
이전 글에서는 자바의 Lambda 표현식에 대해 간단히 언급했습니다. 이번 글에서는 이를 깊이 있게 알아보겠습니다. 먼저, 익숙한 Student 클래스를 예로 들어봅시다. 학생 그룹이 있다고 가정해봅시다:
@Getter
@AllArgsConstructor
public static class Student {
private String name;
private Integer age;
}
List<Student> students = Lists.newArrayList(
new Student("Bob", 18),
new Student("Ted", 17),
new Student("Zeka", 19));
이제 다음과 같은 요구사항이 있습니다:
Java7 및 그 이전 버전에서는 다음과 같이 수행할 수 있습니다:
public List<Student> getTwoOldestStudents(List<Student> students) {
List<Student> result = new ArrayList<>();
// 1. 학생들의 나이를 확인하기 위한 루프를 돌면서, 나이가 18세 이상인 학생들을 필터링합니다.
for (Student student : students) {
if (student.getAge() >= 18) {
result.add(student);
}
}
// 2. 나이가 18세 이상인 학생들의 목록을 나이 순으로 정렬합니다.
result.sort((s1, s2) -> s2.getAge() - s1.getAge());
// 3. 결과 목록의 크기를 확인하고, 2보다 크다면 첫 번째 두 데이터의 sublist를 추출하여 반환합니다.
if (result.size() > 2) {
result = result.subList(0, 2);
}
return result;
}
Java8 및 이후 버전에서는 Stream을 활용하여 아래와 같이 더 우아하게 코드를 작성할 수 있습니다:
public List<Student> getTwoOldestStudentsByStream(List<Student> students) {
return students.stream()
.filter(s -> s.getAge() >= 18)
.sorted((s1, s2) -> s2.getAge() - s1.getAge())
.limit(2)
.collect(Collectors.toList());
}
두 가지 구현 사항의 차이:
기능 관점에서 절차적 코드 구현은 컬렉션 요소, 반복문 반복 및 다양한 논리 판단을 결합하여 너무 많은 세부 사항을 노출합니다. 요구 사항이 변경되면서 미래에 복잡해지면, 절차적 코드는 이해하고 유지하기 어려워질 것입니다.
기능적 솔루션은 코드 세부 사항과 비즈니스 로직을 분리합니다. SQL 문과 비슷하게, "무엇을 해야 하는가"를 표현하며 "어떻게 하는가"를 표현하지 않으므로 프로그래머들은 비즈니스 로직에 더 집중하고 더 깔끔하며 이해하기 쉽고 유지하기 쉬운 코드를 작성할 수 있습니다.
나의 일상 프로젝트 실무 경험을 바탕으로 Stream의 핵심 포인트, 혼란스러운 사용 방법, 전형적인 사용 시나리오 등을 자세히 정리했습니다. Stream에 대해 더 포괄적으로 이해하고 프로젝트 개발에 더 효율적으로 적용할 수 있기를 바랍니다.
Stream에 대한 첫 인사
Java 8에서는 사용자가 List 및 Collection과 같은 데이터 구조를 함수적이고 간단한 방식으로 조작할 수 있도록 하는 Stream 기능을 추가했습니다. 또한, 사용자가 인식하지 못한 상태에서 병렬 컴퓨팅을 구현합니다.
간략히 말하면, 계산을 수행하기 위해 스트림 작업은 스트림 파이프라인으로 구성됩니다. Stream 파이프라인은 다음 세 가지 부분으로 구성됩니다:
- 스트림 생성 (소스 데이터로부터 생성, 배열, 컬렉션, 생성기 함수, I/O 채널 등이 될 수 있음)
- 중간 작업 (이 작업은 필터(Predicate)와 같이 스트림을 다른 스트림으로 변환하는 0개 이상의 작업이 있을 수 있음)
- 최종 작업 (결과를 생성하거나 부작용을 일으키는 작업, count() 또는 forEach(Consumer)와 같은 작업)
아래 다이어그램은 이러한 프로세스를 설명합니다:
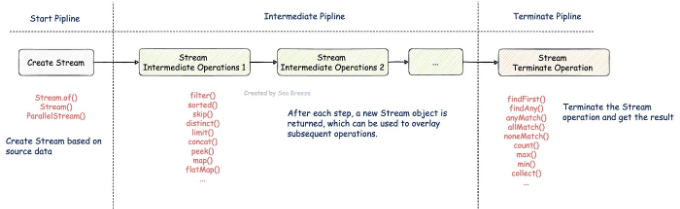
각 Stream 파이프라인 작업 유형에는 여러 API 메서드가 포함되어 있습니다. 먼저 각 API 메서드의 기능을 나열해 봅시다.
