡터 인덱스를 사용하여 k-NN 쿼리를 수행한 후 상위 n개 결과를 반환하여 결과 이미지를 표시할 수 있습니다:
import numpy as np
from PIL import Image
from matplotlib import pyplot as plt
# 샘플 이미지를 선택하고 미리보기합니다.
search_image_path = "test_images/undamaged/test_image_09.png"
search_image = np.array(Image.open(search_image_path))
plt.box(on=None)
plt.axis("off")
plt.imshow(search_image)
# 벡터 임베딩을 생성하고 결과를 미리보기합니다.
image_embedding = create_image_embedding(search_image_path)
print(image_embedding[0:12]) # 디버깅용
# 벡터 임베딩을 사용하여 상위 10개 결과를 쿼리합니다.
query = {
"size": 10,
"_source": {"excludes": ["image_vector"]},
"query": {
"knn": {
"image_vector": {
"vector": image_embedding,
"k": 10,
}
}
},
}
try:
image_based_search_response = client.search(
body=query, index=index_name
)
print(json.dumps(image_based_search_response, indent=2))
except Exception as ex:
print(ex)
# 검색 결과 이미지를 미리보기합니다.
index = 1
rows = 2
columns = 5
fig = plt.figure(figsize=(18, 9))
for result in image_based_search_response["hits"]["hits"]:
fig.add_subplot(rows, columns, index)
image = np.array(Image.open(result["_source"]["file_path"]))
plt.axis("off")
plt.title(f'{result["_source"]["description"][0:35]}', fontsize=11)
plt.imshow(image)
index += 1
출력을 사용하여 결과가 테스트 이미지와 유사한지를 질적으로 판단할 수 있습니다:

차원 축소를 사용하여 검색 결과 평가하기
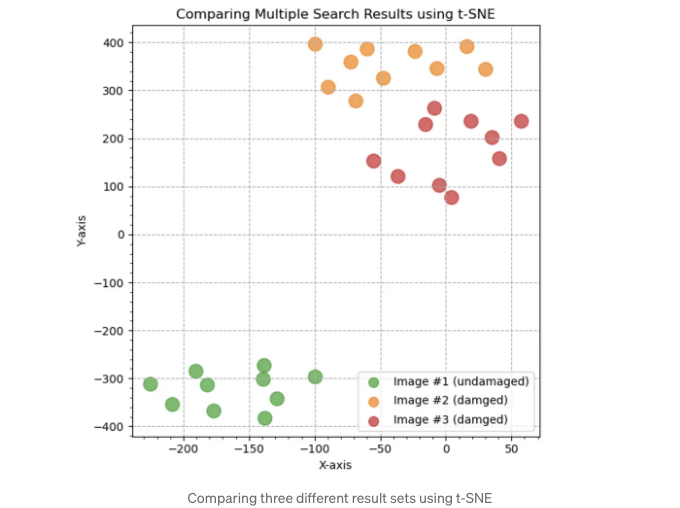
검색 결과를 정량적으로 평가하고 여러 검색 결과 세트를 비교하는 여러 가지 방법이 있습니다. 사용할 수 있는 한 가지 기술은 t-분포 확률적 이웃 임베딩(t-SNE)입니다. 위키백과에 따르면, t-SNE는 각 데이터 포인트에 2D 또는 3D 지도상의 위치를 할당하여 고차원 데이터를 시각화하는 통계적 방법입니다. t-SNE를 사용하여 여러 시맨틱 유사성 검색에서 반환된 768차원 CLIP 임베딩의 차원을 2로 축소하고 결과를 2D 산포도로 나타낼 수 있습니다. 아래에서는 세 가지 차량 이미지에 대한 상위 10개 쿼리 결과를 나타내는 세 가지 벡터 클러스터를 볼 수 있습니다. 각 OpenSearch 결과 세트(클러스터) 내에서 결과의 상대적 근접성 및 서로 다른 결과 세트 간의 근접성을 관찰할 수 있습니다. 근접성은 결과 세트 내 이미지 간의 유사성을 반영합니다.
또 다른 방법은 주성분 분석(PCA)을 사용하는 것입니다. PCA는 데이터셋의 차원을 줄이는 인기 있는 통계 기법입니다. PCA를 사용하여 여러 시맨틱 유사성 검색에서 반환된 768차원 CLIP 임베딩의 차원을 3으로 축소하고 결과를 3D 산포도로 나타낼 수 있습니다.
