이미지 태그를 Markdown 형식으로 변경하였습니다.

서문
프로젝트에서 다양한 구현 클래스 또는 서비스 처리 로직들이 다른 유형에 따라 호출되는 시나리오를 경험한 적이 있나요?
예를 들어, 다른 경보 수준에 따라 다른 메시지를 전송해야 할 때가 있습니다. 심각한 수준의 경보의 경우 개발자에게 이메일을 보내어 알림을 전송하고, 재해 수준의 경보의 경우 개발자에게 직접 전화로 알림을 전달해야 합니다.
다른 파서가 필요합니다. 예를 들어, XML 파일은 XML 파서로 처리되고 JSON 파일은 JSON 파서로 처리됩니다.
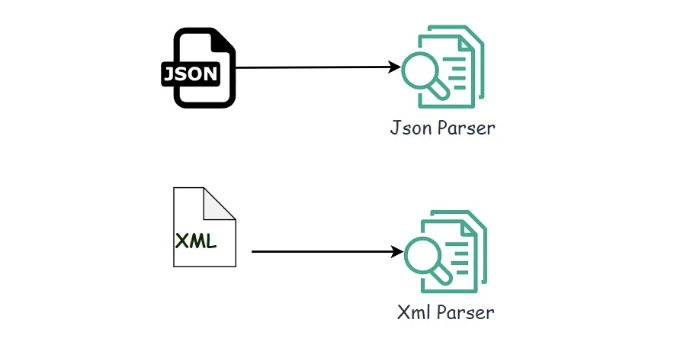
과거에는 이러한 시나리오에서 호출 클라이언트에 if-else 문을 일반적으로 사용했습니다. 예를 들어, 유형이 JSON일 경우 JSON 파서를 사용합니다. 새로운 유형의 파서가 추가되면 호출 클라이언트를 여전히 수정해야합니까? 이는 명백히 매우 불편합니다.
이 기사에서는 Service Locator Pattern을 사용하는 방법을 소개합니다. 이 패턴의 핵심 아이디어는 인터페이스 지향 프로그래밍으로, 서비스 제공자가 서로 강하게 결합된 구현을 제거하고 클라이언트가 특정 구현 클래스에 의존하는 것을 줄여줍니다.
예제
먼저 원래 코드 구현을 살펴봅시다. 여러 소스에서 데이터를 가져와 XML 및 JSON 파일과 같은 다양한 유형의 파일을 구문 분석해야 하는 응용 프로그램이 있다고 가정해 봅시다.
1. 열거형 정의
public enum ContentType {
JSON,
XML
}
2. 파싱 인터페이스 정의
public interface Parser {
Map parse(Reader r);
}
3. 서로 다른 파일 유형을 위한 서로 다른 구현 클래스
@Component
public class XMLParser implements Parser {
@Override
public Map parse(Reader r) {
//...
}
}
@Component
public class JSONParser implements Parser {
@Override
public Map parse(Reader r) {
//...
}
}
4. The client calls different implementations according to different types through switch-case
@Service
public class Client {
private Parser xmlParser, jsonParser;
@Autowired
public Client(Parser xmlParser, Parser jsonParser) {
this.xmlParser = xmlParser;
this.jsonParser = jsonParser;
}
public Map getAll(ContentType contentType) {
//...
switch (contentType) {
case XML:
return xmlParser.parse(reader);
case JSON:
return jsonParser.parse(reader);
//...
}
}
}
대부분의 사람들은 위의 방법으로 구현할 것이고 정상적으로 실행될 것입니다. 하지만 깊게 생각해보면 어떤 문제가 존재할까요?
제품 매니저가 CSV 파일 지원을 요청하면, 클라이언트 코드에 새로운 케이스를 switch-case에 추가하여 수정해야 합니다.
이는 디자인 패턴 중 개방-폐쇄 원칙을 위반합니다. 클라이언트가 다양한 파서와 지나치게 결합돼 있기 때문에 회귀 테스트가 권장됩니다.
그렇다면, 더 나은 방법이 있을까요?
서비스 로케이터 패턴 적용
네, 방금 언급한 Service Locator Pattern을 사용하는 거죠. 이제 최신 코드를 점진적으로 구현해 보겠습니다.
1. 열거형 수정 및 CSV 추가
public enum ContentType {
JSON,
XML,
CSV
}
2. 서비스 로케이터 인터페이스 ParserFactory 정의
표 태그를 마크다운 형식으로 변경해주세요.
It has a method getParser that takes a content type as a parameter and returns the Parser interface.
public interface ParserFactory {
Parser getParser(ContentType contentType);
}
3. Configure ServiceLocatorFactoryBean
In the second step, we configure ServiceLocatorFactoryBean to use ParserFactory as the service locator interface. The interface ParserFactory does not need an implementation class.
@Configuration
public class ParserConfig {
@Bean("parserFactory")
public FactoryBean serviceLocatorFactoryBean() {
ServiceLocatorFactoryBean factoryBean = new ServiceLocatorFactoryBean();
// Set up the service locator interface.
factoryBean.setServiceLocatorInterface(ParserFactory.class);
return factoryBean;
}
}
4. Set the bean name of the parser to be the same as the type name for service location
Set the name of the bean to be consistent with the type.