1. 파이프라인 시작
기존 배열, 목록, 집합, 맵 및 기타 컬렉션 유형 객체를 기반으로 새로운 Stream을 직접 생성하거나 새로운 Stream을 만드는 데 주로 책임이 있습니다.
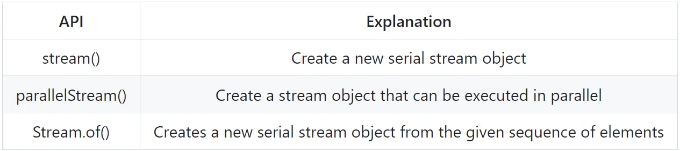
객체 참조의 스트림 인 Stream 외에도 "스트림"으로 지칭되며 여기에 설명된 특성 및 제한 사항을 준수하는 IntStream, LongStream 및 DoubleStream에 대한 기본 특화가 있습니다.
2. 중간 파이프라인
이 단계는 스트림을 처리하고 새로운 Stream 객체를 반환하는 역할을 담당합니다. 중간 파이프라인 작업을 겹칠 수 있습니다.

3. 파이프라인 종료
이름에서 알 수 있듯이 파이프라인 작업을 종료하면 스트림이 끝나고, 마지막으로 어떤 논리적 처리를 수행하거나 필요에 따라 실행 결과 데이터를 반환할 수 있습니다.

Stream API Detailed Usage
1. Create Stream
//Stream.of, IntStream.of...
Stream nameStream = Stream.of("Bob", "Ted", "Zeka");
IntStream ageStream = IntStream.of(18, 17, 19);
//stream, parallelStream
Stream studentStream = students.stream();
Stream studentParallelStream = students.parallelStream();
대부분의 경우에 우리는 기존의 컬렉션 목록을 기반으로 스트림을 생성합니다.
2. 중간 작업
2.1 map
map과 flatMap은 기존 요소를 다른 요소 유형으로 변환하는 데 사용됩니다. 차이점은 다음과 같습니다:
- 맵은 일대일 관계여야 하며, 즉, 각 요소는 새 요소로만 변환될 수 있습니다
- flatMap은 일대다 관계일 수 있습니다. 즉, 각 요소는 하나 이상의 새 요소로 변환될 수 있습니다
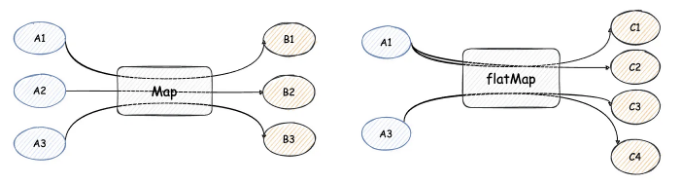
먼저 map 메서드를 살펴보겠습니다. 현재 요구 사항은 다음과 같습니다:
/**
* Use of map: one-to-one
* @param students
* @return
*/
public List<String> objectToString(List<Student> students) {
return students.stream()
.map(Student::getName)
.collect(Collectors.toList());
}
출력:
[Bob, Ted, Zeka]
보시다시피 입력에는 세 명의 학생이 있고 출력에는 세 명의 학생 이름이 있습니다.
2.2 flatMap
이제 요구 사항을 확장해 봅시다.