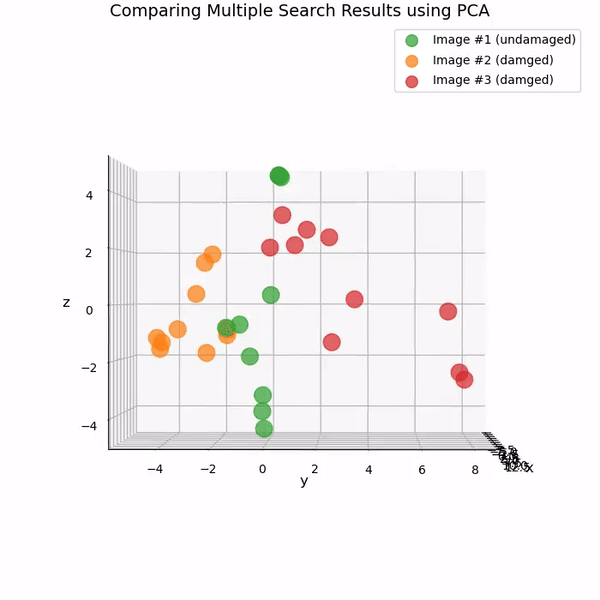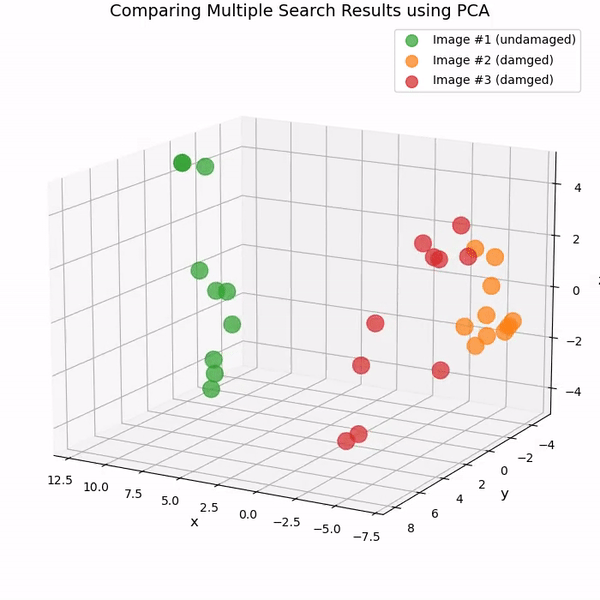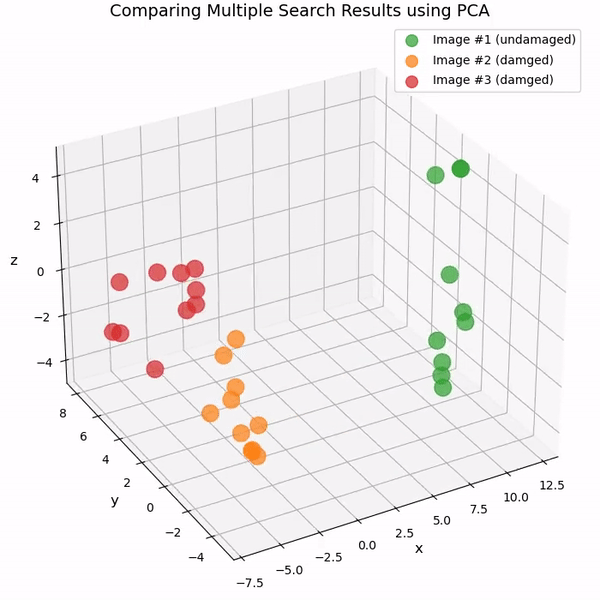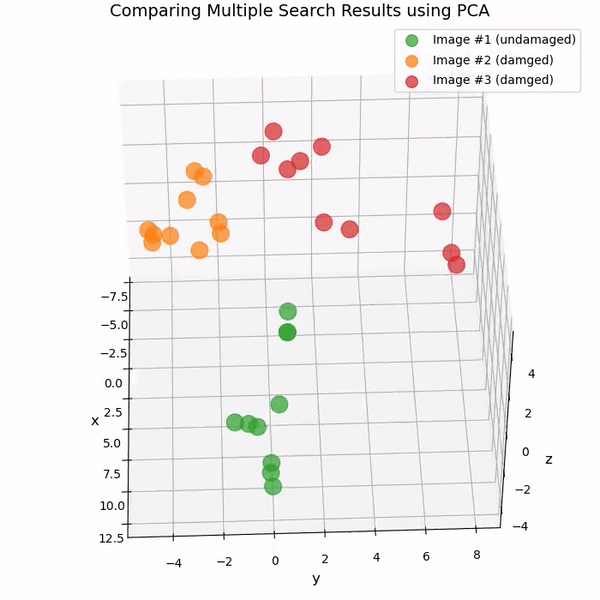
You can also watch the chart as an animated 3D video on YouTube:
AI-파워드 차량 피해 평가 애플리케이션
주피터 노트북과 같이 CPU 기반 인스턴스에서 Open CLIP을 사용하여 실행하는 것은 가능하지만, M1 칩을 탑재한 MacBook Pro로도 작동은 가능하지만 상당히 느릴 수 있습니다. GPU 기반 인스턴스를 권장합니다. 애플리케이션을 실행하려면, 최신의 boto3 패키지를 비롯한 여러 Python 패키지를 설치해야 합니다. 새로운 bedrock-runtime 서비스를 invoke_model 메서드에 통합한 boto3 패키지가 필요합니다. GitHub 저장소에 requirements.txt 파일이 포함되어 있습니다. 제 Python 프로젝트를 위해 가상환경을 만드는 것을 선호합니다:
python -m pip install virtualenv
virtualenv car-damage
python -m venv car-damage
source car-damage/bin/activate
python -m pip install -r requirements.txt -Uq
AI 파워드 차량 손상 평가자 애플리케이션은 Streamlit으로 제작되었습니다. 터미널에서 다음 명령어를 실행하여 HTTP를 사용하여 기본 포트 8501에서 Streamlit 애플리케이션을 시작할 수 있습니다:
streamlit run app.py \
--server.runOnSave true \
--theme.base "light" \
--theme.backgroundColor "#ffffff" \
--theme.primaryColor "#1455ba" \
--ui.hideTopBar "true" \
--client.toolbarMode "minimal"
등록된 인터넷 도메인 및 해당 SSL/TLS 인증서가 있는 경우 HTTPS를 사용하여 포트 443에서 Streamlit 애플리케이션을 안전하게 실행하는 것도 가능합니다.
python3 -m streamlit run app.py \
--server.runOnSave true \
--theme.base "light" \
--theme.backgroundColor "#ffffff" \
--theme.primaryColor "#1455ba" \