@Component("CSV")
public class CSVParser implements Parser {
//...
}
@Component("JSON")
public class JSONParser implements Parser {
//...
}
@Component("XML")
public class XMLParser implements Parser {
//...
}
5. 클라이언트는 ParserFactory를 참조하고 특정 Parsers에 대한 종속성을 제거합니다.
이제 클라이언트는 Parser의 구체적인 구현 클래스를 참조할 필요가 없습니다. 타입에 따라 해당 기능을 갖는 Parser 인터페이스를 직접 얻어올 수 있고 switch-case 없이 해당 파싱 메서드를 호출할 수 있습니다.
@Service
public class Client {
private ParserFactory parserFactory;
@Autowired
public Client(ParserFactory parserFactory) {
this.parserFactory = parserFactory;
}
public Map getAll(ContentType contentType) {
// ...
// 특정 타입에 따라 직접 해당 아이템을 얻어오는 핵심 로직
Parser parser = parserFactory.getParser(contentType);
parser.parse(reader);
}
}
하하, 멋지지 않나요😄? 우리는 성공적으로 목표를 달성했습니다. 이제 새로운 타입을 추가할 때에는 확장하고 새로운 파서를 추가하기만 하면 됩니다. 클라이언트를 수정할 필요가 없어졌으며 개방-폐쇄 원칙을 지킬 수 있습니다.
그런데, 직접 타입을 빈 이름으로 사용하는 것이 그렇게 우아하지 않다고 생각한다면, ContentType 열거형을 확장함으로써 다음과 같이 최적화할 수도 있습니다.
public enum ContentType {
JSON(TypeConstants.JSON_PARSER),
XML(TypeConstants.XML_PARSER),
CSV(TypeConstants.CSV_PARSER),
;
private final String parserName;
ContentType(String parserName) {
this.parserName = parserName;
}
@Override
public String toString() {
return this.parserName;
}
public interface TypeConstants {
String CSV_PARSER = "csvParser";
String JSON_PARSER = "jsonParser";
String XML_PARSER = "xmlParser";
}
}
@Component(TypeConstants.CSV_PARSER)
public class CSVParser implements Parser {
//...
}
@Component(TypeConstants.JSON_PARSER)
public class JSONParser implements Parser {
//...
}
@Component(TypeConstants.XML_PARSER)
public class XMLParser implements Parser {
//...
}
서비스 로케이터 패턴의 원리 분석
이전 사례를 통해, 아마도 모두가 서비스 로케이터 패턴을 어떻게 사용하는지 기본적으로 이해하게 되었을 것입니다. 이제 이 패턴의 원리를 깊게 분석해보겠습니다.
서비스 로케이터 패턴은 클라이언트가 특정 구현에 의존하지 않도록 하는 것입니다. Martin Fowler의 기사에서 나온 다음 인용구는 핵심 아이디어를 요약합니다: "서비스 로케이터의 기본 아이디어는 어플리케이션이 필요로 할 수 있는 모든 서비스를 얻는 방법을 알고 있는 객체를 갖는 것입니다. 따라서 이 어플리케이션의 서비스 로케이터는 필요할 때 '서비스'를 반환하는 메서드를 가지고 있을 것입니다."
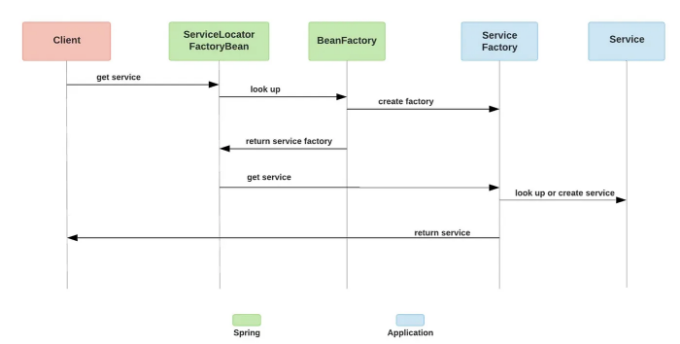
Spring 프레임워크의 ServiceLocatorFactoryBean은 FactoryBean 인터페이스를 구현하고 Service Factory 빈을 생성합니다.
요약
서비스 로케이터 패턴의 도움으로 우리는 Spring의 제어 역전을 효과적으로 확장하는 훌륭한 방법을 구현했습니다. 이 패턴은 의존성 주입이 최적의 해결책을 제공하지 않는 사용 사례를 해결하는 데 도움이 됩니다.
그러나 의존성 주입이 여전히 처음 선택이어야 함을 명확히해야 합니다. 대부분의 경우 요구 사항이 크게 변하지 않는 한, 서비스 로케이터는 의존성 주입을 대체하는 데 사용해서는 안 됩니다.
마지막으로, 이 문서가 도움이 되었다면 👏 크게 박수를 쳐 주시고 팔로우해 주세요. 감사합니다! ╰(°▽°)╯
저는 딜란이라고 합니다. 함께 진행하는 것을 기대하며 ❤️
추천 도서 열입니다.