@Getter
@AllArgsConstructor
public static class Team {
private String type;
private List<Student> students;
}
List<Student> basketballStudents = Lists.newArrayList(
new Student("Bob", 18),
new Student("Ted", 17),
new Student("Zeka", 19));
List<Student> footballStudent = Lists.newArrayList(
new Student("Alan", 19),
new Student("Anne", 21),
new Student("Davis", 21));
Team basketballTeam = new Team("bastetball", basketballStudents);
Team footballTeam = new Team("football", footballStudent);
List<Team> teams = Lists.newArrayList(basketballTeam, footballTeam); //Lists Object depends on the com.google.common.collect
이제 모든 팀의 학생 수를 세어 병합된 목록으로 반환해야 합니다. 이 요구 사항을 어떻게 구현하겠습니까?
다음과 같이 map 메서드를 사용하여 이를 달성하려고 노력해 봅니다:
List<List<Student>> allStudents = teams.stream()
.map(Team::getStudents)
.collect(Collectors.toList());
만약 이렇게 작성한 코드가 실패한다면, 반환된 결과 유형은 ListListStudent이지만, 우리가 원하는 것은 실제 ListStudent`입니다.
그러나 이 문제는 Java7 및 이전 버전에서 쉽게 해결할 수 있습니다. 다음과 같이:
List<Student> allStudents = new ArrayList<>();
for (Team team : teams) {
for (Student student : team.getStudents()) {
allStudents.add(student);
}
}
하지만 두 개의 중첩된 for 루프를 사용하는 이 코드는 우아하지 않습니다. 이 요구 사항에 직면했을 때, flatMap을 활용할 수 있습니다.
List<Student> allStudents = teams.stream()
.flatMap(t -> t.getStudents().stream())
.collect(Collectors.toList());
멋지다고 생각하시나요? 단 한 줄의 코드로 작성되었습니다. flatMap 메서드는 람다 표현식 함수를 인수로 받습니다. 함수의 반환 값은 stream 유형이어야 합니다. flatMap 메서드는 결국 반환된 모든 스트림을 병합하여 새로운 Stream을 생성하지만 map 메서드는 이를 수행할 수 없습니다.
다음 다이어그램은 flatMap의 처리 논리를 명확하게 보여줍니다:
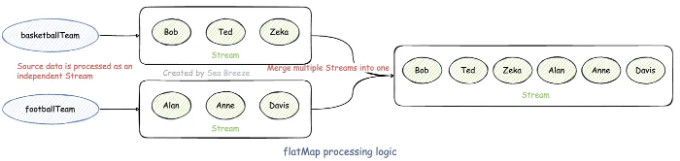
2.3 filter, distinct, sorted, limit
이것들은 자주 사용되는 스트림 중간 작업 메서드들입니다. 종종 함께 사용됩니다. 특정한 기능 설명은 이전 표에서 확인할 수 있습니다. 이번에는 요구사항을 직접 보겠습니다:
List<Integer> topTwoAges = allStudents.stream()
.map(Student::getAge) //[18, 17, 19, 19, 21, 21]
.filter(a -> a >= 18) //[18, 19, 19, 21, 21]
.distinct() //[18, 19, 21]
.sorted((a1, a2) -> a2 - a1) //
.skip(1) //[19, 18]
.limit(2) //[19, 18]
.collect(Collectors.toList());
System.out.println(topTwoAges);
출력:
[19, 18]
참고: skip 메소드 작업 후 요소가 2개만 남아 있기 때문에 limit 단계는 실제로 생략할 수 있습니다.
나는 너가 많은 설명 없이도 이 메소드들의 기능을 분명하게 이해할 수 있을 거라 믿어. 너 스스로 코딩을 해보고 시도해보는 걸 강력 추천해!
2.4 peek, foreach
peek 메서드와 foreach 메서드 모두 요소를 순회하고 하나씩 처리하는 데 사용될 수 있으므로, 비교를 위해 함께 설명하겠습니다. 그러나 peek는 중간 연산 메서드이고, foreach는 최종 연산 메서드임을 명심해주세요.