--ui.hideTopBar "true" \
--client.toolbarMode "minimal" \
--server.port 443 \
--server.sslCertFile "<sub-domain>.<domain>.com/certificate.crt" \
--server.sslKeyFile "<sub-domain>.<domain>.com/private.key"
차량 정보
애플리케이션의 첫 번째 섹션인 "차량 정보"는 차량 식별 번호(VIN), 외부 차량 색상 및 주행 거리를 입력받습니다. 초기 경매 예상가는 예상 차량 가치를 얻기 위해 제3자 API에 요청을 시뮬레이션합니다. 이러한 서비스는 대부분 유료 서비스이므로 우리는 Edmunds나 VinAudit 또는 CarsXE와 같은 외부 데이터 제공 업체로부터의 응답을 시뮬레이션할 것입니다.

VIN을 입력하면, 국립고속도로교통안전청(NHTSA)에 외부 API 호출이 이루어집니다. 구체적으로 NHTSA의 제품 정보 카탈로그 및 차량 목록(vPIC)으로 호출됩니다.
아래는 JSON 페이로드에서 반환되는 최대 150개 정보 필드 중 간축된 출력입니다. vPIC 데이터에는 차량 색상이나 현재 주행 거리가 포함되지 않음을 참고하세요.
{
"Count": 1,
"Message": "결과가 성공적으로 반환되었습니다. 참고: 누락된 해독된 값이 있을 수 있습니다...",
"SearchCriteria": "VIN(s): 3MW5R1J00M8C08095",
"Results": [
{
"ABS": "표준",
"BasePrice": "41250",
"Doors": "4",
"DriveType": "RWD\/Rear-Wheel Drive",
"EngineCylinders": "4",
"EngineHP": "255",
"FuelTypePrimary": "가솔린",
"Make": "BMW",
"MakeID": "452",
"Model": "330i",
"ModelYear": "2021",
"NCSABodyType": "4도어 세단, 하드탑",
"Note": "HD 라디오, 블루투스, 위성 라디오, 보조 오디오 입력, MP3 플레이어",
"Series": "330i",
"TransmissionSpeeds": "8",
"TransmissionStyle": "자동",
}
]
}
다음은 응용 프로그램의 이미지 업로더 섹션입니다. 차량 손상의 이미지를 세 장 업로드할 수 있습니다. 세 장은 임의의 숫자이며 더 많거나 더 적을 수 있습니다. 응용 프로그램은 손상된 차량 이미지와 손상되지 않은 차량 이미지를 구분할 수 있어야 합니다. 이미지는 PNG 또는 JPEG 형식이어야 합니다.