이전에 설명한대로, 중간 연산은 Stream 파이프라인 중간 처리 단계로만 사용될 수 있습니다. 결과를 얻기 위해 직접 실행할 수 없습니다. 나중에 터미널 연산의 협력으로 실행되어야 합니다. 반환 값이 없는 터미널 메서드로, foreach는 해당 연산을 직접 수행할 수 있습니다.
//peak
System.out.println("------start peek------");
basketballTeam.getStudents().stream().peek(s -> System.out.println("Hello, " + s.getName()));
System.out.println("------end peek------");
System.out.println();
//foreach
System.out.println("------start foreach------");
basketballTeam.getStudents().stream().forEach(s -> System.out.println("Hello, " + s.getName()));
System.out.println("------end foreach------");
출력에서 볼 수 있듯이 peek를 단독으로 호출하면 실행되지 않지만 foreach는 직접 실행할 수 있습니다:
------start peek------
------end peek------
------start foreach------
Hello, Bob
Hello, Ted
Hello, Zeka
------end foreach------
peek 뒤에 터미널 연산을 추가하면 실행할 수 있습니다.
System.out.println("------start peek------");
basketballTeam.getStudents().stream().peek(s -> System.out.println("Hello, " + s.getName())).count();
System.out.println("------end peek------");
//출력
------start peek------
Hello, Bob
Hello, Ted
Hello, Zeka
------end peek------
<div class="content-ad"></div>
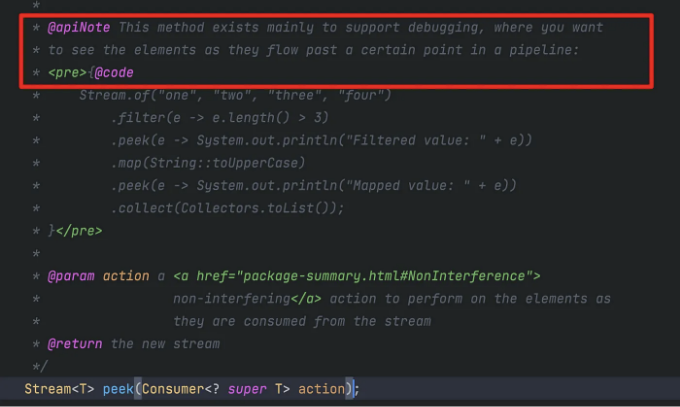
일반적으로 peek 메소드는 자바8 버전에서는 정상적으로 실행되지만, 자바17에서는 자동으로 최적화되어 peek 안의 로직이 실행되지 않을 수 있습니다. 그 이유에 대해서는 JDK17의 공식 API 문서를 참고해보세요.
이러한 이유로 findFirst나 count와 같은 메서드들은 peek 메소드를 결과와 관련이 없는 연산으로 보기 때문에 바로 최적화되어 실행되지 않습니다.
<div class="content-ad"></div>
peek의 소스 코드 주석에서 알 수 있듯이 peek의 권장 사용 시나리오는 디버깅 시나리오입니다. 개발 과정 중에 각 요소의 정보를 출력하여 디버깅 및 문제 위치 분석을 용이하게 할 수 있습니다. 이름 그대로 peek처럼 보이는 것은 실행 중 데이터의 변경 사항을 엿보는 것뿐인 것 같습니다.
## 3. 최종 연산
여기서 최종 연산은 두 가지 범주로 나눕니다.
<div class="content-ad"></div>
한 가지는 단순한 결과를 얻는 것으로, 주로 max, min, count, findAny, findFirst, anyMatch, allMatch 등의 메서드를 포함합니다. 여기서 말하는 단순한 결과란 숫자, 부울 값 또는 Optional 객체 값 등을 의미합니다.
다른 유형은 결과 수집 유형입니다. 대부분의 시나리오는 List, Set 또는 HashMap과 같은 컬렉션 클래스의 결과 객체를 얻는 것이며, 이는 주로 collect 메서드로 구현됩니다.