이미지를 업로드하면 응용 프로그램이 이미지를 향상시키려고 시도할 것입니다. 사진들이 초과 노출, 미달 노출 또는 초점이 맞지 않을 수 있습니다. 이 응용 프로그램은 이상적으로 이미지를 자동으로 향상시켜 다음에 만들 벡터 임베딩을 최적화할 것입니다. 업로드된 이미지는 로컬로 저장되어 이미지 데이터베이스에 추가하여 질의 결과를 개선할 수 있습니다.
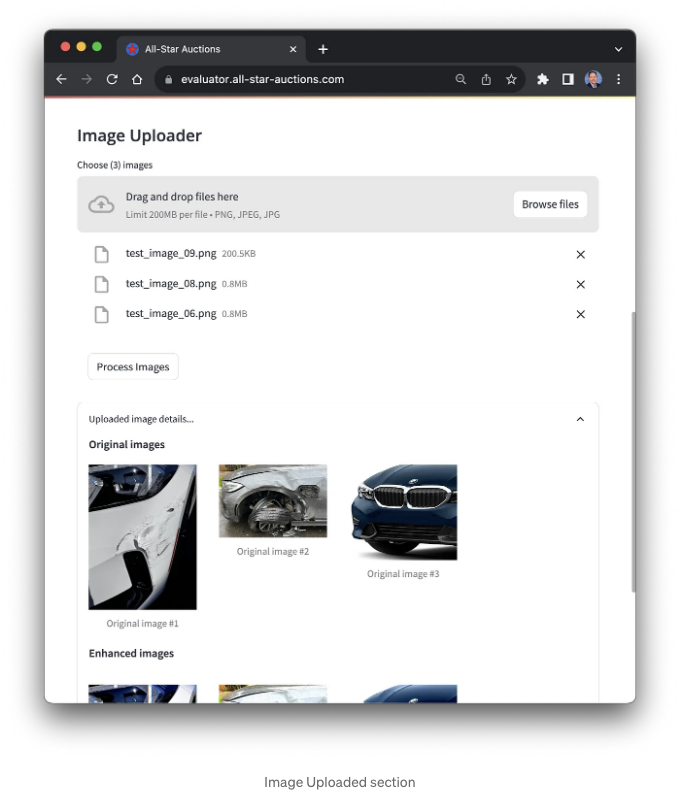
개별 이미지 분석
다음으로, 각 이미지에 대해 업로드되고 향상된 이미지에 대한 밀도가 높은 768차원 벡터 임베딩이 생성되었습니다. 이는 OpenSearch 인덱스를 만드는 데 사용된 동일한 OpenCLIP 사전 훈련 모델을 사용했습니다. 이 애플리케이션이 처음 시작되면, 모델이 호스팅되는 서버로 다운로드되는 동안 지연이 발생할 수 있습니다.
다음으로, 벡터 임베딩을 사용하여 벡터 인덱스에 대한 쿼리를 수행합니다. 우리는 Amazon OpenSearch의 k-최근접 이웃 알고리즘 (k-NN)을 사용하여 벡터 인덱스의 쿼리를 수행할 것이며, 이는 빠른 근사 k-NN 검색을 위해 계층적 근접 그래프 방법을 사용합니다. 상위 10개의 결과가 반환되며, 각각의 세 이미지에 대해 관련성 점수 (_score)에 따라 정렬됩니다.