3.1 단순 결과 유형
(1)max, min
<div class="content-ad"></div>
max() 및 min() 함수는 주로 스트림 처리 후 요소의 최대/최소 값을 반환하는 데 사용됩니다. 반환 결과는 Optional로 래핑됩니다. Optional의 사용에 대해서는 이전 글을 참조해주세요. 람다와 Optional을 결합하면 Java의 null 처리가 더 우아해집니다.
이제 바로 예시를 살펴봅시다.
//max
footballTeam.getStudents().stream()
.map(Student::getAge)
.max(Comparator.comparing(a -> a))
.ifPresent(a -> System.out.println("축구팀의 최대 연령은 " + a + "세입니다."));
//min
footballTeam.getStudents().stream()
.map(Student::getAge)
.min(Comparator.comparing(a -> a))
.ifPresent(a -> System.out.println("축구팀의 최소 연령은 " + a + "세입니다."));
<div class="content-ad"></div>
축구 팀의 최대 연령은 21세
축구 팀의 최소 연령은 19세
`findAny`, `findFirst`
`findAny()`, `findFirst()`는 주로 조건을 충족하는 요소를 찾았을 때 스트림 처리를 종료하는 데 사용됩니다. `findAny()`는 직렬 스트림에서 `findFirst`와 동일하며 병렬 스트림에서 더 효율적으로 동작합니다.
<div class="content-ad"></div>
농구팀에 새로운 학생인 Tom이 19세라고 가정해봅시다.
List<Student> basketballStudents = Lists.newArrayList(
new Student("Bob", 18),
new Student("Ted", 17),
new Student("Zeka", 19),
new Student("Tom", 19));
다음 두 가지 요구 사항의 결과를 살펴봅시다.
- 나이가 19세인 농구팀의 첫 번째 학생의 이름을 반환합니다.
- 19세인 농구팀의 어떤 학생의 이름을 반환합니다.
<div class="content-ad"></div>
//findFirst
basketballStudents.stream()
.filter(s -> s.getAge() == 19)
.findFirst()
.map(Student::getName)
.ifPresent(name -> System.out.println("findFirst: " + name));
//findAny
basketballStudents.stream()
.filter(s -> s.getAge() == 19)
.findAny()
.map(Student::getName)
.ifPresent(name -> System.out.println("findAny: " + name));
출력:
findFirst: Zeka
findAny: Zeka
<div class="content-ad"></div>
System.out.println("농구팀의 학생 수: " + basketballStudents.stream().count());
출력:
<div class="content-ad"></div>
농구팀 학생 수: 4
(4) anyMatch, allMatch, noneMatch
이름에서 알 수 있듯이, 이 세 가지 메서드는 요소가 조건을 충족하는지 여부를 확인하고 불리언 값을 반환하는 데 사용됩니다. 다음 세 예제를 살펴보세요.
- 축구팀에 Alan이라는 학생이 있습니까?
- 축구팀의 모든 학생은 22세 미만입니까?
- 축구팀에 20세를 넘는 학생이 없습니까?
<div class="content-ad"></div>
//anymatch
System.out.println("anymatch: "
+ footballStudent.stream().anyMatch(s -> s.getName().equals("Alan")));
//allmatch
System.out.println("allmatch: "
+ footballStudent.stream().allMatch(s -> s.getAge() < 22));//nonematch
System.out.println("noneMatch: "
+ footballStudent.stream().noneMatch(s -> s.getAge() > 20));
Output:
anymatch: true
allmatch: true
noneMatch: false
<div class="content-ad"></div>
## 3.2 결과 수집 유형
(1)컬렉션 생성
컬렉션 생성은 collect의 가장 일반적인 사용 시나리오로 고려되어야 합니다. List 외에도 Set, Map 등이 생성될 수 있습니다. 예시는 다음과 같습니다:
// 농구팀의 최신 학생 연령 분포를 가져오되 중복은 허용하지 않음
Set<Integer> ageSet = basketballStudents.stream().map(Student::getAge).collect(Collectors.toSet());
System.out.println("set: " + ageSet);
<div class="content-ad"></div>
// 농구팀에 속한 모든 학생들의 이름과 나이 맵 가져오기
Map<String, Integer> nameAndAgeMap = basketballStudents.stream().collect(Collectors.toMap(Student::getName, Student::getAge));
System.out.println("map: " + nameAndAgeMap);
출력:
set: [17, 18, 19]
map: {Ted=17, Tom=19, Bob=18, Zeka=19}
(2) 연결된 문자열 생성하기
컬렉션을 생성하는 데 사용하는 것 외에도 collect는 문자열을 연결하는 데도 사용할 수 있습니다.