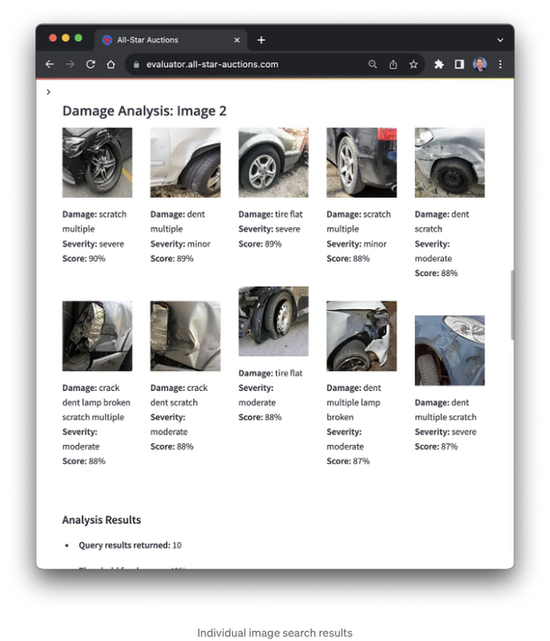
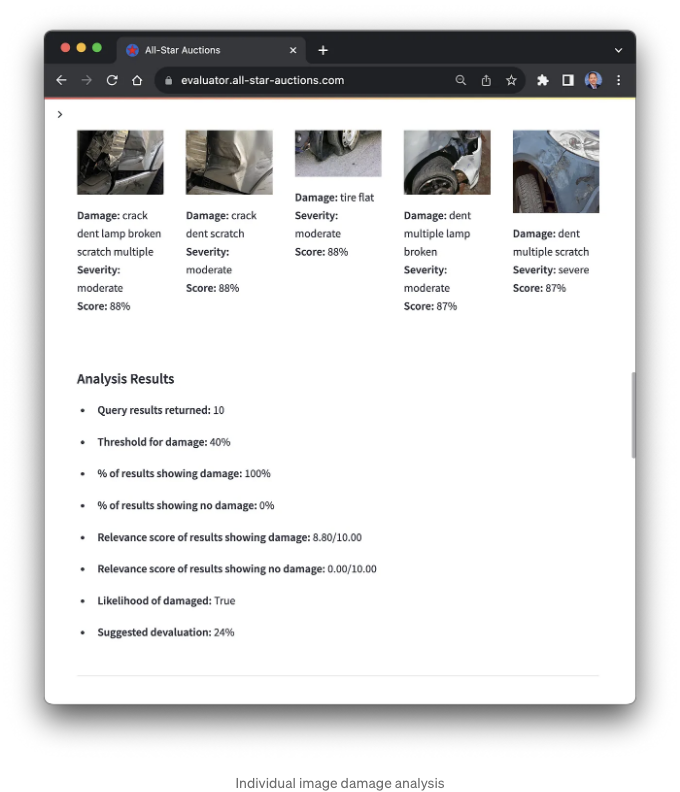
개별 이미지 검색 결과 및 해당 이미지 메타데이터를 사용하여 어플리케이션은 피해 평가를 수행하고 피해의 심각성에 기반한 가치 평가 계산을 개발합니다. 주의할 점은 데모에서 각 이미지에 할당된 심각성 수준은 무작위로 지정되었다는 것입니다. 이상적으로, 각 이미지는 Amazon SageMaker Ground Truth와 같은 서비스를 사용하여 수동으로 레이블이 지정되어야 합니다. 각 심각성 수준에는 권장되는 가치 평가 수준이 있습니다: 없음 (0%), 경미한 (-10%), 중간 (-25%), 심각한 (-40%). 제조 단계의 차량 연도, 제조사, 모델에 따라 이러한 백분율을 조정할 수 있습니다.
최종 분석
세 가지 이미지 분석 결과를 결합하여 애플리케이션은 최종 분석을 생성합니다. 이 최종 분석에는 제3자 API 호출로부터 얻은 차량 데이터에서 추출 및 결합된 데이터 필드가 포함됩니다. 또한 분석에는 가정적인 최종 차량 손상 평가도 포함되어 있습니다. 이는 세 이미지의 개별 평가를 결합한 총합입니다.