예를 들어, 농구팀 학생들의 모든 이름을 얻은 후에는 모든 이름을 “,”로 이어 붙이고 문자열로 반환하기를 원합니다.
System.out.println(basketballStudents.stream().map(Student::getName).collect(Collectors.joining(",")));
결과:
밥, 테드, 제카, 톰
어쩌면 당신은 "String.join()을 사용해서 이 기능을 이룰 수 없나요?"라고 말할지도 모르겠습니다. 이 기능을 달성하기 위해 스트림을 사용할 필요가 없다는 점을 명심해야 합니다. 스트림의 매력은 다른 비즈니스 로직과 결합되어 처리될 수 있다는 것입니다. 이로 인해 코드 로직이 더 자연스럽고 일관성 있게 됩니다. 문자열 연결을 요청하는데 Stream을 사용할 필요가없습니다. 결국, 대가를 칼로 잡아치울 필요는 없습니다!
또한, Collectors.joining()은 접두사와 접미사를 정의하는것을 지원하여 더 강력합니다.
System.out.println(basketballStudents.stream().map(Student::getName).collect(Collectors.joining(",", "(", ")")));
출력:
(Bob, Ted, Zeka)
(3) 통계 결과 생성
실제로는 드물게 사용되지만 collect를 사용하여 숫자 데이터의 합을 생성하는 다른 시나리오도 있습니다. 간단히 살펴보겠습니다.
//평균 계산
System.out.println("평균 나이: "
+ basketballStudents.stream().map(Student::getAge).collect(Collectors.averagingInt(a -> a)));
//요약 통계
IntSummaryStatistics summary = basketballStudents.stream()
.map(Student::getAge)
.collect(Collectors.summarizingInt(a -> a));
System.out.println("요약: " + summary);
위의 예시에서 나이에 대한 수학 연산을 수행하기 위해 collect를 사용하여 결과는 다음과 같습니다:
평균 나이: 18.0
요약: IntSummaryStatistics{count=3, sum=54, min=17, average=18.000000, max=19}
병렬 스트림
메커니즘 설명
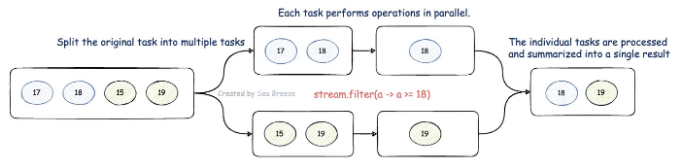
병렬 스트림을 사용하면 컴퓨터 성능을 효과적으로 활용하여 논리 실행 속도를 향상시킬 수 있습니다. 병렬 스트림은 전체 스트림을 여러 조각으로 나누어 각 조각된 스트림에서 병렬로 처리 논리를 실행한 다음 각 조각된 스트림의 실행 결과를 전체 스트림으로 요약합니다.
아래 다이어그램에서 18 이상인 숫자를 필터링하는 방법을 보여줍니다:
findAny() 효율적으로 사용하기
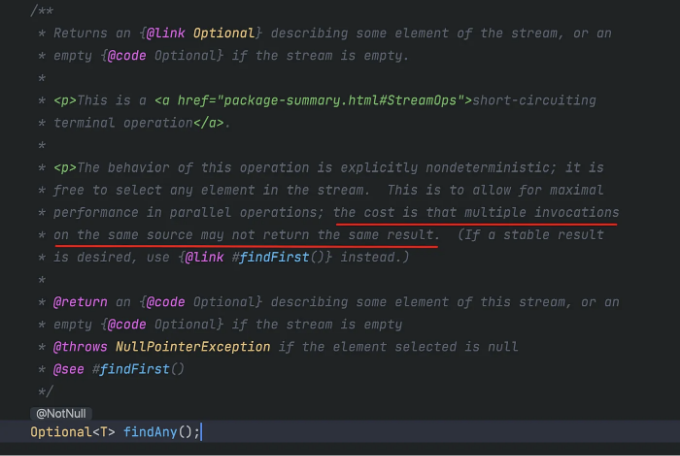
이미 언급한 대로, findAny()는 병렬 스트림에서 더 효율적이며 API 문서에서 이 메서드의 각 실행 결과가 다를 수 있다고 나와 있습니다.