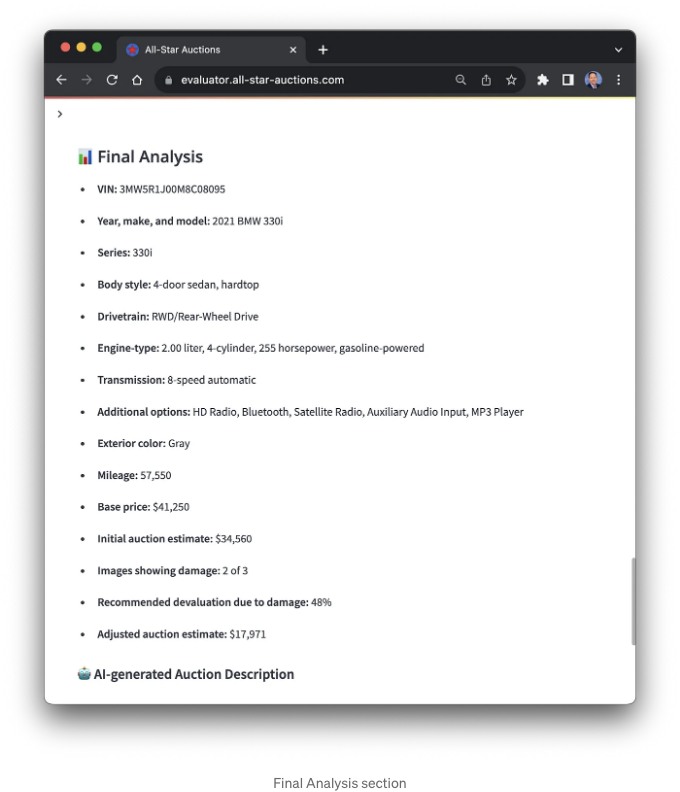
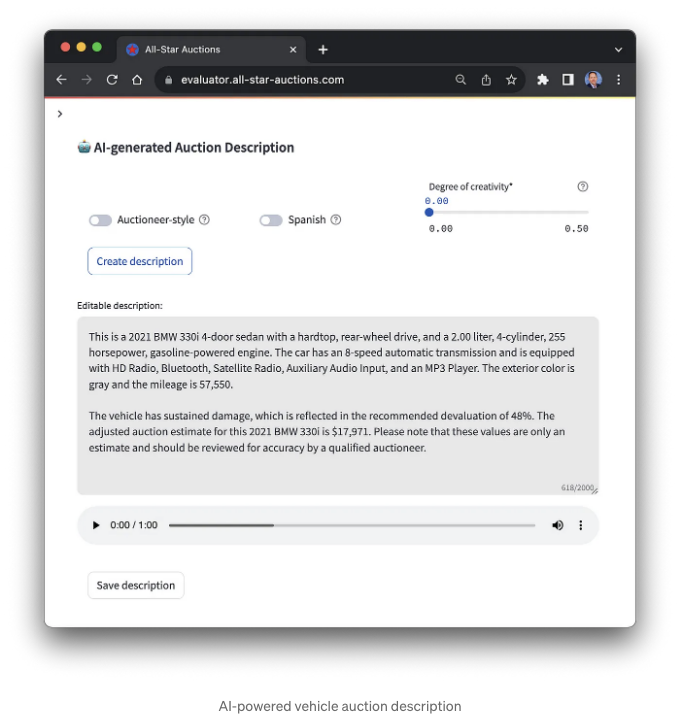
차량 경매 설명
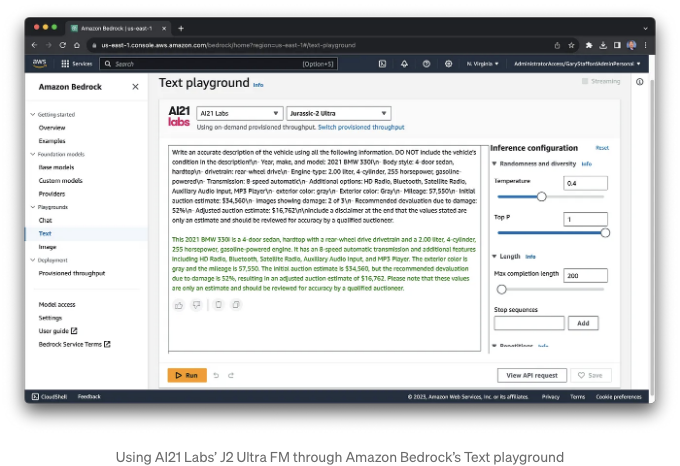
경매 차량을 평가하는 사람이 모두 자세한 차량 설명을 작성하는 데 능숙하지는 않을 수 있습니다. 많은 조직은 제품 설명과 같은 컨텐츠를 제작하기 위한 명확한 스타일 가이드를 갖고 있습니다. 그러나 최종 분석 결과, 응용 프로그램은 제품 설명을 작성할 수 있습니다. 차량 설명을 생성하려면 응용 프로그램이 Amazon Bedrock의 기능을 활용하며, 구체적으로는 AI21 Labs의 J2 Ultra Foundation Model (FM)을 활용합니다. 생성된 설명은 최종 사용자가 완전히 편집할 수 있습니다.
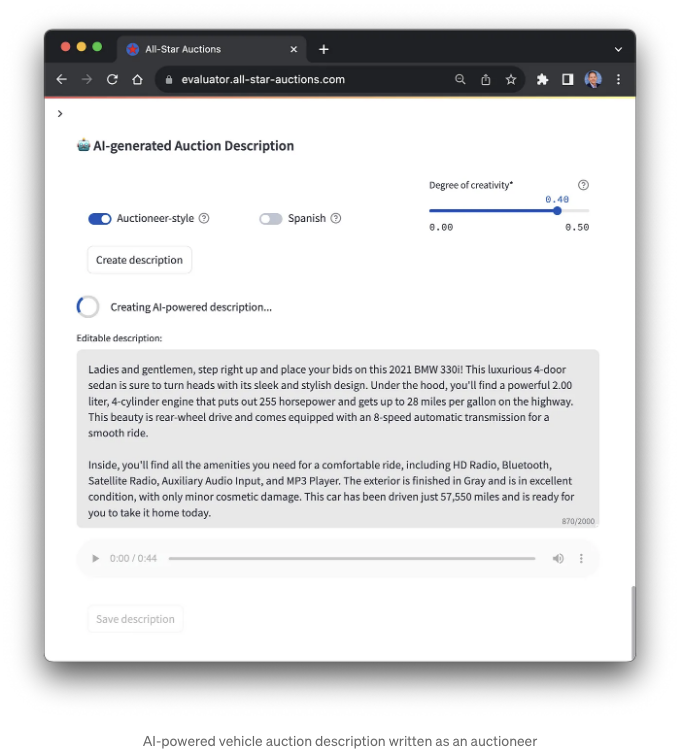
J2 Ultra 모델과 같은 Foundation 모델은 주로 신중하게 제작된 프롬프트 템플릿 및 인문 핵심 학습과 같은 기술과 결합하여 인간과 유사한 페르소나(예: 유명 인사, 전문가 또는 영화 캐릭터)의 스타일로 콘텐츠를 생성합니다. 이 경우, 상세한 차량 설명 외에도 응용 프로그램은 경매인 스타일로 설명을 작성할 수 있습니다.
응용 프로그램에는 "창의성 수준" 슬라이더도 포함되어 있습니다. 이 옵션을 변경하면 콘텐츠가 변합니다. 이 옵션을 변경하는 위험은 모델 온도에 직접적으로 연결되어 설명의 정확도에 영향을 미칩니다. 더 창의적으로 들릴 수 있지만 실제 사실이 아닌 내부 색상과 같은 차량 세부 정보를 포함할 수 있습니다.
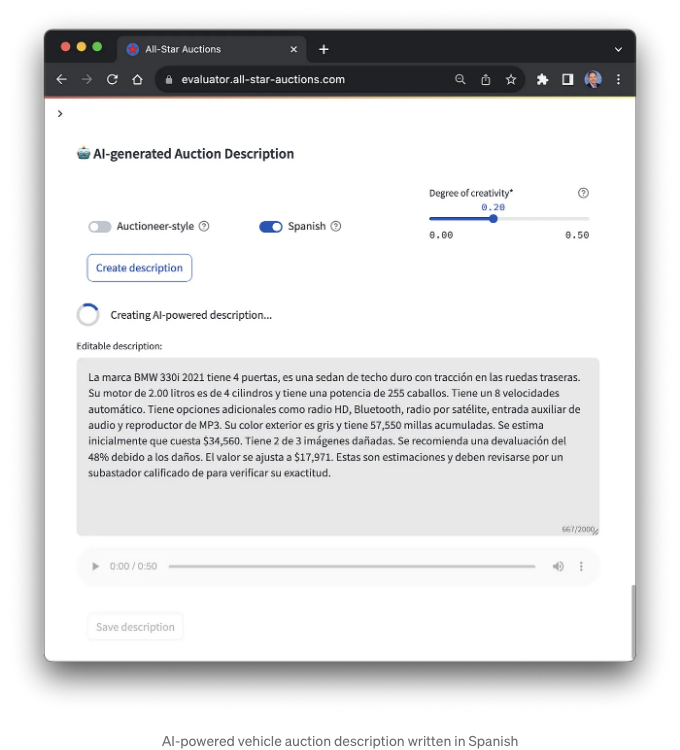
마지막으로, 해당 애플리케이션은 차량 설명을 스페인어로 번역할 수 있습니다. 차량 설명을 번역하는 데 Amazon Translate을 사용할 수도 있었지만, 저희는 J2 Ultra 모델을 사용했습니다. Amazon Translate은 75개 언어 간 번역을 지원하며 우수한 선택지이지만, 영어 외에도 AI21 Lab의 J2 모델은 "스페인어, 프랑스어, 독일어, 포르투갈어, 이탈리아어, 네덜란드어를 비롯한 여러 언어에서 뛰어난 능력을 보여줍니다,"라고 AI21 Labs가 설명했습니다.