우리는 병렬 스트림을 사용하여 findAny()를 10번 실행하여 Bob, Tom, 및 Zeka의 기준을 충족하는 학생 이름을 찾으려고 시도합니다.
for (int i = 0; i < 10; i++) {
basketballStudents.parallelStream()
.filter(s -> s.getAge() >= 18)
.findAny()
.map(Student::getName)
.ifPresent(name -> System.out.println("병렬 스트림에서 findAny: " + name));
}
출력:
병렬 스트림에서 findAny: Zeka
병렬 스트림에서 findAny: Zeka
병렬 스트림에서 findAny: Tom
병렬 스트림에서 findAny: Zeka
병렬 스트림에서 findAny: Zeka
병렬 스트림에서 findAny: Bob
병렬 스트림에서 findAny: Zeka
병렬 스트림에서 findAny: Zeka
병렬 스트림에서 findAny: Zeka
병렬 스트림에서 findAny: Zeka
이 출력 결과는 findAny()의 불안정성을 확인합니다.
병렬 스트림에 대한 자세한 정보는 나중에 더 분석하고 논의할 예정입니다.
추가 정보
1. 지연 실행
스트림은 게으르다; 소스 데이터의 계산은 터미널 작업이 시작될 때에만 수행되며, 소스 요소는 필요할 때에만 소비된다. 예를 들어, 기사에서 이전에 언급된 peek 메서드가 좋은 예시입니다.
2. 터미널 작업을 두 번 수행하지 마세요
여기에 한 가지 알림을 추가하는 것이 좋습니다. 한 번 스트림이 종료되면 나중에 다른 작업을 수행하는 데 사용할 수 없으며, 그렇지 않으면 오류가 발생합니다. 아래의 예시를 참조하세요:
Stream<Student> studentStream = basketballStudents.stream().filter(s -> s.getAge() == 19);
// 학생 수 계산
System.out.println("학생 수: " + studentStream.count());
// 다시 시도하면 오류가 발생합니다
try {
System.out.println("학생 수: " + studentStream.count());
} catch (Exception e) {
e.printStackTrace();
}
출력:
학생 수: 2
java.lang.IllegalStateException: 스트림이 이미 처리되었거나 닫혔습니다
at java.util.stream.AbstractPipeline.<init>(AbstractPipeline.java:203)
...
요약
본 글은 여러 사례를 통해 Stream을 이용하여 더 우아한 코드를 작성하는 방법을 소개하며, 각 API의 실제 역할을 간단히 소개합니다. 공간 제한으로 인해 해당 글은 collect 및 병렬 스트림의 사용법을 간단히 소개합니다. 해당 주제는 이후의 글에서 자세히 다루도록 하겠습니다.
또한, Stream을 완전히 이해하고 싶다면 단순히 보는 것만으로 부족합니다. 프로젝트에서 연습하는 것도 필요합니다. 궁금한 점이 있다면 언제든지 댓글 섹션에서 토론해 주세요!
소스 코드 주소
Github: https://github.com/junfeng0828/JavaBasic
디렉토리: src/main/java/stream/StreamCase.java
만약 이 글이 도움이 되었다면 👏 박수를 치시고 팔로우해주세요, 감사합니다! ╰(°▽°)╯
나는 Dylan이에요, 앞으로 함께 발전해 나가는 걸 기대하고 있어요. ❤️
제 칼럼에서 더 많은 내용을 읽어보세요.