텍스트 음성 변환 기능
애플리케이션은 생성된 차량 설명을 텍스트에서 음성으로 변환합니다. 오디오는 애플리케이션 내에서 재생되거나 추가 사용을 위해 다운로드할 수 있습니다. 애플리케이션 내에서 사용할 수 있는 Google Text-to-Speech(gTTS), Amazon Polly, Google Cloud Text-to-Speech AI, Speechify 등의 여러 텍스트 음성 변환 옵션이 있습니다.
차량 설명 저장
AI 기반 차량 피해 평가 애플리케이션의 마지막 기능은 차량 설명을 Amazon DynamoDB와 같은 영구 데이터 저장소에 저장하는 기능입니다. 아래는 VIN을 기반으로 애플리케이션이 저장한 JSON 문서의 축약된 예시입니다.
{
"VIN": "3MW5R1J00M8C08095",
"Year, make, and model": "2021 BMW 330i",
"Series": "330i",
"Body style": "4도어 세단, 하드탑",
"Drivetrain": "RWD/리어 휠 드라이브",
"Engine-type": "2.00 리터, 4기통, 255마력, 가솔린 엔진",
"Transmission": "8단 자동",
"추가 옵션": "HD 라디오, 블루투스, 위성 라디오, 보조 오디오 입력, MP3 플레이어",
"외장 색상": "회색",
"주행 거리": "57,550",
"기본 가격": "$41,250",
"초기 경매 추정가": "$34,560",
"피해를 보여주는 이미지": "3장 중 2장",
"피해로 인한 권장 감가액": "57%",
"조정된 경매 추정가": "$14,688",
"업로드된 이미지": [
"uploaded_images/f1a92ca183a0912d16c2061827e72741.png",
"uploaded_images/f276c9f35c1960b88219553fd85a3a72.png",
"uploaded_images/b2dcd5349efcb7408b3dad012a9ae911.png"
],
"설명": "이 차량은 후륜 구동식 하드탑 4도어 세단이며, 2.00 리터, 4기통, 255마력 가솔린 엔진을 장착한 2021 BMW 330i입니다. 이 차는 8단 자동 변속기로 구동되며 HD 라디오, 블루투스, 위성 라디오, 보조 오디오 입력, MP3 플레이어가 장착되어 있습니다. 외장색은 회색이고 주행 거리는 57,550입니다.\n\n차량에 피해가 있어 57%의 감가액이 발생했습니다. 이 2021 BMW 330i의 조정된 경매 추정가는 $14,688입니다. 이 값들은 추정치이며 정확성을 위해 자격을 갖춘 경매인에 의해 확인되어야 합니다.",
"작성 스타일": "표준",
"언어": "영어",
"온도": 0.0
}
결론
이 게시물에서는 생성 적 AI 기술을 활용하여 완전한 기능을 갖춘 애플리케이션을 만드는 방법을 배웠습니다. 우리는 OpenAI의 CLIP의 오픈 소스 구현인 OpenCLIP과 Vector Engine을 결합하여 밀도 벡터 임베딩을 사용하여 시맨틱 이미지 유사성 검색을 수행하는 방법을 배웠습니다. 마지막으로 AI21 Labs의 J2 기본 모델을 활용하여 Amazon Bedrock을 통해 다중 데이터 소스를 활용하여 정확한 요약 및 고품질 제품 설명을 작성하는 방법을 배웠습니다.

Medium 회원이 아니고 저와 같은 작가들을 지원하고 싶다면 여기에서 가입하십시오: https://garystafford.medium.com/membership
이 블로그는 제 의견을 대표하며 제 고용주인인 Amazon Web Services (AWS)의 의견을 대변하지 않습니다. 모든 제품 이름, 로고 및 브랜드는 각 소유자의 소유물입니다.